- I have just passed a fairly long time, to research and build a lab about building rabbitmq cluster. Here is the whole “diary” I note.
1. Introduction
- My writing will not rewrite the basic concepts.
- This article I think is probably suitable for:
- Who wants to learn quickly the construction of rabbitmq cluster, to get an overview, before you want to study (or configure) more deeply.
- Understand the thought, the problems of operating a Message Queue cluster in general. But I think I could become a background to reach out to another system.
- Knowledge base to understand the article:
- A little bit about Rabbitmq
- A little bit about Docker
- A little bit about Networking
- The information is in the article:
- A little theory about Quorum Queue in RabbitMQ
- The reason of birth
- Compare with Mirror Queue (support in the old version)
- Constructing the cluster system
- Design diagram
- Step by step deployment
- Lab some scenarios when the cluster has a problem
- There are nodes down / reUp
- Network Partitions – Split Brain
- A little theory about Quorum Queue in RabbitMQ
2. Quorum Queue
2.1 A few main ideas
- Rabbitmq from version 3.8.0 onwards, there is a major change in feature support. In particular there is Quorum Queue. What was born to solve the problems of Mirror Queue in previous versions was encountered. (Quorum Queue is a “type”,
không liên quanto Exchange Type: Direct, Topic, Fangout) - When creating Quorum Queue, there is no
Durabilityoption like Classic Queue. (When the node fails, or the problem restarts, thequeuewill be “reloaded” at startup, ifnon-durableit will be lost) - When using Quorum Queue, there is no need to upgrade the client. => backward compatible. The Quorum Queue setup is located at the server nodes. Client not participating.
- When a node fails, then returns, it only synchronizes new messages. Without having to sync again from the beginning. And the sync of these new messages is not blocked.
- If a broker fails to lose data, all the messge on that broker will be lost forever. When the broker is online again, it is not possible to synchronize data from the leader from the beginning.
- When building a cluster to deploy the Quorum Queue, definitions like a master node, non-slave nodes, or replicates will no longer be true.
2.2 Compare Quorum Queue vs Mirror Queue
- Mirror Queue => I think it has Depreciation (subjective view). Formerly Replicated queue
- Quorum queue data messages forever on disk. As for Mirror Queue, the options for Durable Queue and Persistent Message will have different calculations:
- Non-durable Queue + Non-Persistent message = lost Queue + lost Message (after Broker restart)
- Durable queue + Non-Persistent message = And Queue + lost Message
- Durable queue + Persistent message = Remaining Queue + Remaining Message
- Mirrored queue + Persistent message = Remaining Queue + Remaining Message
- When there is 1 faulty node, and then return to normal. With Mirror Queue, it will block the whole cluster. Because it needs to resynchronize the entire message during the incident. In contrast to Quorum Queue, it does not block. It only syncs new messages.
- When having Network Partition problems. (networks of nodes are not connected to each other). With Mirror Queue, there will be
split-brainsituation. (1 queue / cluster> 1 master). With Quorum Queue, provide policiesautoheal,pause_minority,pause_if_all_down, so that the administrator can configure the handling direction. - With Mirror Queue, the master node will receive all read / write requests. The mirror nodes will receive all messages from the master node and write to the disk. The mirror nodes are not responsible for offloading “read” / “write” to the master node. It just mirrors the message to serve the HA. With Quorum Queue, Queue A can master on Node 1. But Queue B can master on Node 1.
3. Building rabbitmq cluster system
3.1 Design diagram
- Write a big, simple diagram:

- I use 3 nodes. (should choose an odd number. To facilitate the algorithm to elect the leader)
- These 3 nodes I installed Docker Swarm, with the leader is Node 1. And use the
docker stackto deploy the cluster. (You absolutely can not use the Docker Swarm, but only the regular Docker container will do. In the step-by-step steps I will explain in detail so you can customize). - Should set up the number of nodes (broker) is odd. For example 3,5,7 to facilitate the leader election algorithm
- Deployment environment:
- Nodes running Ubuntu Server 18.04
- The node installs Docker
- Node1 runs rabbitMq, whose container hostname is
rabbitmq1. Similar to node2, node3 israbbitmq2,rabbitmq3.
3.2 Step by step
first). Prepare
- My lab uses 3 AWS EC2 instances. (for strong network, fast machine, don’t have to wait). You can replace it with any server, use docker-machine, or virtualize vmware. Not so important. As long as 3 nodes are connected to each other, and there is internet to download is.
- Hostname information (in the docker-stack deployment step to be used).
- Node1 = ip-172-31-11-205
- Node2 = ip-172-31-3-230
- Node3 = ip-172-31-1-3
- (Get this information by ssh into the server and type command
hostname.)
- Hostname information (in the docker-stack deployment step to be used).
