Trees are a type of data structure in the form of a set of nodes, which are linked together in a parent-child relationship. There are many types of trees, with different node arrangement rules.
Here, I would like to introduce some plants.
1. Basic tree
Define
Tree data structure with no constraints between nodes. A parent node can have many children.
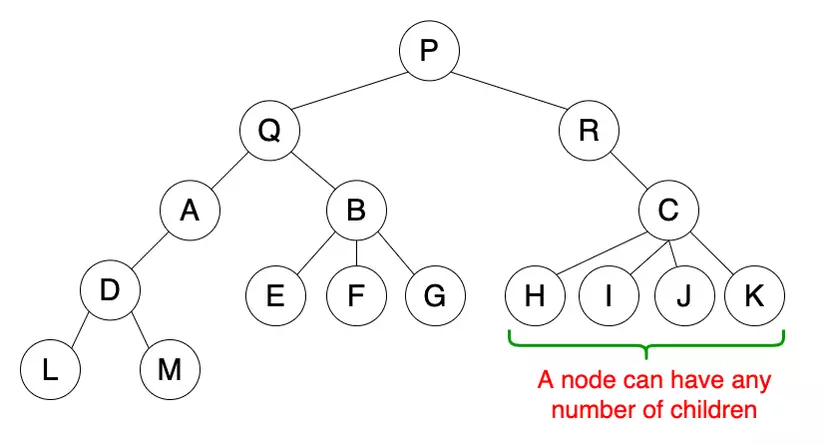
Application
The basic tree is used in representing hierarchical data such as folder structures, …
2. Binary tree
Define
A tree where each node has no more than 2 children is called a binary tree.
The left child node is called the left child, and the right child node is called the right child.
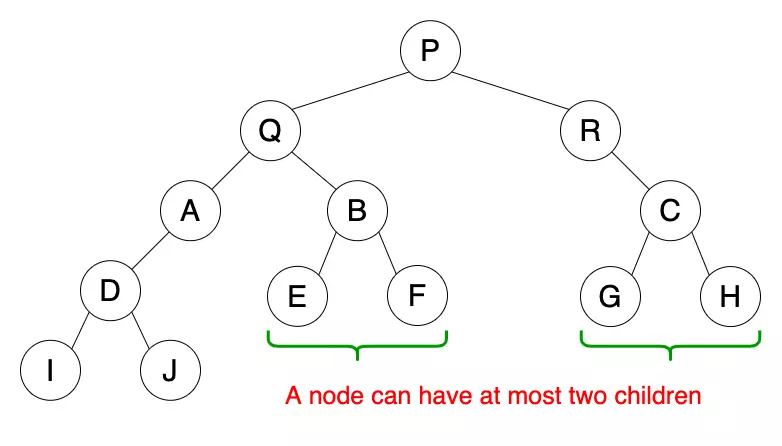
- A binary tree in which each vertex has exactly two children is called a “full binary tree”.
- A full binary tree where all leaves have the same depth is called a “perfect binary tree”.
- A binary tree, whose right child has a right child, also has a left child called an almost complete binary tree.
3. Binary tree search
The Binary Search Tree is a type of data structure used a lot.
Define
It is a binary tree that has the following constraints between nodes: value of left child <= value of parent node <= value of right child node.
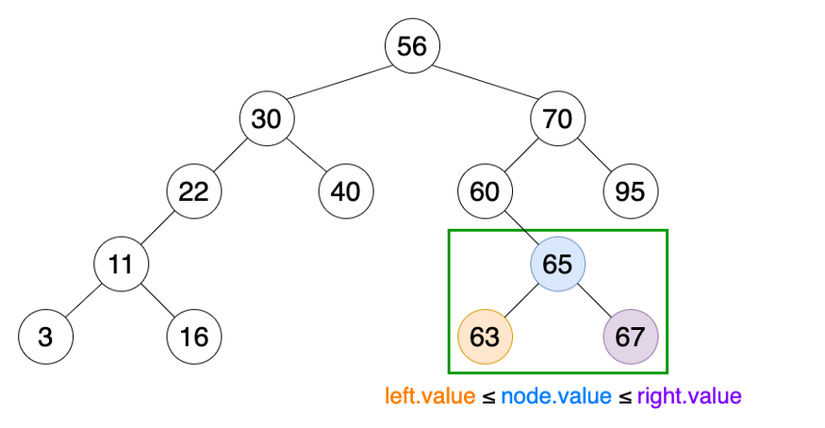
Application
- Storing data in the form of an arrangement, making it easier to find any node.
