1. Introduce
Image Segmentation – the problem of assigning labels / labels to pixels is always a hot topic in Computer Vision – Deep learning. In particular, Image Segmentation is divided into 2 branches:
- Semantic segment: assigns each pixel to label as the class to which the object belongs.
- Instance Segment: is a more advanced problem than semantic segment – it is possible to detect and distinguish individual objects in a group of objects of the same class.
If the definition is a bit confusing, you can see the image below: 
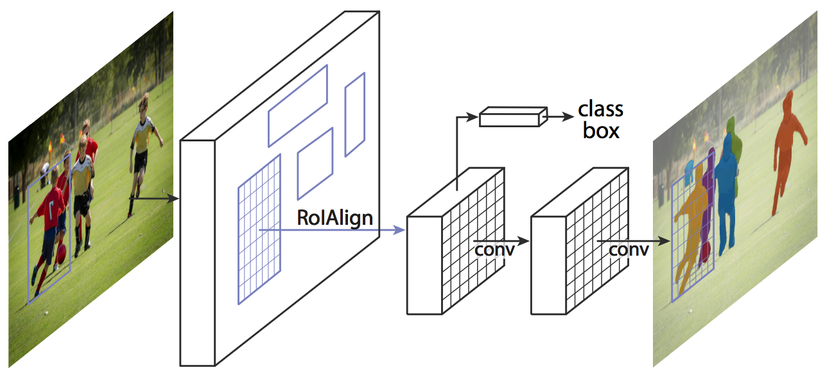
Most of the currently used Instance Segment methods are based on two-stage detectors. For easy distinction, the popular two-stage detector are Fast RCNN , Faster RCNN ; The popular single-stage or one-stage detector is Yolo , SSD , and Restina . A typical example of a two-stage based approach is the RCNN Mask – currently widely used in the community for its high accuracy. Take a look at the image below to better understand the RCNN Mask. Despite its high accuracy, it still has drawbacks:
- 2-stage architecture makes the speed slow
- There are steps in the ROI pool (ROI-align): putting the ROI areas into the model to predict out the mask, the “sequential” processing flow, it is difficult to parallelize calculations to accelerate.
Yolact : To solve the above drawback, the author proposed YOLACT with one-stage architecture, improving speed by dividing the model into 2 sub modules in parallel. Creating instance segments for each object is based on a set of Prototype Masks and a set of coefficients corresponding to each object. It is still difficult to understand, please read the next section to better understand.
2. Yolact: Real-time Instance Segmentation
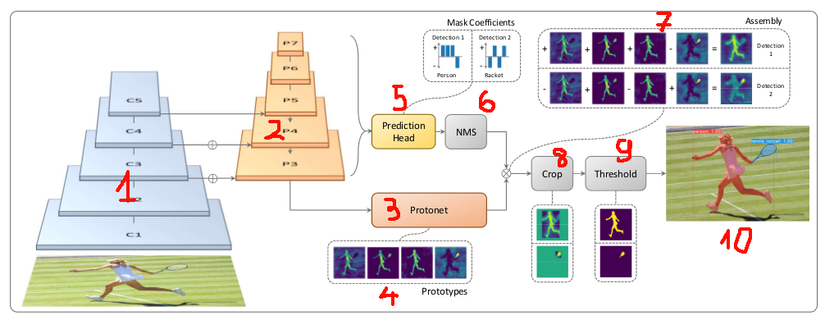
First, look at the image below for an overview of the architecture and thread flow. To easily describe yourself, you have marked each part of the picture.
YOLACT is built on the backbone architecture of Restina: ResNet + FPN (Feature Pyramid Network) – corresponding to 2 “pyramids” sections 1 and 2 in the picture. The Instance Segment then split into two parallel, simple and separate branches: the prototype net branch (part 3) and the prediction head branch (part 5). The division into two branches helps optimize and parallel computation, helping YOLACT achieve Real-time speed, 3-5 times faster than RCNN Mask
The Prototype net is an FCN (Fully Convolution) network, returning the output as Prototype Masks (Part 4). These prototype masks are considered the basic components, when combined with different ratios will produce corresponding masks for each object. To make it easy to understand, think of the prototype mask as a collection of ingredients: spinach, garlic, fish sauce, salt, water … want to stir-fried water spinach – is part 10 of the photo.