- Install Docker Engineer
- Google how to install or run this script I wrote for fast also
12<span class="token function">wget</span> -O - https://raw.githubusercontent.com/tungtv202/MyNote/master/Docker/docker_install.sh <span class="token operator">|</span> <span class="token function">bash</span> - Install Docker Swarm on 3 nodes.
- Select node1 as leader.
12docker swarm init --advertise-addr <span class="token operator">=</span> <span class="token number">172.31</span> .11.205- Node2 and Node3 join cluster
12docker swarm <span class="token function">join</span> --token SWMTKN-1-5xv7z2ijle1dhivalkl5cnwhoadp6h8ae0p7bs5tmanvkpbi3l-5ib6sjrd3w0wdhfsnt8ga7ybd <span class="token number">172.31</span> .11.205:2377- Result
- For more details, please refer to the tutorial of Mr. xuanthulab.net

2). Dockerfile
- Dockerfile123456789<span class="token keyword">FROM</span> rabbitmq <span class="token punctuation">:</span> 3 <span class="token punctuation">-</span> management<span class="token keyword">COPY</span> rabbitmq <span class="token punctuation">-</span> qq.conf /etc/rabbitmq/rabbitmq.conf<span class="token keyword">COPY</span> rabbitmq <span class="token punctuation">-</span> qq <span class="token punctuation">-</span> definitions.json /etc/rabbitmq/rabbitmq <span class="token punctuation">-</span> definitions.json<span class="token comment">#ENV RABBITMQ_CONF_ENV_FILE /etc/rabbitmq/rabbitmq-env.conf</span><span class="token keyword">ENV</span> RABBITMQ_ERLANG_COOKIE cookieSecret<span class="token comment">#RUN apt-get update && apt-get install -y iputils-ping && apt-get install -y telnet && apt-get install -y nano</span>
- Note the
RABBITMQ_ERLANG_COOKIEenvironment variable is very important. If the rabbitmq nodes want to communicate with each other, this cookie value needs to be the same in order toauthen. (If this value is not set, the value oferlang.cookiewill be randomly generated, and differ on each node.) For other environmental variables supported by rabbitmq, see https://www.rabbitmq.com/configure.html#customise-environment
- Note the
- Configuration file
rabbitmq-qq.conf123456789101112131415161718192021222324252627loopback_users.guest = falselisteners.tcp.default = 5672management.listener.port = 15672management.listener.ssl = falsevm_memory_high_watermark.absolute = 1536MBcluster_name = rabbitmq-qqcluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_configcluster_formation.classic_config.nodes.1 = <a class="__cf_email__" href="/cdn-cgi/l/email-protection">[email protected]</a>cluster_formation.classic_config.nodes.2 = <a class="__cf_email__" href="/cdn-cgi/l/email-protection">[email protected]</a>cluster_formation.classic_config.nodes.3 = <a class="__cf_email__" href="/cdn-cgi/l/email-protection">[email protected]</a>management.load_definitions = /etc/rabbitmq/rabbitmq-definitions.json# background_gc_enabled = true# Increase the 5s default so that we are below Prometheus' scrape interval,# but still refresh in time for Prometheus scrape# This is linked to Prometheus scrape interval & range used with rate()collect_statistics_interval = 10000# Enable debugginglog.file = rabbit.loglog.dir = /var/log/rabbitmqlog.console.level = infocluster_partition_handling = pause_minoritylisteners.tcp.default=5672. port to the client to connect to the broker. Default port is 5672. Can be changed to another port if conflictmanagement.listener.port = 15672. port to go to webadmin gui- There is 1 port
