Why does the model need to be tiny?
There are many people who only care about training a Deep learning model so that the accuracy is really high. Sometimes models have enormous complexity and there is really no rule to choose a really good architecture. Creating a model with accuracy is good enough but the number of calculations is very small, it is really a matter of concern, isn’t it. There is a sentence that he quite liked it
The AI models that reside on jupyter notebooks are the dead models.
This sentence means that no matter how good you model and experiment, just leaving it on a jupyter notebook is just a research model. And if you want to apply it in practice, then it needs a lot of factors other than accuracy, guys. This statement also places more emphasis on post-processing after modeling and deployment on real systems. So for practical systems, we should have thought to make our model as simple, lighter the better. Of course still have to ensure accuracy. Since then the concept of compression model was born and these are the main reasons for it
- Help reduce storage size : When our model is deployed on the computer siu, then you should relax the hen, there is nothing to worry about. Unfortunately, life is not always a dream, we are not always able to touch a computer to deploy. The vast majority of projects want to save money, so it is worth researching to bring AI down to medium-speed hardware. We can mention devices with limited storage space like Rapberry Pi, Mobile, Embeded Device … so reducing the size of the model is very important. Imagine instead of storing 1 1GB model, the children reduced to 10MB only then went to a different story. If you ensemble 10 variants of the 1GB model, you will spend 10GB to store the memory, whereas if you compress it to 10MB, then you only need 100MB of physical memory. It’s so different, isn’t it?
- Help speed up processing : This is natural then, if the whole world is siu computer like he mentioned above, it would not need to care much about this problem. However, most large AI models will not be able to run real time on low-processing hardware. So it is best to choose a simple model for everyone.
- Accuracy varies insignificantly : Perhaps the children are wondering if simply choosing the simple model will not achieve the required accuracy. This of course is a true question. However, if compressing the model is simply understood, instead of training a large model, training a smaller model is not entirely true. The meaning of the compression word here is that from a larger model, we reduce the size while preserving the accuracy of the original large model. The key point here is that accuracy is not changed so much, guys. This is the technique to design a small but martial art model
How to model “small but martial”
From martial arts training to model training
It sounds strange yet, small but having martial arts reminds us of a certain swordplay series, isn’t it? The players in the past were mostly teen heroes, but one thing they have in common is that these heroic teenagers are usually acquired from a famous master or have a chance to meet. be secretly superior martial. So it’s not natural to be a hero, guys.  Back to the training of our model, if the model we initially built is super small and want it to have super huge power, it will be difficult , guys. Must try hard a lot but the result is not much. These models are just called small working age, depending on their own strength , please. So how to achieve the upper realm like above? There are some basic ways you can grasp the following:
Back to the training of our model, if the model we initially built is super small and want it to have super huge power, it will be difficult , guys. Must try hard a lot but the result is not much. These models are just called small working age, depending on their own strength , please. So how to achieve the upper realm like above? There are some basic ways you can grasp the following:
- Self-cultivation of recipes and refining into their own : Learning from the secret means learning from the superior martial masters but know how to create creative minimalism, turn into their martial arts. This demonstrates in compressing the model that training a larger model achieves good accuracy then streamlining, eliminating unnecessary components in that model to achieve a microscopic model. . This approach is quite self-advocating, requiring you to have a solid martial arts foundation (similar to having a good network architecture, complex enough to learn all the cases) but the results are achieved. usually very satisfactory.
- Absorbing internal resources from the predecessors : In martial arts, there are also occasional lucky young people, martial arts, they still have no basis but meet the noble and beloved people for the inner and natural public. become a master. Your childhood will still remember the young people below. It is in the martial arts world, in training model is no different from you guys. There is a technique called Knowledge distillation, which is how to train a smaller model by re-learning the knowledge learned from a larger model. This is almost like the kind of master who devoted all his life to educating the true disciples on his advice.

Password determination France
Guys, the martial arts training methods are similar to the AI model training, there are many ups and downs, many events occur to be able to achieve a good model. Hope you understand that. Now it is time for me to show you the verdict and mind of the martial art that compresses this model for you. Encourage the children to read this section, do not rush to jump into practice right away, it is easy to get into the fire , guys. Let’s get started, guys.