Prediction head does the rest: finding the proportion of ingredients for each object. This module will detect the location / bounding box of objects. For each object, the network predicts a set of coefficients . As shown in the figure, we can see that the prediction head identifies two objects, Person, Racket and two sets of coefficients , respectively [ first , first , first , – first ] [1,1,1, -1] [ 1 , 1 , 1 , – 1 ] and [ – first , first – first , first ] [-1,1-1,1] [ – 1 , 1 – 1 , 1 ] .
Bounding boxes from step 5 are passed through Non-maximum suppression (step 6) to eliminate duplicate and low probability Bounding boxes.
To create Mask for 2 Person and Racket objects in step 7, we add Prototype Mask according to the coefficient of each object. Suppose there are 4 prototype masks: M1, M2, M3, M4. So:
- Mask_person = ( first ∗ M first + first ∗ M 2 + first ∗ M 3 – first ∗ M 4 ) (1 * M1 + 1 * M2 + 1 * M3 – 1 * M4) ( 1 ∗ M 1 + 1 ∗ M 2 + 1 ∗ M 3 – 1 ∗ M 4 )
- Mask_racket = ( – first ∗ M first + first ∗ M 2 – first ∗ M 3 + first ∗ M 4 ) (-1 * M1 + 1 * M2 – 1 * M3 + 1 * M4) ( – 1 ∗ M 1 + 1 ∗ M 2 – 1 ∗ M 3 + 1 ∗ M 4 )
So, with the same material as the prototype masks but with different ratios and removing the values outside the bounding box, we have obtained 2 masks for the two person and racket objects in step 8. In step 9, use use image processing algorithms (threshold) to increase the accuracy and type of noise for masks. Combining the masks of each object together we get a mask for the whole image (part 10). And that’s the process flow of Yolact, now that you understand better, I’ll go into the details of each module.
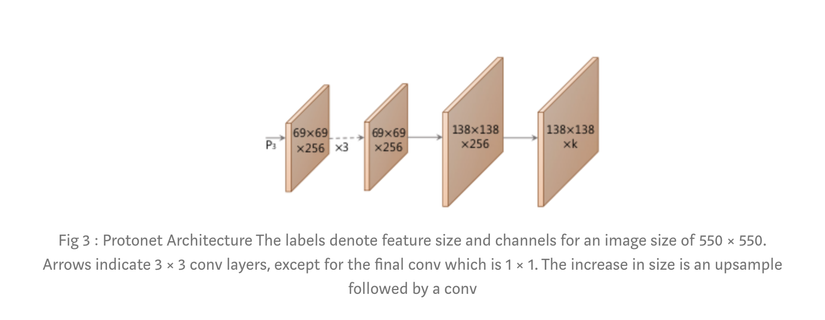
2.1 Prototype Net
Prototype net is a Full-Conv built on FPN-FP3 features of FPN, returning K prototype mask with twice the upsample size.
The number K does not depend on the number of classes, which is optimized and selected after many tests. One point to note is that the bigger the K, the better the output quality, because only the first Prototype Masks affect the Mask of the objects, the remaining Prototype masks do not have much impact, just noise. During the test, the author found that K = 32 gives the best quality.
