Hello everyone and happy new year !!!
A few days ago, I surfed the FB and found that my boss shared an interesting article on reddit about StyleGAN: Link article
In the comment section, the author explains that it used a technique called model blending to mix two StyleGAN2 models: one was trained on the FFHQ set to produce a lifelike human face, and the second model was finetune. from the above model with the Pixar character dataset. The new model will be able to create Pixar characters from real human faces. Then, the author used to add First Order Motion to animate a new photo according to a sample video.
In this article, I will introduce to everyone the model blending to create animated characters from real images. Let’s get started!
Introduction to GAN and StyleGAN
In this section, I will talk quickly about GAN and StyleGAN but will not talk carefully about the theory.
LIVER
Generative Adversatial Network (GAN) is one of the hottest models currently in deep learning with many applications in the field of imaging. GANs are comprised of 2 competing neural networks called generator and discriminator. The generator’s job is to trick the discriminator network that the image it produces is the real one, and the discriminator network will classify between the real image (from the dataset) and the dummy image (the image from the generator). 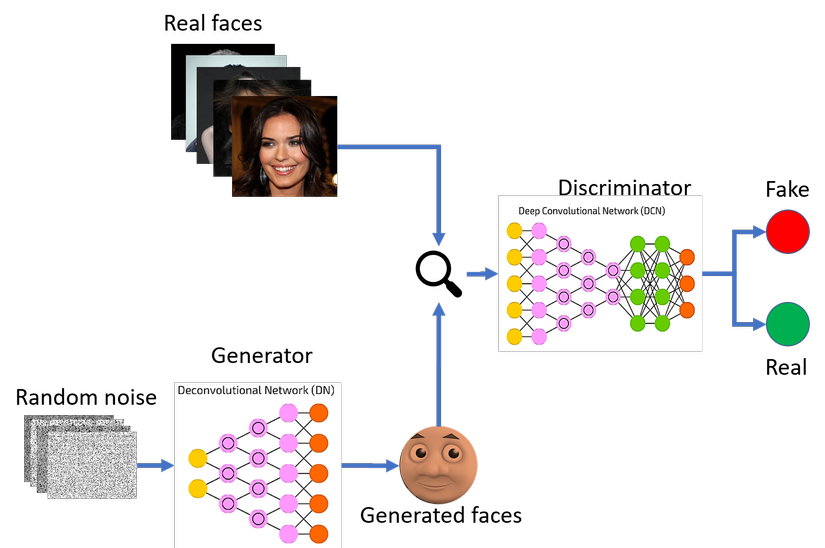
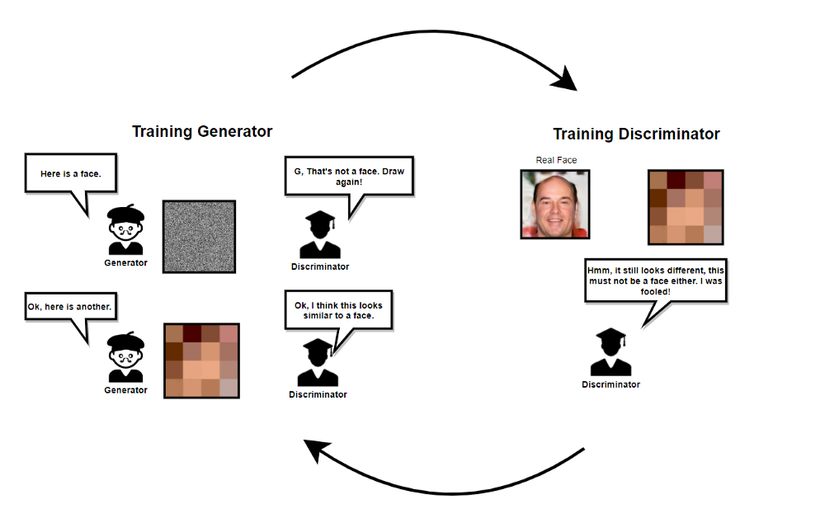
The discriminator network will be pre-trained by showing a batch of real images from the dataset and a batch of noise images (the generator is not yet trained).

