Continuing Part 1 – Distributed overview overview , in this next article, I would like to introduce Distributed System Architecture . Let’s find out together!
Architectural concept
We already know distributed systems are always divided into small components so they have a rather complex organization. To solve that complex problem the systems need to be well organized and the best way is to distinguish between logical organization and physical implementation.
- Logical organization is the software components that make up the system => Software architecture tells us how software components organize and interact with each other.
- The physical implementation is the placement of those components into a real computer and the final instance of a software architecture. After finishing putting the components together is called the system architecture
Architectural types
Architectural type is the way in which the components are connected, the data exchanged between the components and those components are configured together to make a system.
1. Stratified architecture
- In HPT the functions on the system are broken down into subfunctions.
- Subfunctions are performed by software modules, the software entities on different systems interact with each other.
- Since then, different software modules on the same system coordinate and interact with each other to perform common functions. => to simplify the system, it is necessary to minimize the linkage between the modules => layered architecture
- The basic idea of layered architecture:
- The components are organized in a layered style.
- A component on the N layer is allowed to call other elements downstairs N-1.
- This model is applied a lot in the online community

- Advantages of layered architecture:
- For complex systems => apply the divide and conquer principle
- Allows to clearly define the duties of each department and the relationship between them
- Allows for easy system maintenance and upgrades, changing inside one part without altering others
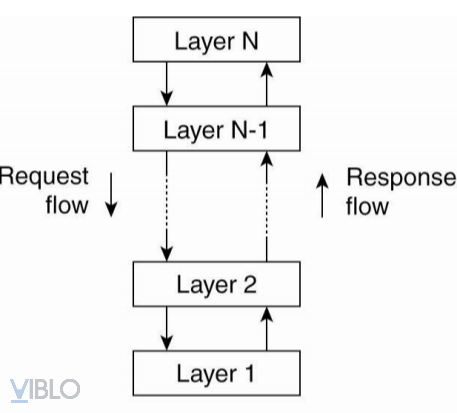
With the principle of layering as above, the entities in the network must unify the standard protocol corresponding to each layer in order to exchange information with each other.
A protocol is a collection of all rules and conventions to ensure that computers on the network can communicate with each other.
- Types of protocols:
- Connection oriented protocol : is the protocol before conducting data information exchange, the entity must set up a transmission channel, then cancel the transmission channel after the end of the exchange => make it possible for 2 entities to check transmission control (TCP protocol)
- Protocol no connection : no need to set up a transmission channel, data is usually in datagram form (UDP protocol)
- Trusted protocol : data is transmitted sequentially, if receiving successfully, the receiver must send acknowledgment
- Untrusted protocol : opposite of trust protocol
2. Object oriented architecture
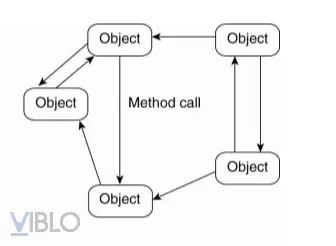
- Components are objects.