epmdI do not put in the config file. By default, this port is4369. This port is very important, the nodes use this port todiscoveryeach other. Force port numbers to be the same on the nodes - Information on ports can be found at https://www.rabbitmq.com/networking.html#ports
rabbitmq1,rabbitmq2,rabbitmq3respectively the hostname of 3 nodes. (Note these 3 hostnames are different from the hostname of the ec2 instance, I wrote above). By default rabbitmq does not support FQDN. Want to use a long hostname. then set envRABBITMQ_USE_LONGNAME =true. More details https://www.rabbitmq.com/clustering.html#node-namescluster_partition_handling=pause_minority: when there is a networking partition problem, rabbitmq provides 3 policies for handler,pause-minority,pause-if-all-down,autoheal. If you do not declare this configuration, it willignoreit by default and do nothing. After I consulted, I found thatpause-minorityprobably will use the most. With this mode, the number of nodes on the lesser side will bedown. Messages and queues will be sent to the side with more nodes. Information about this issue I will write in more detail below. You can refer to https://www.rabbitmq.com/partitions.html
- File
rabbitmq-qq-definitions.json1234567891011121314151617181920212223<span class="token punctuation">{</span><span class="token property">"global_parameters"</span> <span class="token operator">:</span> <span class="token punctuation">[</span><span class="token punctuation">{</span> <span class="token property">"name"</span> <span class="token operator">:</span> <span class="token string">"cluster_name"</span> <span class="token punctuation">,</span> <span class="token property">"value"</span> <span class="token operator">:</span> <span class="token string">"rabbitmq-qq"</span> <span class="token punctuation">}</span><span class="token punctuation">]</span> <span class="token punctuation">,</span><span class="token property">"permissions"</span> <span class="token operator">:</span> <span class="token punctuation">[</span><span class="token punctuation">{</span><span class="token property">"configure"</span> <span class="token operator">:</span> <span class="token string">".*"</span> <span class="token punctuation">,</span><span class="token property">"read"</span> <span class="token operator">:</span> <span class="token string">".*"</span> <span class="token punctuation">,</span><span class="token property">"user"</span> <span class="token operator">:</span> <span class="token string">"tungtv"</span> <span class="token punctuation">,</span><span class="token property">"vhost"</span> <span class="token operator">:</span> <span class="token string">"/"</span> <span class="token punctuation">,</span><span class="token property">"write"</span> <span class="token operator">:</span> <span class="token string">".