- Represent arithmetic expressions.
- Used in the Unix kernel to manage virtual memory.
4. Heap
Define
A binary tree is called a heap if the values of the nodes meet the following conditions:
Value of the parent element> value of the child element (Maximum pile)
or
Parent element value <child element value (Minimum heap)
Application
- Use in Dijkstra algorithm (find the shortest path).
- Use in problems that need to find maximum / minimum value quickly.
5. AVL tree
Define
The AVL tree (names of inventors Adelson, Velski and Landis) is a binary search tree with self-equilibrium nature.
The difference in height for the left and right subtree is called the Balance Factor. The AVL tree ensures that the Balance Factor is not greater than 1.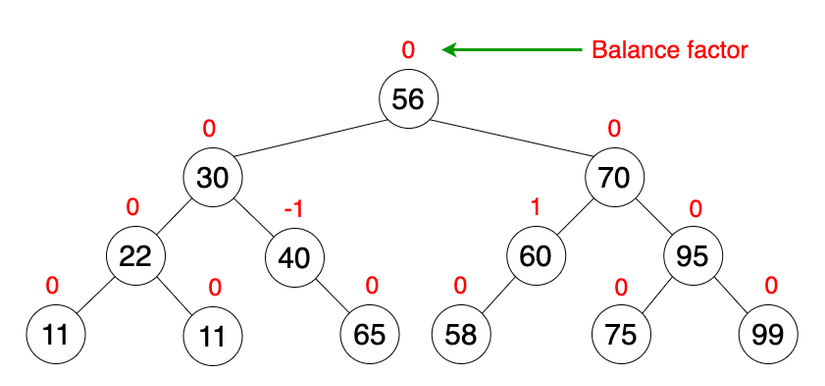
In the AVL tree, insertion, and deletion is always O (log n) time consuming in both average and worst-case scenarios.
6. Black and red tree
Define
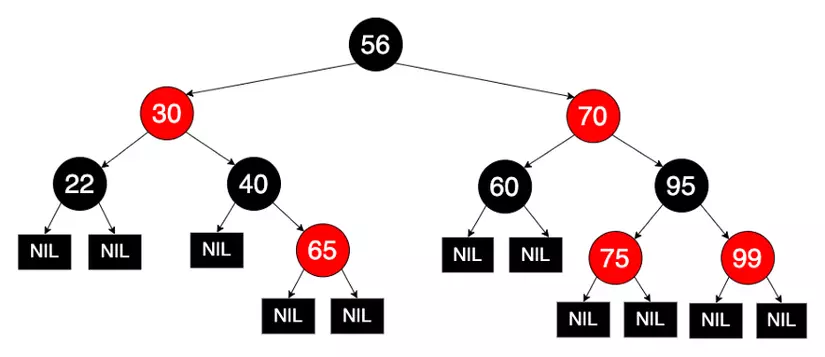
The red-black tree is a self-balancing binary search tree, which has the following properties:
- Every node in the tree must be red or black.
- The root node is black.
- All leaves (NULL) are black.
- Every red node has a child node that is black.
- All paths from any node to the leaves must pass an equal number of black nodes.

Application
- Used in the Completely Fair Scheduler (the scheduler is used in the Linux kernel).
- Mysql uses red and black trees for the index in the table.
- Used in K-mean clustering algorithm to reduce time complexity.