Then we switch to the train generator. The generator network will learn to generate images with higher quality thanks to feedback from the discriminator (the image it generates is expected to be real or fake) until the discriminator can no longer distinguish between real and fake images. Next we pass the train discrminator and the process continues like this until the generator can generate an image very close to the image in the data set.
StyleGAN
The StyleGAN model was introduced by NVIDIA in 2018. StyleGAN introduces a new generator architecture that allows us to control the level of detail in the image from raw details (head shape, hairstyle …) to limbs. Smaller details (eye color, earrings …).
StyleGAN also integrates techniques from PGGAN , both generator and discrminator networks will initially be trained on a 4×4 image, after many layers will be added and the image size gradually increases. By this technique, the training time is significantly shortened and the training process is also more stable.
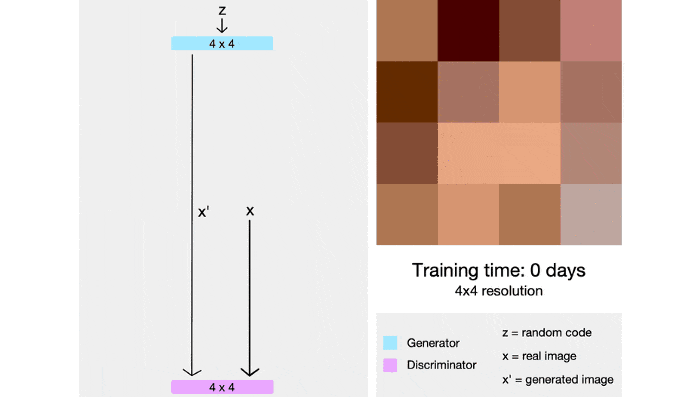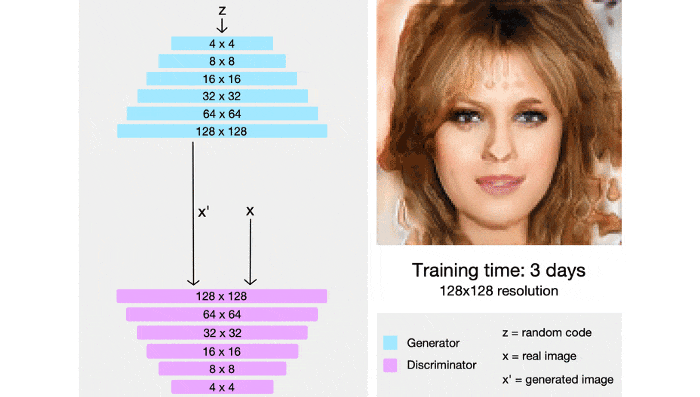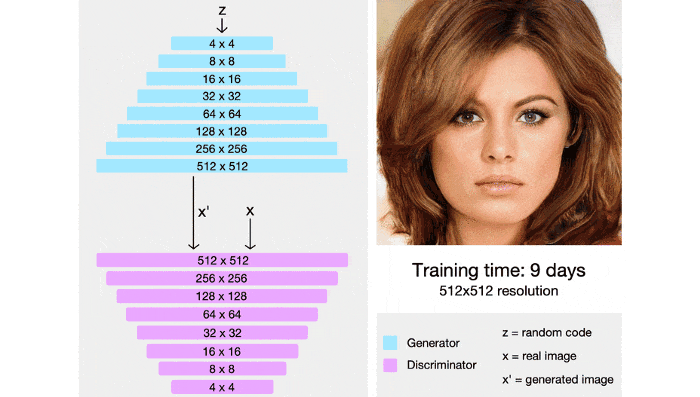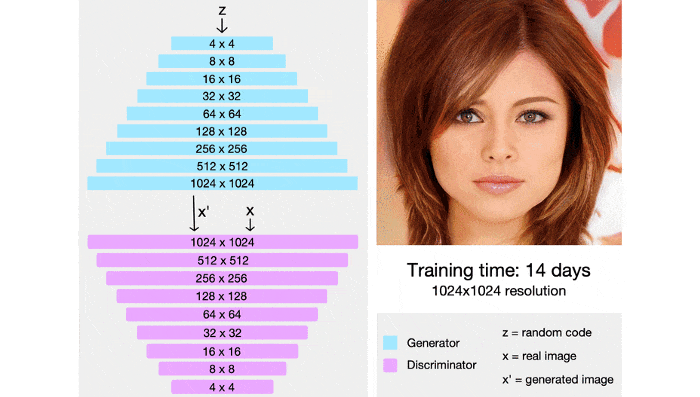
StyleGAN has the ability to control levels of granularity by using an additional mapping network that encodes vector z (taken from a standard multidimensional distribution) into a vector w . Vector w will then be put into many different positions in the genertor lattice, at each location vector w will control different features.
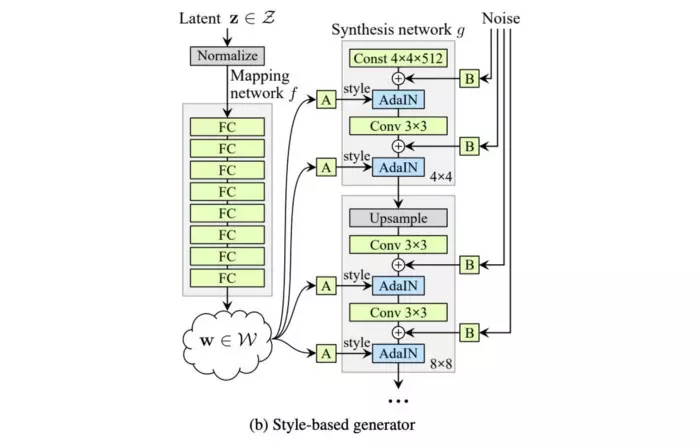
The head positions (in grades 4×4, 8×8) control raw features such as head shape, hairstyle, and glasses. The end positions (in layers 512×512, 1024, x1024) control facial texture features such as skin color, hair color, eye color, etc. 