*"</span><span class="token punctuation">}</span><span class="token punctuation">]</span> <span class="token punctuation">,</span><span class="token property">"users"</span> <span class="token operator">:</span> <span class="token punctuation">[</span><span class="token punctuation">{</span><span class="token property">"name"</span> <span class="token operator">:</span> <span class="token string">"tungtv"</span> <span class="token punctuation">,</span><span class="token property">"password"</span> <span class="token operator">:</span> <span class="token string">"tungtv"</span> <span class="token punctuation">,</span><span class="token property">"tags"</span> <span class="token operator">:</span> <span class="token string">"administrator"</span><span class="token punctuation">}</span><span class="token punctuation">]</span> <span class="token punctuation">,</span><span class="token property">"vhosts"</span> <span class="token operator">:</span> <span class="token punctuation">[</span> <span class="token punctuation">{</span> <span class="token property">"name"</span> <span class="token operator">:</span> <span class="token string">"/"</span> <span class="token punctuation">}</span> <span class="token punctuation">]</span><span class="token punctuation">}</span>- This file I just to define the login account
- You can declare this file to
declarequeues, and more.
- Can build docker image with command
1 2 | docker build -t rabbitmq_ha_qq -f Dockerfile <span class="token builtin class-name">.</span> |
- Or can use directly docker image that I have built, and public at https://hub.docker.com/repository/docker/tungtv202/rabbitmq_ha_qq
3). Docker stack file
- docker-compose.yml file123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778<span class="token key atrule">version</span> <span class="token punctuation">:</span> <span class="token string">'3.7'</span><span class="token key atrule">volumes</span> <span class="token punctuation">:</span><span class="token key atrule">rabbitmq_volume</span> <span class="token punctuation">:</span><span class="token key atrule">services</span> <span class="token punctuation">:</span><span class="token key atrule">rabbitmq1</span> <span class="token punctuation">:</span><span class="token key atrule">image</span> <span class="token punctuation">:</span> tungtv202/rabbitmq_ha_qq<span class="token key atrule">ports</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> <span class="token string">"5672:5672"</span><span class="token punctuation">-</span> <span class="token string">"15672:15672"</span><span class="token key atrule">hostname</span> <span class="token punctuation">:</span> rabbitmq1<span class="token key atrule">volumes</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> rabbitmq_volume <span class="token punctuation">:</span> /var/lib/rabbitmq<span class="token key atrule">deploy</span> <span