Continuing a series of distributed system, in this next section we will learn how processes synchronize with each other. Let’s find out together! Let’s go.
Table of contents
- (1) Clock Synchronization (Clock Synchronization)
- (2) Logical clock
- (3) Mutual exclusion (Mutual exclusion)
- (4) Election algorithm
In this part, I will divide into 2 more sections. In this article, I will talk about (1) and (2).
1. Clock Synchronization
- In a centralized system, the system timing is separate.
- When a process wants to know the system time, it simply issues a system call and waits for the kernel to answer.
- If process A asks for time, and immediately after process B asks for the time, the time received by process B will be greater than (or equal to) the time received by A. And never time B gets less than A.
- However, in a distributed system, achieving such time consistency is not easy.
Example of Unix make program
- In Unix, large programs are broken down into multiple source files so that when there is a change in a source file, only that file must be recompiled, not all programs.
- If a program has 100 files, then it is not necessary to fully recompile because any one file changes at a higher speed than any programmer can work with.
- When the programmer changes the source file and runs the make command, that time is marked for all modified source files.
- If file output.c has a time of 2151 and its corresponding object file output.o has a time of 2150, the make command understands that output.c has been changed after output.o has been created. Thus, it is necessary to recompile output.c to produce a new version of output.o .
- Otherwise, if the time of output.o is 2144, output.c is 2143, there is no need to recompile this file.
=> So the make command checks all source files and only calls the compiler to compile the necessary files.
If the system does not reach consensus on time, it will happen as shown in the following diagram:
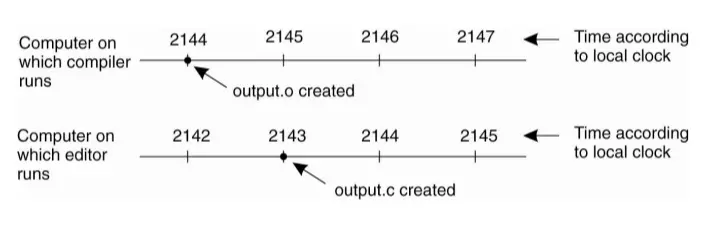
- The output.o file has a time of 2144 and almost immediately after output.c is changed but has a timestamp of 2143 because the clock on that machine is a bit slower. Therefore make will not call the compiler. As a result, the program is compiled mixedly between objects from the old and new source files. This leads to errors in the program that the programmer cannot control or understand.
1.1. Physical Clock
- In some systems (such as real-time systems) the current time is critical. Hence the use of external physical clocks is essential.
- For performance and complexity reasons, developing a system of physical clocks poses two major problems:
- How to synchronize them with real clocks in the world.
- How to synchronize them?
Let us first take a quick look at how time can be measured.
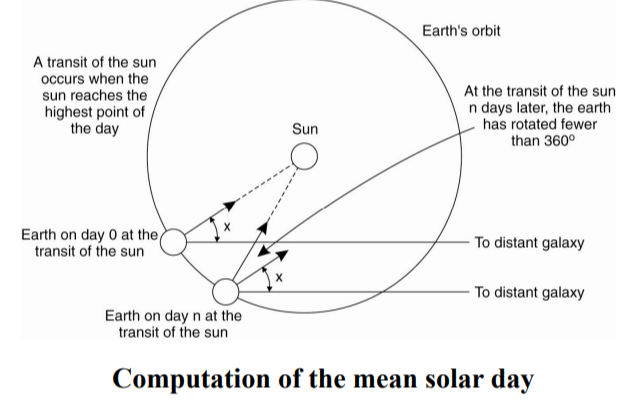
- Initially, time was calculated based on the displacement of the sun (the rotation of the earth’s axis).
- Accordingly, the time between 2 times the sun appears in a row at the same position is called the solar day.
- Each day the sun is divided into 86400 seconds of the sun.
- Look on the picture: in the 40s of the last century, it was discovered that the earth is slowly rotating under the influence of the friction of the tide and the atmosphere. In fact, the duration of a year is almost constant (the time the earth spins once around the sun) but the length of a day has changed. They took the length of an extremely large number of days, averaged and divided that average time into 86400 seconds of the sun.