- Connections are procedure calls
=> The objects are connected through the procedure call mechanism
- Objects usually come in two types:
- Object Client
- Object server
=> This architecture has many similarities with Client – Server architecture
Here the connection between objects is loose connection, allowing for heterogeneous objects. They can differ in properties and methods and have the ability to exchange information with each other
- Advantages of object oriented architecture
- Mapping on objects in the real world => easy to understand
- Easy to maintain and upgrade
- Polymorphism & Abstraction
- Error control
- Extends functionality without impacting the system
- Easy to test with encapsulation
- Reduce development time and costs
- Disadvantages :
- Difficulty in defining classes and objects
- Large program size
- Programs run slower (compared to procedure programs)
- Not suitable for all problems
3. Event-driven architecture
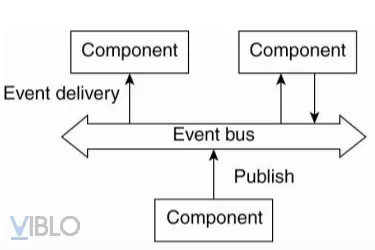
- System components exchange information with each other through events
- Events contain information to exchange and can trigger operations in processes
- Can operate as point-point model or event broadcast axis model
4. Data-oriented architecture
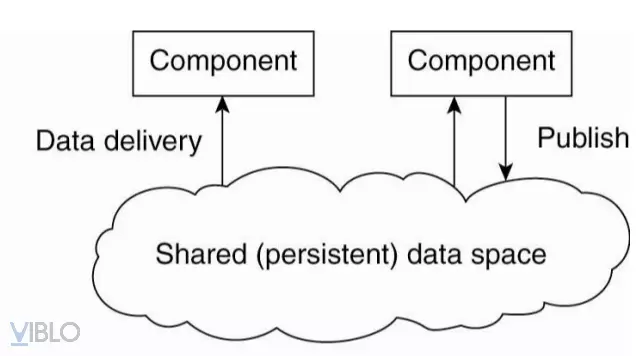
- The essence of data-oriented architecture is that processes are designed to be discrete in time
- Components exchanging information via common datastore => 2 unnecessary processes running at the same time of information exchange
- To send and receive information from a shared data warehouse processes can use database queries instead of references
system architecture
1. Centralized architecture
Client-server architecture
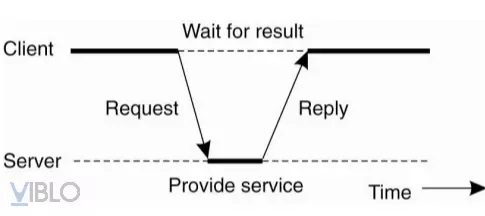
- Client : is the process of y / c service from the server side by sending y / c, waiting for the server to respond, receiving the result and showing it to the user.
- Server : is the process of deploying a specific service. Its job is to listen, receive requests, process, answer
- The interaction between client and server can be either connection oriented or connectionless
- With this type of architecture, there will be some problems as follows:
- Server registration: this is the mechanism that servers have to implement to help clients know the address to send y / c (such as DNS, directory service).
- Either way or not repeat y / c: This problem arises when the client does not receive acknowledgment from the server side. The client will not know if the server has not received the y / c yet or the acknowledgment message is lost on the transmission line. Now, depending on the nature of the service or application, whether the client sends back y / c or not => allowing iteration or not depends on the nature of the service in use.
- Should use state memory
In some cases we will not be able to clearly distinguish which is the client-server process, for example a server in a distributed data system may act as a client when y / c of another server’s data => instead of client-server differentiation will be made of layers
Application stratification
The client-server application is divided into 3 main layers:
- User Interface Layer: the task is to directly manage the user interface. This layer provides programs that allow the end user to interact with different applications and programs because of its complexity.
- Business layer : contains the main processing functions of the application
- Data layer : is responsible for storing and maintaining data for applications to use, even if there is no application to use, it must be stored for the next use.
Search application stratification example
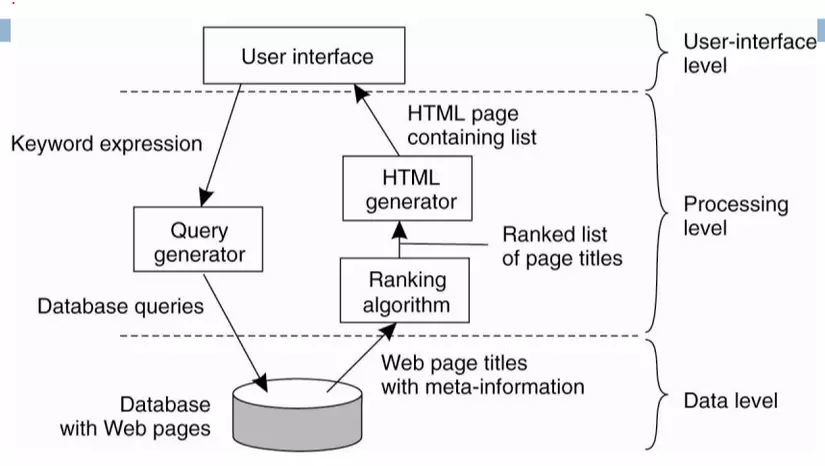
- At the user interface layer, the user uses the web interface of a search page (google) and types in keywords to search
- At the business layer, the keyword interpretations that the user has typed will be sent down to a module that generates database queries from the keyword strings the user typed.