class="token punctuation">:</span><span class="token key atrule">replicas</span> <span class="token punctuation">:</span> <span class="token number">1</span><span class="token key atrule">placement</span> <span class="token punctuation">:</span><span class="token key atrule">constraints</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> node.hostname == ip <span class="token punctuation">-</span> 172 <span class="token punctuation">-</span> 31 <span class="token punctuation">-</span> 11 <span class="token punctuation">-</span> <span class="token number">205</span><span class="token key atrule">resources</span> <span class="token punctuation">:</span><span class="token key atrule">limits</span> <span class="token punctuation">:</span><span class="token key atrule">cpus</span> <span class="token punctuation">:</span> <span class="token string">'1'</span><span class="token key atrule">memory</span> <span class="token punctuation">:</span> <span class="token string">'500MB'</span><span class="token key atrule">reservations</span> <span class="token punctuation">:</span><span class="token key atrule">cpus</span> <span class="token punctuation">:</span> <span class="token string">'0.5'</span><span class="token key atrule">memory</span> <span class="token punctuation">:</span> <span class="token string">'50MB'</span><span class="token key atrule">restart_policy</span> <span class="token punctuation">:</span><span class="token key atrule">condition</span> <span class="token punctuation">:</span> on <span class="token punctuation">-</span> failure<span class="token key atrule">rabbitmq2</span> <span class="token punctuation">:</span><span class="token key atrule">image</span> <span class="token punctuation">:</span> tungtv202/rabbitmq_ha_qq<span class="token key atrule">ports</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> <span class="token string">"5677:5672"</span><span class="token punctuation">-</span> <span class="token string">"15677:15672"</span><span class="token key atrule">hostname</span> <span class="token punctuation">:</span> rabbitmq2<span class="token key atrule">volumes</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> rabbitmq_volume <span class="token punctuation">:</span> /var/lib/rabbitmq<span class="token key atrule">deploy</span> <span class="token punctuation">:</span><span class="token key atrule">replicas</span> <span class="token punctuation">:</span> <span class="token number">1</span><span class="token key atrule">placement</span> <span class="token punctuation">:</span><span class="token key atrule">constraints</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> node.hostname == ip <span class="token punctuation">-</span> 172 <span class="token punctuation">-</span> 31 <span class="token punctuation">-</span> 3 <span class="token punctuation">-</span> <span class="token number">230</span><span class="token key atrule">resources</span> <span class="token punctuation">:</span><span class="token key atrule">limits</span> <span class="token punctuation">:</span><span