In 1948, atomic clocks came into being, which made time measurement much more accurate, while at the same time separating the concept of time from the movement of the earth.
- Atomic clocks work on the basis of counting the number of state fluctuations of the atoms of cesium (Cs) 133.
- Every 1 second, Cs atom oscillates 9 192 631 770 times
- The oscillation number of the Cs 133 clock from midnight on 1 January 1958 divided by 9 192 631 770 called TAI to calculate the time
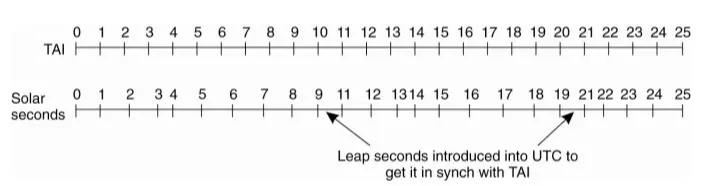
- However, TAI has a problem that every 86400TAIs will be 3ms slower than a sundial.
Therefore, to unify the physical time, the concept of coordinated universal time (UTC) has been introduced.
1.2. Clock synchronization algorithm
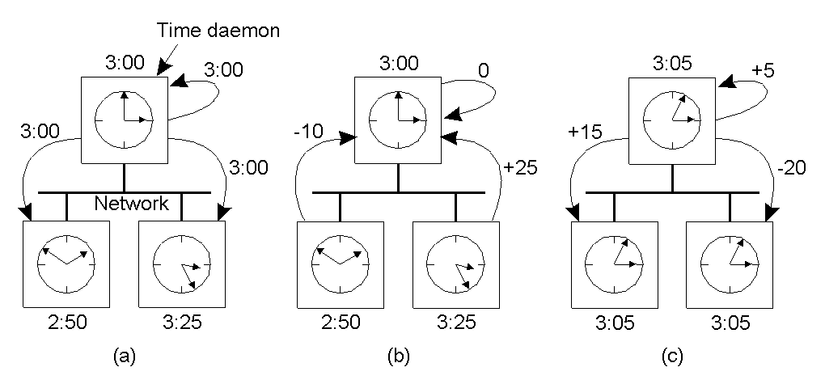
If all computers have WWV Receiver then synchronizing them is easy because they all sync with UTC international standard time. However, when there is no WWV, the synchronization is done by the following synchronization algorithms.
The Cristian algorithm
Suppose in a distributed system there is a time server called a Time server and we will synchronize other machines with this machine as shown below:
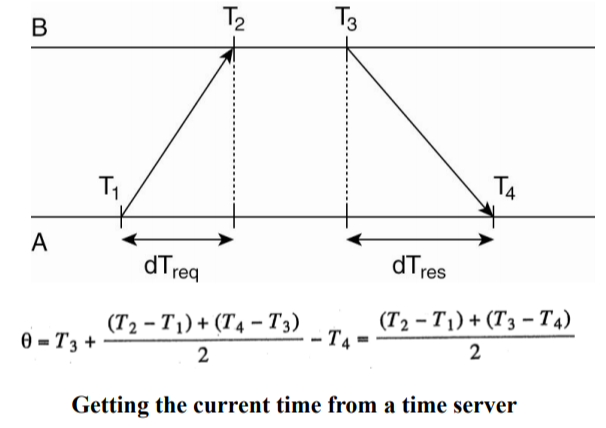
- Client A sends the request to the Time Server and the time it marks A’s local clock as T1.
- Server B receives A’s synchronization request at time T2, and records the receiving time as T2 according to B’s clock.
- By the time T3 follows B’s clock, it sends A a timestamp as T3 so A resets the time to T3 and keeps both T1 and T2 attached.
- But due to the latency of the network to respond, at the time T4 counted according to A’s clock, it received B’s response.
- Now A has information on both T1, T2, T3 and T4.
In the picture you will see a formula. That is the formula for calculating order time θ . This value can be either negative or positive
- If θ> 0: Client time increases to θ seconds.
- If θ <0: Client time is slower than θ seconds.
Assume that transmission delay from A -> B and from B -> A are the same. We will have dTreq = dTres . Inside:
- dTreq is the network delay when sending the request.