- These database queries will be sent down to the bottom layer of the data layer.
- Data layer based on those queries will get the data to find.
- This data will be sent back to the business layer. At the business layer, there will be 1 specialized module for the algorithm to rearrange the rankings of those search results.
- The sorted list is sent to a dedicated HTML page generation module.
- The results are then posted to the UI layer. The user will now see the search page
Multi-storey architecture
A simpler way to organize is to divide it into two types of client and server computers. Which machine owns which program will determine the trend of the model, also known as 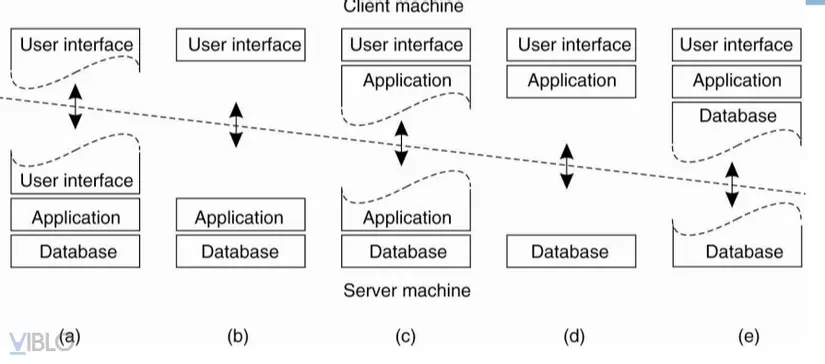
- Figure a: Leaving part of the interface dependency on the client machine, the rest on the server machine => this architectural model gives remote control over the representation of data on the client machine.
- Figure b: Dividing the application into a graphical interface to communicate with the rest on the server machine by application protocols => this model, the client software only represents the application interface
- Figure c: 1 part of the application layer is located on the client machine, the rest is on the server machine => applicable model in case the user needs to fill out a form and the application part is above The client will y / c the user to enter the complete and correct code before it will be processed at the server.
- Figures d and e: 2 common patterns where a server machine only manages databases, it occurs when a client computer connects over a computer network to a distributed file system or a database. Most applications run on the client machine, but operations with the database run on the server machine.
- In Figure e, the client machine also has a piece of data information. This is a model that uses data buffers.
Thus, regarding centralized architecture, we have the concept of multitiers client-server architectures . It is the result of splitting an application into parts such as interfaces, processing elements, and data elements. These different sections are directly related to the logic organization of the application. In many cases, distributed processing can be understood as organizing the client-server application as a multipart architecture. We call it the vertical distribution (vertical distribution).
2. Architecture is not centralized
Related to this issue is the concept of horizontal distribution (horizontal distribution). With this distributed form, a client or server can be physically divided into equal parts, each operating on the part that it is shared from a complete data set. This is a load balancing mechanism (duplicates a server function onto multiple machines).
A prime example of a decentralized architecture is the peer to peer network (P2P). P2P is divided into 2 main types: structured and unstructured P2P.
P2P is structured
Before talking about structured P2P we must know what an Overlay network is?