class="token key atrule">cpus</span> <span class="token punctuation">:</span> <span class="token string">'1'</span><span class="token key atrule">memory</span> <span class="token punctuation">:</span> <span class="token string">'500MB'</span><span class="token key atrule">reservations</span> <span class="token punctuation">:</span><span class="token key atrule">cpus</span> <span class="token punctuation">:</span> <span class="token string">'0.5'</span><span class="token key atrule">memory</span> <span class="token punctuation">:</span> <span class="token string">'50MB'</span><span class="token key atrule">restart_policy</span> <span class="token punctuation">:</span><span class="token key atrule">condition</span> <span class="token punctuation">:</span> on <span class="token punctuation">-</span> failure<span class="token key atrule">rabbitmq3</span> <span class="token punctuation">:</span><span class="token key atrule">image</span> <span class="token punctuation">:</span> tungtv202/rabbitmq_ha_qq<span class="token key atrule">ports</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> <span class="token string">"5666:5672"</span><span class="token punctuation">-</span> <span class="token string">"15666:15672"</span><span class="token key atrule">hostname</span> <span class="token punctuation">:</span> rabbitmq3<span class="token key atrule">volumes</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> rabbitmq_volume <span class="token punctuation">:</span> /var/lib/rabbitmq<span class="token key atrule">deploy</span> <span class="token punctuation">:</span><span class="token key atrule">replicas</span> <span class="token punctuation">:</span> <span class="token number">1</span><span class="token key atrule">placement</span> <span class="token punctuation">:</span><span class="token key atrule">constraints</span> <span class="token punctuation">:</span><span class="token punctuation">-</span> node.hostname == ip <span class="token punctuation">-</span> 172 <span class="token punctuation">-</span> 31 <span class="token punctuation">-</span> 1 <span class="token punctuation">-</span> <span class="token number">3</span><span class="token key atrule">resources</span> <span class="token punctuation">:</span><span class="token key atrule">limits</span> <span class="token punctuation">:</span><span class="token key atrule">cpus</span> <span class="token punctuation">:</span> <span class="token string">'1'</span><span class="token key atrule">memory</span> <span class="token punctuation">:</span> 500MB<span class="token key atrule">reservations</span> <span class="token punctuation">:</span><span class="token key atrule">cpus</span> <span class="token punctuation">:</span> <span class="token string">'0.5'</span><span class="token key atrule">memory</span> <span class="token punctuation">:</span> 50MB<span class="token key atrule">restart_policy</span> <span class="token punctuation">:</span><span class="token key atrule">condition</span> <span class="token punctuation">:</span> on <span class="token punctuation">-</span> failure