Network blending
As written above, the low resolution layers of the model control the structural features of the face, and the layers at high resolution control texture features. of the face. By swapping the model weights at different resolutions, it is possible to select and blend the features generated by different generator networks. An example would be a photo of a real but textured cartoon character’s face.
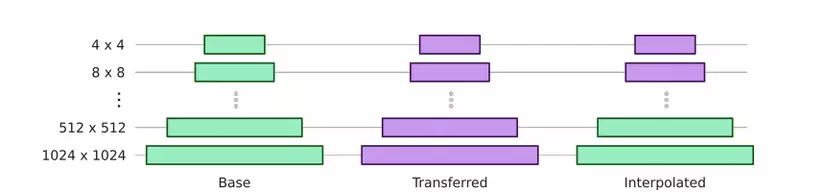

The process of blending 2 generator networks looks like this:
- Start with a StyleGAN pretrain model with weight p b a S e p_ {base} p b a s e
- Finetune the original model on the newly modeled dataset p t r a n S f e r p_ {transfer} p t r a n s f e r
- Combines the weights of the original model and the finetune model into the new weights

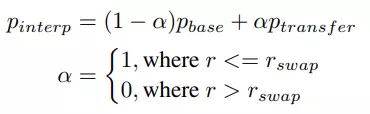
Inside, r S w a p r_ {swap} r s w a p is the resolution at which the weights of the two models begins.
Code
Enough theory, let’s start coding! Anyone who wants to try it out without code can see this link . Or a newer version here for a fee.
First, we need to clone the StyleGAN’s repo, here we can use StyleGAN2
1 2 | !git clone https <span class="token punctuation">:</span> <span class="token operator">//</span> github <span class="token punctuation">.</span> com <span class="token operator">/</span> NVlabs <span class="token operator">/</span> stylegan2 <span class="token punctuation">.</span> git |
This is followed by the load of the pretrain model and load the model. One model is open source by NVIDIA on the FFHQ dataset and another model is the model that has been finetune on an animated character dataset.
1 2 3 | !wget https <span class="token punctuation">:</span> <span class="token operator">//</span> nvlabs <span class="token operator">-</span> fi <span class="token operator">-</span> cdn <span class="token punctuation">.</span> nvidia <span class="token punctuation">.</span> com <span class="token operator">/</span> stylegan2 <span class="token operator">/</span> networks <span class="token operator">/</span> stylegan2 <span class="token operator">-</span> ffhq <span class="token operator">-</span> config <span class="token operator">-</span> f <span class="token punctuation">.</span> pkl !gdown https <span class="token punctuation">:</span> <span class="token operator">//</span> drive <span class="token punctuation">.</span> google <span class="token punctuation">.</span> com <span class="token operator">/</span> uc? <span class="token builtin">id</span> <span class="token operator">=</span> 1_fQCDp6A630MO0GZgsGySTlAuzEMDatB |
1 2 3 | _ <span class="token punctuation">,</span> _ <span class="token punctuation">,</span> Gs_1 <span class="token operator">=</span> pretrained_networks <span class="token punctuation">.</span> load_networks <span class="token punctuation">(</span> <span class="token string">'/content/stylegan2/stylegan2-ffhq-config-f.pkl'</span> <span class="token punctuation">)</span> _ <span class="token punctuation">,</span> _ <span class="token punctuation">,</span> Gs_2 <span class="token operator">=</span> pretrained_networks <span class="token punctuation">.</span> load_networks <span class="token punctuation">(</span> <span class="token string">'/content/stylegan2/ffhq-cartoons-000038.pkl'</span> <span class="token punctuation">)</span> |
Let’s take a look at the outputs of the two original models