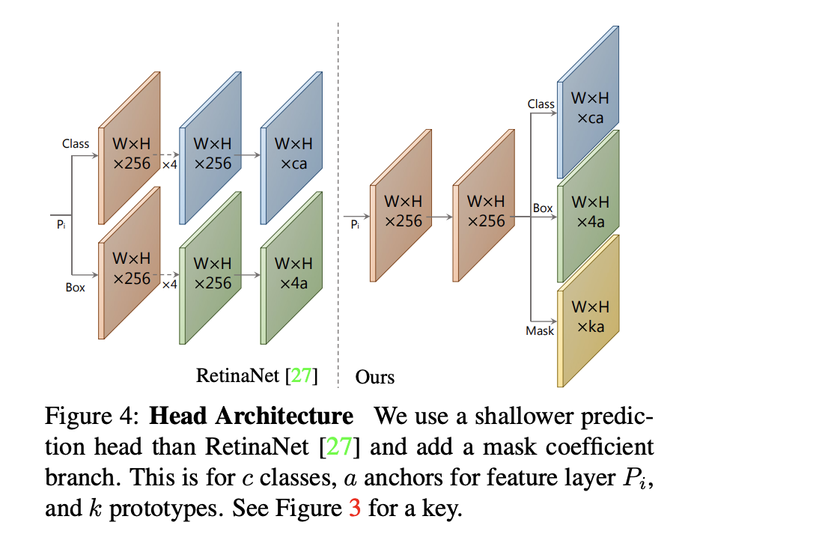
2.2 Prediction head, Mask Coefficients
As mentioned above, prediction head is responsible for detecting objects and the coefficients corresponding to each object. We call this factor set a mask coeficients .
Looking at RestinaNet below, object detectors like Faster-RCNN, RestinaNet often split into 2 predict branches:
- Predict C class confidences – probability distribution for classification
- Predict bounding 4 offset for each anchor box. (At each pixel position, the model must predict a Bbox-offsets corresponding to an Anchor box)
Yolact adds a third branch to predict the K mask coeficients for each anchor box, this branch has the activation function Tanh function, allowing the value of the range. [ – first , first ] [-1, 1] [ – 1 , 1 ] . Thus, instead of predicting only 4 + C numbers at each anchor box, the model must predict 4 + C + K numbers.
2.3 Combining prototype mask and mask coeficients
After undergoing Non-maximum suppression, we have removed the duplicate bboxes, selected the best bboxes and the corresponding mask coeficients. To generate a mask for each object, the algorithm will “linearly combine” K mask prototypes with K mask coeficients (as described above). After passing through the sigmoid function, the Masks will eventually be obtained for each object. 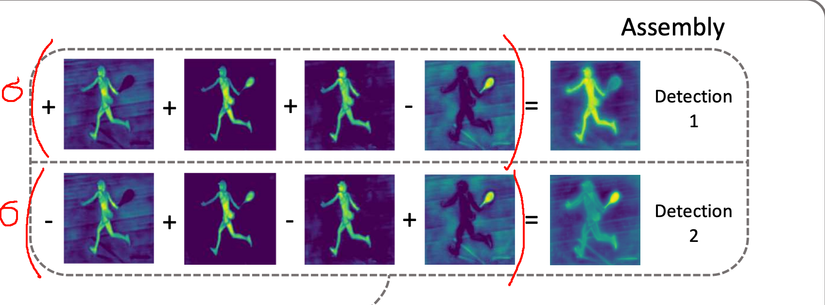
2.4 A few additions
In the paper, the author proposed a method of Fast NMS, ie Fast Non maximum suppression – a method of calculating the matrix type to help increase the speed of NMS 1 significantly. Because it is a bit complicated and difficult to describe, I ask permission not to describe in this article: p
3. Conclusion
So through this article, I have provided you with an overview of Yolact – an effective real-time Instance segment method that is becoming popular.
Github: YOLACT real-time instance segmentation.
Margin :
- I just set up the Vietnam AI Link Sharing Community group to build a sharing community, specializing in exchanging papers, algorithms, author and competition. Here the community will have access to more in-depth knowledge, not being diluted, drifting, lack of missing posts in common groups.
- Ad will not browse basic Q&A articles such as “why is my code not running”, “I want to”, “what should I do” to avoid dilution, and help people easily find quality posts amount. Look forward to everyone’s participation and community building.
- Link: Vietnam AI Link Sharing Community