image: tungtv202/rabbitmq_ha_qq: docker image that I have built alreadyrabbitmq_volume: create volumes to persistent data. (If you have a problem with the lab, you should delete the volume and then recreate a new volume)- ports: route adds a port if some other public port is needed
replicas: 1: only 1 container per node is enough.- Use
constraints.constraintsto specify deployed deployments spread over 3 separate nodes. Hostname information here is EC2 hostname, I reminded above. - Because I use docker-swarm deployment, so when sharing a network, the containers will understand each other’s hostnames. (rabbitmq1, rabbitmq2, rabbitmq3). In case you do not use docker swarm, you can edit the above file to compose docker file. And more information
12345extra_hosts:- rabbitmq1:172.31.11.205- rabbitmq2:172.31.3.230- rabbitmq3:172.31.1.3- At the end of the lesson, I have share source config file available 3
docker-compose.ymlfiles to run independently on 3 instances. In case you are not using docker-swarm, docker stack
- Run
docker stackto deploy the service12docker stack deploy --compose-file docker-compose.yml rabbitmq
4). Check the result
- docker
- node1
- node2
- node3
- Web admin
- 172.31.11.205:15672
- 172.31.3.230:15677
- 172.31.1.3:15666
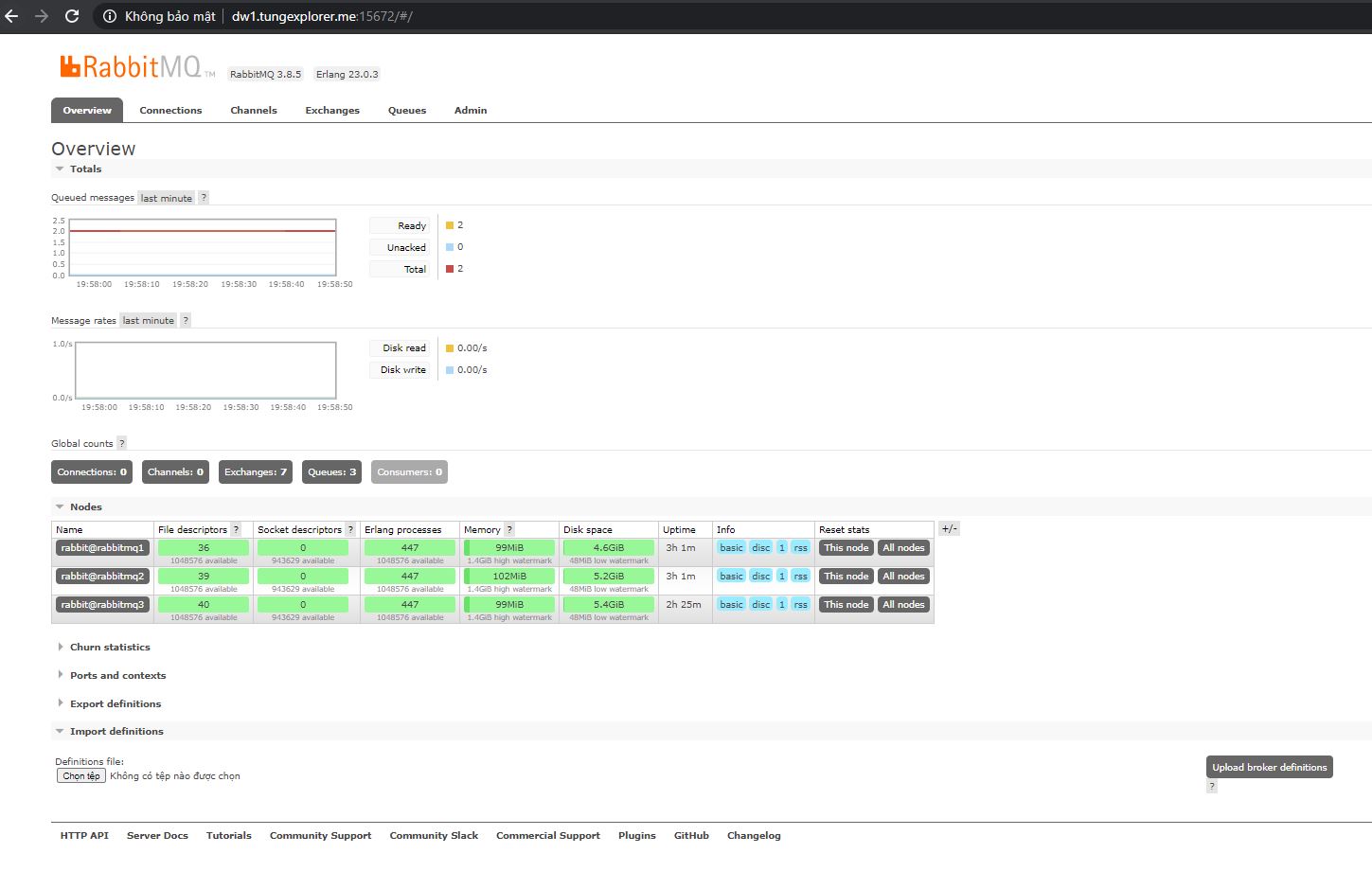
- Information about nodes in the cluster is shown in the
Overviewtab
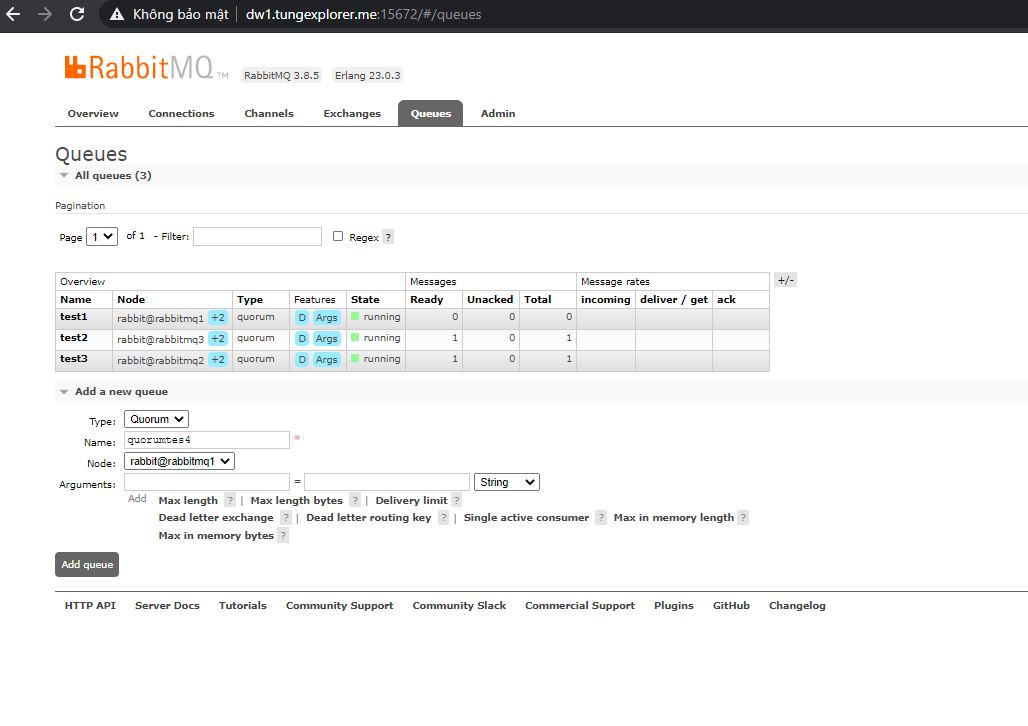
- Create Quorum Queue
- Go to the Queues tab to create a queue, and experience switching nodes on and off. To test the Hight Avalibility of the queue
- Note: Choose any 1 node to be the queue leader. (It does not matter, in the future, the cluster will automatically re-election the new leader)
- Go to the Queues tab to create a queue, and experience switching nodes on and off. To test the Hight Avalibility of the queue



5.) Some commands to debug errors during setup
- Check log container12docker logs CONTAINER_ID
- Access the container and use
rabbitmqctlcli. Refer to https://www.rabbitmq.com/rabbitmqctl.8.html123rabbitmq statusepmd -port <span class="token number">4369</span> -names
3. Lab some scenarios
3.1 There are nodes that are down / and reUp
- The script is quite simple, I find nothing complicated. You can stop the container. Or scale service = 0 to test.
- The first example Queue A, has the master node
[email protected], then stops the container on node1. Then the master node is moved to node2, or node3. And the message is not lost
3.2 Network parttion
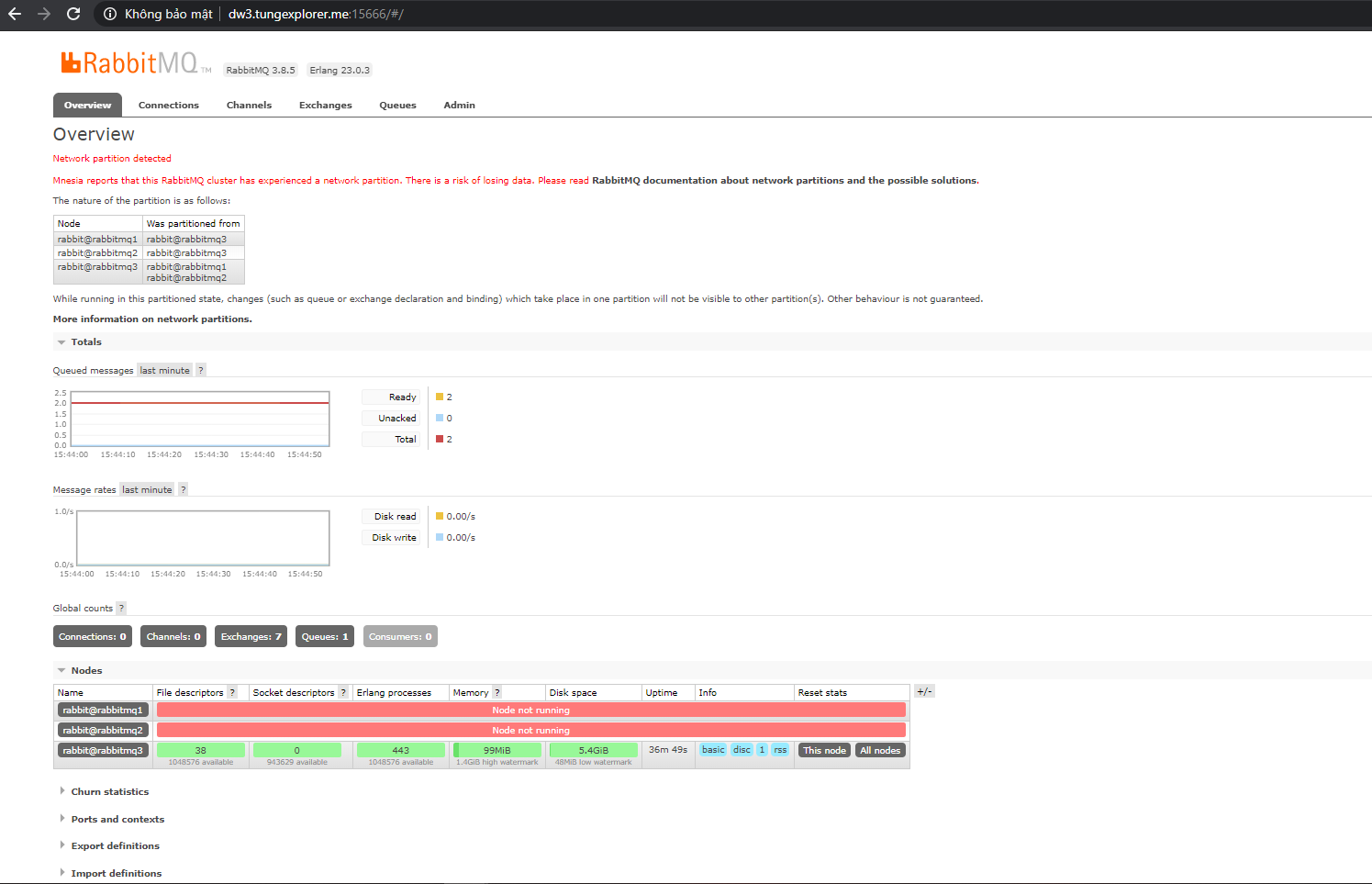
- This scenario can be reproduced by “dropping the network” between node3 vs the other 2 nodes. I use aws ec2, so I should go to fix Secure Group. Or you can create a firewall on the nodes. To block, do not allow the network to connect.
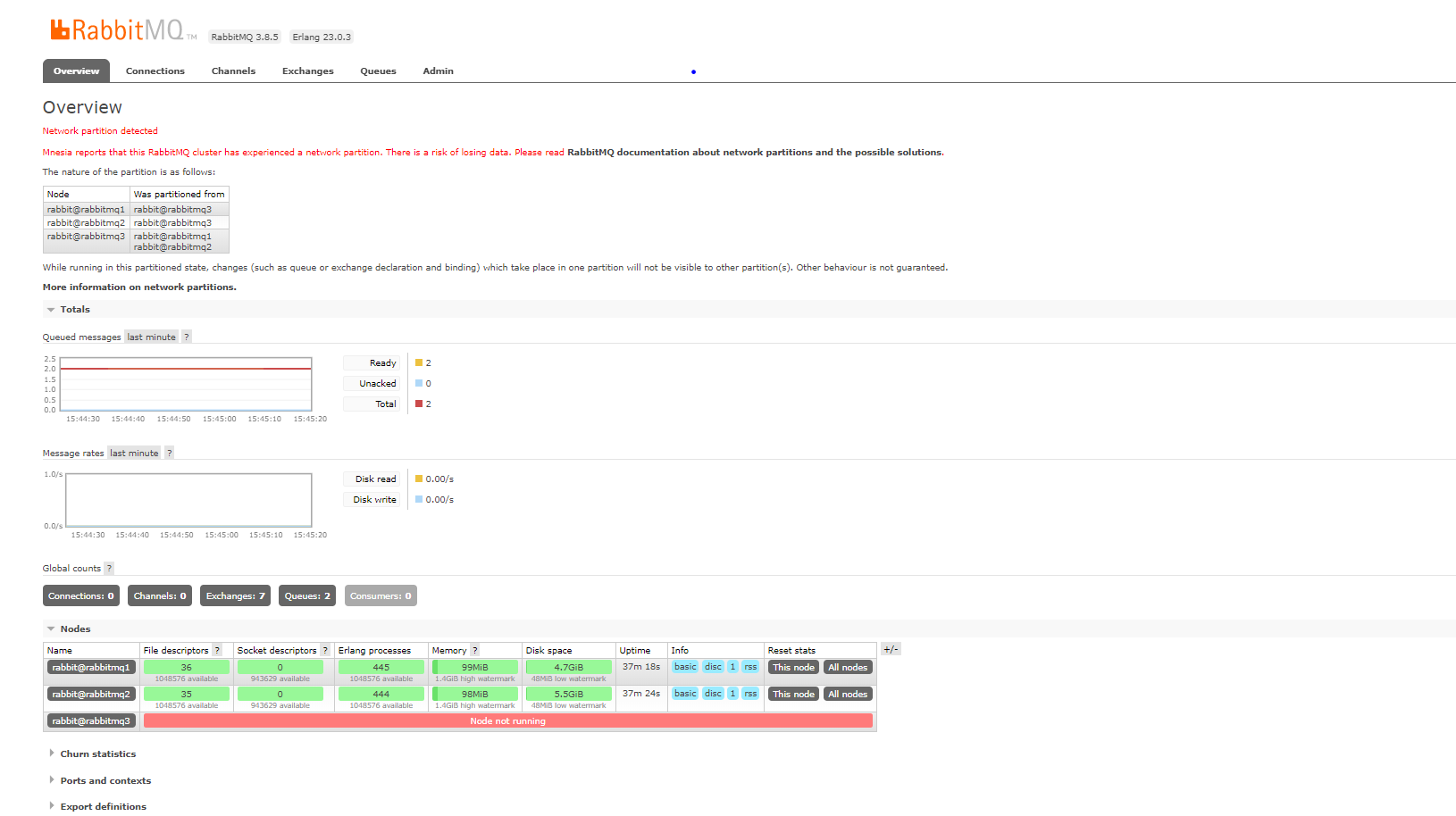
- (1) If I don’t have
cluster_partition_handling = pause_minorityinrabbitmq-qq.conffile, the following scenario will happen:- node3 thinks the other 2 nodes are down. It is itself the leader of that cluster.