Next is the code to blend the two models. Everyone can test with different resolutions to see the results
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | <span class="token keyword">def</span> <span class="token function">get_layers_names</span> <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token punctuation">:</span> names <span class="token operator">=</span> model <span class="token punctuation">.</span> trainables <span class="token punctuation">.</span> keys <span class="token punctuation">(</span> <span class="token punctuation">)</span> conv_names <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> resolutions <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token number">4</span> <span class="token operator">*</span> <span class="token number">2</span> <span class="token operator">**</span> x <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> <span class="token number">9</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> level_names <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">[</span> <span class="token string">"Conv0_up"</span> <span class="token punctuation">,</span> <span class="token string">'Const'</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> <span class="token punctuation">[</span> <span class="token string">"Conv1"</span> <span class="token punctuation">,</span> <span class="token string">"ToRGB"</span> <span class="token punctuation">]</span> <span class="token punctuation">]</span> position <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> res <span class="token keyword">in</span> resolutions <span class="token punctuation">:</span> root <span class="token operator">=</span> <span class="token string-interpolation"><span class="token string">f'G_synthesis/</span> <span class="token interpolation"><span class="token punctuation">{</span> res <span class="token punctuation">}</span></span> <span class="token string">x</span> <span class="token interpolation"><span class="token punctuation">{</span> res <span class="token punctuation">}</span></span> <span class="token string">/'</span></span> <span class="token keyword">for</span> level <span class="token punctuation">,</span> level_suffixes <span class="token keyword">in</span> <span class="token builtin">enumerate</span> <span class="token punctuation">(</span> level_names <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> suffix <span class="token keyword">in</span> level_suffixes <span class="token punctuation">:</span> search_name <span class="token operator">=</span> root <span class="token operator">+</span> suffix matched <span class="token operator">=</span> <span class="token punctuation">[</span> x <span class="token keyword">for</span> x <span class="token keyword">in</span> names <span class="token keyword">if</span> x <span class="token punctuation">.</span> startswith <span class="token punctuation">(</span> search_name <span class="token punctuation">)</span> <span class="token punctuation">]</span> to_add <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">(</span> name <span class="token punctuation">,</span> <span class="token string-interpolation"><span class="token string">f"</span> <span class="token interpolation"><span class="token punctuation">{</span> res <span class="token punctuation">}</span></span> <span class="token string">x</span> <span class="token interpolation"><span class="token punctuation">{</span> res <span class="token punctuation">}</span></span> <span class="token string">"</span></span> <span class="token punctuation">,</span> level <span class="token punctuation">,</span> position <span class="token punctuation">)</span> <span class="token keyword">for</span> name <span class="token keyword">in</span> matched <span class="token punctuation">]</span> conv_names <span class="token punctuation">.</span> extend <span class="token punctuation">(</span> to_add <span class="token punctuation">)</span> position <span class="token operator">+=</span> <span class="token number">1</span> <span class="token keyword">return</span> conv_names <span class="token keyword">def</span> <span class="token function">blend</span> <span class="token punctuation">(</span> model_1 <span class="token punctuation">,</span> model_2 <span class="token punctuation">,</span> resolution <span class="token punctuation">,</span> level <span class="token punctuation">)</span> <span class="token punctuation">:</span> resolution <span class="token operator">=</span> <span class="token string-interpolation"><span class="token string">f"</span> <span class="token interpolation"><span class="token punctuation">{</span> resolution <span class="token punctuation">}</span></span> <span class="token string">x</span> <span class="token interpolation"><span class="token punctuation">{</span> resolution <span class="token punctuation">}</span></span> <span class="token string">"</span></span> model_1_names <span class="token operator">=</span> get_layers_names <span class="token punctuation">(</span> model_1 <span class="token punctuation">)</span> model_2_names <span class="token operator">=</span> get_layers_names <span class="token punctuation">(</span> model_2 <span class="token punctuation">)</span> Gs_out <span class="token operator">=</span> model_1 <span class="token punctuation">.