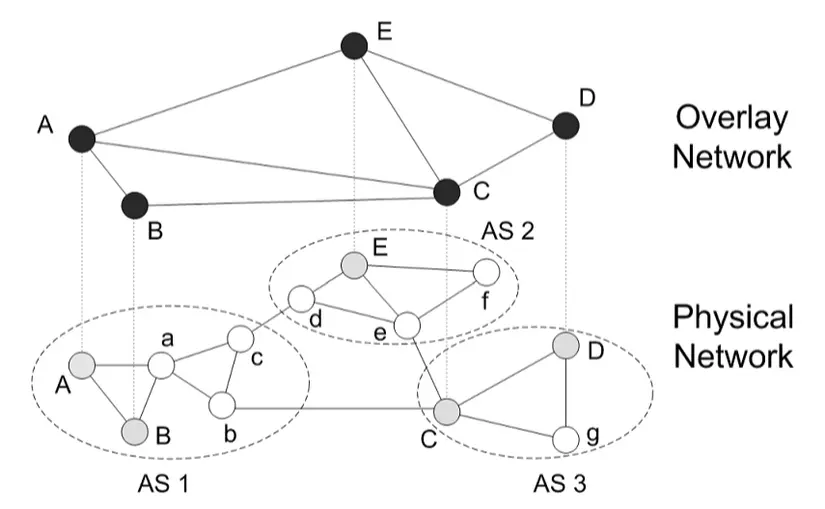
- An Overlay network is a network where nodes are made up of processes and their connections represent connection channels (such as TCP connections), which are built on top of a real physical network.
In structured P2P architecture, Overlay networks are built based on a defined procedure. The most commonly used procedure is the Distributed Hash Table (DHT) model.
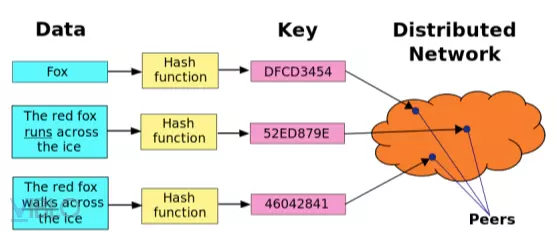
- The distributed hashing system is a layer of decentralized HPT that provides a search service similar to hash tables using key and value pairs.
- Using the distributed hash table model, when trying to store data the name of the file has been hashed using the SHA-1 algorithm to generate a 160bit key called K. Then use the put function (K, data). The pair (k, data) is transmitted in that Overlay network to the node responsible for locking K so. And it will store K and data again.
- To get the data information, we do a hash of the file name again to get the key K and call the get (K) command. At that time, the message will propagate in the Overlay network to reach the node responsible for the key K.
- Building an Overlay network requires key partitioning. This operation is used to identify the nodes responsible for the keys, and the distance between the nodes must be less than a certain deta.
P2P has no structure
- People build on random algorithms to build overlay networks.
- Each node has a list of neighbor nodes.
- Data is sent to the network at random => when you want to find some data, you need to do a flooding.
3. Mixed architecture
- Edge-server system
- Collaborative distributed system
Edge server system
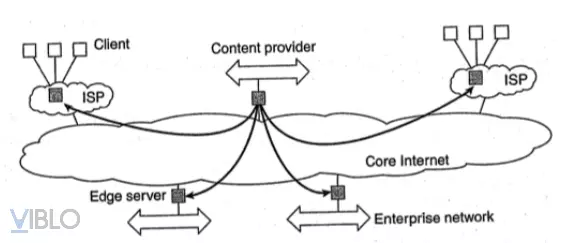
- Servers are deployed at the edge of networks.
- The boundary is determined by the boundary between the enterprise network and the Internet, provided by the network service provider (ISP).
- End users who want to access the Internet must connect through the edge server.
- The main idea of this system model:
- The data from content providers will be distributed to edge servers.
- The edge servers will distribute that content to customers. The edge servers here can be the network service providers themselves.
- The primary purpose of using edge servers is to deliver content to clients without having to directly connect to the content provider.
Collaborative distributed system
When building a mixed architecture system between centralized and decentralized, we need to consider how often the client-server model is used.
- An example of a hybrid architecture system design is when a node will use a centralized model to join the system with the control of registration and server login.
- Then that node immediately uses the completely decentralized model to exchange information and interact with other nodes in the completely peer-to-peer network.
To summarize, all of the above architectural models have the basic commonality, that they are all made up of a process capable of communicating with each other by sending messages over a computer network. They all have y / c designed to achieve the characteristics of process reliability and network performance. Ensuring the safety of resources for the system.
In the next part, I will introduce Process and Flow Management . Hope everyone welcome to read
Thanks for reading
References: Lecture of Executive Claims – Career-oriented teaching