- cluster node1 + node2, think node3 down. These 2 guys voted each other as leaders themselves.
- This problem is called
split-brain - And when the client creates a new queue, or writes a message to the queue on node3. There will be no data synchronization corresponding to cluster node1 + node2. And vice versa.
- At this point, both sides of node3, and node1 + node2 think that the other side is down. Not detected a
network partitionproblem. Only when we reconnect the network between 3 nodes together. At this time the cluster has just been discovered. (Rabbitmq writes that they use the Mnesia database to detect this problem) - Webadmin screenshot of node1 + node2
- Snapshot webadmin of node3
Hướng xử lýin this situation ?. You must choose 1 party as the standard. Then restart rabbitmq on the other side, leave rabbbitmq on the other side to rejoin the cluster. And synchronize the message from the standard side to. And accept the loss of data. Reference https://www.rabbitmq.com/partitions.html#recovering
- (2) If I have the configuration of
cluster_partition_handling = pause_minorityin myrabbitmq-qq.conffile, the following scenario will occur:- node3 sees it as it is. The whole cluster declares 3 nodes. Because 1 is less than 2. So rabbitmq on node3 for always down. And cluster node1 + node2 still run normally. (note that rabbitmq is shutdown, but the container is still running normally. Can be checked using
rabbitmqctl) - Now the route from the client will be redirected to cluster node1 + node2. (For this route to continue reading, part 4)
- node3 sees it as it is. The whole cluster declares 3 nodes. Because 1 is less than 2. So rabbitmq on node3 for always down. And cluster node1 + node2 still run normally. (note that rabbitmq is shutdown, but the container is still running normally. Can be checked using
4. Setup Nginx
- When I use java springboot to configure rabbitmq client. I just need to declare the list of brokers rabbitmq1, rabbitmq2, rabbitmq3. And the library automatically routes me to the “currently available” broker.
- In case the library does not support, we need an external endpoint inspiration. And check before the route to the broker is available.
- Can use nginx. With the following simple configuration12345678910111213141516events {}stream {upstream myrabbit {server 172.31.11.205:5672;server 172.31.3.230:5677;server 172.31.1.3:5666;}server {listen 5000;proxy_pass myrabbit;}}
Bonus
(This one’s not lab yet)
- Consider using Quorum Queue for Fanout Exchange. (Because the memory for storing messages is greatly increased => resource consuming)
- The default message on Quorum Queue is stored on memory / disk forever. Limit setup (and 3rd monitoring system) is required so that when the threshold is reached, rabbitmq releases resources
x-max-in-memory-lengthsets a limit as a number of messages. Must be a non-negative integer.x-max-in-memory-bytessets a limit as the total size of message bodies (payloads), in bytes. Must be a non-negative integer.
- Source code https://github.com/tungtv202/ops_rabbitmq_ha_qq