</span> clone <span class="token punctuation">(</span> <span class="token punctuation">)</span> short_names <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">(</span> x <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">:</span> <span class="token number">3</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> model_1_names <span class="token punctuation">]</span> full_names <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">(</span> x <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> model_2_names <span class="token punctuation">]</span> split_point_idx <span class="token operator">=</span> short_names <span class="token punctuation">.</span> index <span class="token punctuation">(</span> <span class="token punctuation">(</span> resolution <span class="token punctuation">,</span> level <span class="token punctuation">)</span> <span class="token punctuation">)</span> split_point_pos <span class="token operator">=</span> model_1_names <span class="token punctuation">[</span> split_point_idx <span class="token punctuation">]</span> <span class="token punctuation">[</span> <span class="token number">3</span> <span class="token punctuation">]</span> ys <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> name <span class="token punctuation">,</span> resolution <span class="token punctuation">,</span> level <span class="token punctuation">,</span> position <span class="token keyword">in</span> model_1_names <span class="token punctuation">:</span> x <span class="token operator">=</span> position <span class="token operator">-</span> split_point_pos y <span class="token operator">=</span> <span class="token number">1</span> <span class="token keyword">if</span> x <span class="token operator">></span> <span class="token number">1</span> <span class="token keyword">else</span> <span class="token number">0</span> ys <span class="token punctuation">.</span> append <span class="token punctuation">(</span> y <span class="token punctuation">)</span> tfutil <span class="token punctuation">.</span> set_vars <span class="token punctuation">(</span> tfutil <span class="token punctuation">.</span> run <span class="token punctuation">(</span> <span class="token punctuation">{</span> Gs_out <span class="token punctuation">.</span> <span class="token builtin">vars</span> <span class="token punctuation">[</span> name <span class="token punctuation">]</span> <span class="token punctuation">:</span> <span class="token punctuation">(</span> model_2 <span class="token punctuation">.</span> <span class="token builtin">vars</span> <span class="token punctuation">[</span> name <span class="token punctuation">]</span> <span class="token operator">*</span> y <span class="token operator">+</span> model_1 <span class="token punctuation">.</span> <span class="token builtin">vars</span> <span class="token punctuation">[</span> name <span class="token punctuation">]</span> <span class="token operator">*</span> <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token operator">-</span> y <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> name <span class="token punctuation">,</span> y <span class="token keyword">in</span> <span class="token builtin">zip</span> <span class="token punctuation">(</span> full_names <span class="token punctuation">,</span> ys <span class="token punctuation">)</span> <span class="token punctuation">}</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> Gs_out Gs <span class="token operator">=</span> blend <span class="token punctuation">(</span> Gs_2 <span class="token punctuation">,</span> Gs_1 <span class="token punctuation">,</span> <span class="token number">32</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> |
And this is the result. Not bad either

Just for fun
This section just lets me share a few models after combining. Ukioe-style portraits and “surreal” ukioe paintings



Painting style
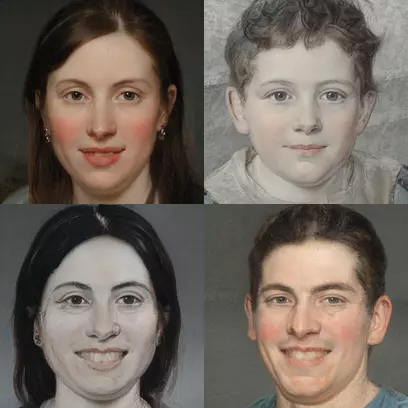
Figure drawings



Style ???


Epilogue
Thank you all for taking the time to read the article and wish you all a happy and prosperous New Year
References
https://arxiv.org/pdf/2010.05334.pdf
https://arxiv.org/abs/1812.04948
https://github.com/justinpinkney/stylegan2
https://github.com/justinpinkney/awesome-pretrained-stylegan2
https://github.com/NVlabs/stylegan
https://www.justinpinkney.com/stylegan-network-blending/