- dTres is the network delay when transmitting the response. We have the following formula (the formula is in the picture already):
1 2 3 4 | θ <span class="token operator">=</span> <span class="token constant">T3</span> <span class="token operator">+</span> dTres – <span class="token constant">T4</span> <span class="token operator">=</span> <span class="token constant">T3</span> <span class="token operator">+</span> <span class="token punctuation">(</span> <span class="token punctuation">(</span> <span class="token constant">T2</span> <span class="token operator">-</span> <span class="token constant">T1</span> <span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token punctuation">(</span> <span class="token constant">T4</span> <span class="token operator">-</span> <span class="token constant">T3</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token number">2</span> – <span class="token constant">T4</span> <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token punctuation">(</span> <span class="token constant">T2</span> <span class="token operator">-</span> <span class="token constant">T1</span> <span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token punctuation">(</span> <span class="token constant">T3</span> <span class="token operator">-</span> <span class="token constant">T4</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token operator">/</span> <span class="token number">2</span> |
Inside
1 2 3 | <span class="token constant">T2</span> <span class="token operator">=</span> <span class="token constant">T1</span> <span class="token operator">+</span> θ <span class="token operator">+</span> dTreq <span class="token constant">T4</span> <span class="token operator">=</span> <span class="token constant">T3</span> <span class="token operator">-</span> θ <span class="token operator">+</span> dTres |
The Berkeley Algorithm
- Server proactively let other machines know its standard timing is Cutc
- Then request information about the client’s timing.
- The client responds to the time difference between it and the server.
- The server calculates the amount of time that the client compares to the standard server time at that moment and sends the clients a way to adjust the time accordingly.
The average algorithm uses the wireless network
- Divide time into fixed sync intervals.
- Time interval I will start from point (To + iR) and run until To + (i + 1) R with:
- To is a predetermined time
- R is a system variable.
- At the start of each sync, all of the network’s hosts broadcast their time.
- After broadcasting it begins to collect the time that other hosts send in period S.
- Then remove the maximum and minimum values and calculate the average of the remaining time values.
2. Logical Clock
The concept of a logical clock was born in the case where the processes do not necessarily match in real time, but only in time.
2.1. Lamport timestamp
Consider the definition of “first come” relationship (→)
When there is a → b:
- a occurs before b then all processes in the distributed system agree that event a occurs first and then b.
- Where a and b are two events of the same process.
- If a occurs before b then a → b is true.
- If a is a message event sent by some process and b is the event that the message was received by another process then the relation a → b is true.
- Previous relation is bridging: a → b, b → c then a → c.
Time Stamps
Update Ci counter for process Pi
- (1) Before executing event Pi executes Ci ← Ci + 1
- (2) When process Pi sends a message m to Pj, it sets timestamp ts (m) to Ci tape after it was executed in the previous step.
- (3) On receiving the message m, process Pj adjusts its own local counter to Cj ← max {Cj, ts (m)}. It then executes step (1) and sends the message to the application.
2.2. Vector clocks
- The algorithm provides a vetor clocks VC (a) assigned to the event a whose attribute is
- if VC (a) <VC (b) then event a is the cause of b.
- In the vector clock each process Pi stores a VCi with a value of N (different processes have different N).
- VCi [i] is the number of events that happened at Pi
- If VCi [j] = k, then Pi knows that k events have occurred at Pj
- The requirement is that every time a new event occurs in process Pi increases the VCi [i] and ensures this vector is sent with the same message along the way.
- From there, the receiver will know how many events happened at Pi.
- More importantly, the receiver will indicate how many events in other processes occurred before Pi sent the m message.
How to update the vector:
- Set VCi [j] = 0 for all j, i
- The event that happened in Pi caused the increase in VCi [i]
- Pi attaches a timestamp ts (m) = VCi to every message sent
- When Pi multiplies a message with ts (m) it sets VCi [j] = Max {Vi [j], ts (m) [j]} and increases VCi [i]
Here I end part 1 here. In the next part, I will continue with sections (3) and (4) in the table of contents!
Thanks for reading
References : Lecture on Distributed System – Hanoi University of Science and Technology