Cut
Network pruning is not a new concept, especially for children who work hard with Deep Learning models. Actually, the dropout that you often use during training is also a form of pruning to avoid overfit phenomenon. However, pruning applications in the compression model is a concept not quite similar to dropout. If the dropout will randomly drop a percentage of the number of connections between the layers during the training process, the Network pruning concept here means finding unnecessary connections in the network (removing it does not affect much accuracy) to prune away. This algorithm can be implemented through three steps as follows:
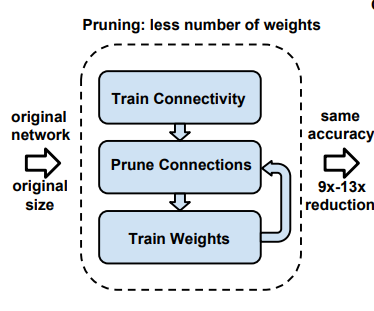
- This network training is usually a large network with full connections between each layer. The reason for choosing a network large enough to help model learning achieve a certain level of accuracy
- Remove redundant connections : We will discard connections with weights less than a predetermined threshold. Usually these weights are not too important and can be removed. Of course, when removing these connections, your network will become more sparse because there are many connections that are set to 0 and will affect accuracy at first. Therefore, to restore the original accuracy, the children need to do the third step
- Retrain the pruned network architecture after pruning, the accuracy will change, your job is to retrain the parameters (of the trimmed model) to achieve the same accuracy. equivalent to the initial accuracy. And eventually you will get a model that is both small and martial

Quantization and share weight
After compressing the model using the pruning method (In his lower experiment it decreased to 90% of the original network). We will use a technique called quantization to reduce the number of bits needed to store neural network weights. In simple terms like this, you have to cook rice for a family of many generations, cook a soup that your father-in-law likes to give 0.9 liters of fish sauce, his mother-in-law likes to give 0.95 liters of fish sauce. husband likes to add 1 liter of fish sauce If you cook like that, it will be very laborious, so you just need to choose a suitable amount of fish sauce for the whole cafeteria and the figure of 0.95 liters of fish sauce (according to the interests of mother-in-law) is more balanced and skillful. . This is the rule of selecting representative rating and is also the main ideology of quantization and share weight . This is the process of dividing the entire weight of a layer into clusters and each cluster will share the same weight value. This value is usually the centroid value representing the most characteristic of the cluster. This is similar to the fact that you choose your mother-in-law to be the center of that family. For a better picture, please see the picture below:
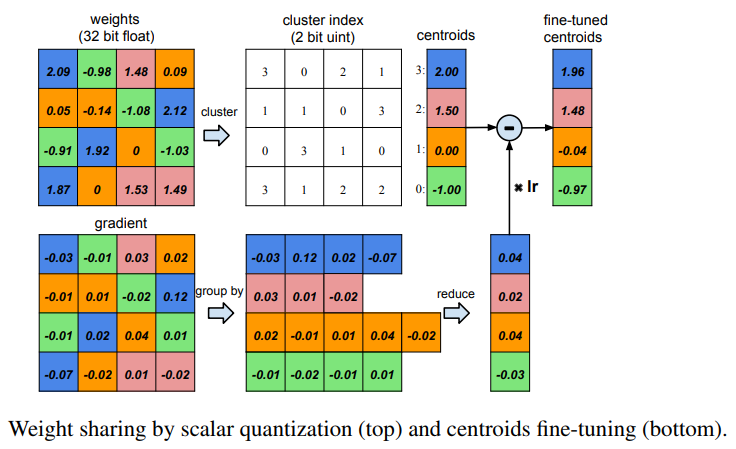
You can identify a few things:
- The first Weight matrix (top left) is the initial weight. From this matrix we divide it into 4 different clusters represented by 4 colors blue, green, orange and pink. This is done using k-means with k equal to 4.
- then each cluster will be saved the same value as the center of the cluster value, shown at the top right. So with 4 clusters you only need to save 4 values of centroid and cost
16 ∗ 2 = 32 16 * 2 = 32 bits to save the index position - A general way to calculate the network compression when using quantization and share weight, you need to imagine the following. At first yes
n n weight and costb b bits for storage
n n weight that. So the number of bits used is
n b nb . After quantization becomes
k k clusters will cost
k b kb bits to store the centroid value of each cluster and add
n l o g 2 ( k ) nlog_2 (k) bits to store the value of the index. So the compression ratio will be
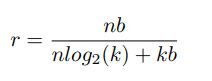
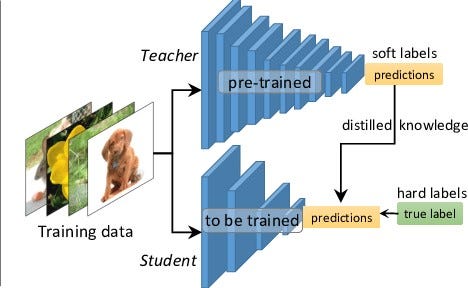
Knowledge distillation – Knowledge distillation
Knowledge distillation is a new idea of compression network, it is not based on trimming on the old network itself, but using a larger neural network that has been trained to teach a smaller network. By teaching the small network to learn each feature map after each accumulation class of the big network, this can be considered a soft-label for that small network. In simple terms, instead of learning directly from the original data, the small network will re-learn how the big network learned, re-learn wieght distributions and feature maps that have been generalized from the large network. The small network will try to learn the ways of dealing with the large network at every layer of the network, not just the total loss function. You can picture it in the following picture. Regarding this internal transmission method, he will dedicate an article to write about the techniques and ways to implement the network in it.
Cultivation tips
Now for the part that everyone is looking forward to, let’s go into the code. After all, studying theory forever has to be practical. In this section, I will not use any pruning library but will guide you to implement from the beginning to understand the nature of this algorithm. Not too complicated. Let’s get started
Cut
The first method we will consider is pruning. To demo for this article, he used the structure of Fully Connected is simple. The implementation of CNN or LSTM models is similar if you understand its ideas already.
Import the necessary libraries
In this article, I use Pytorch, so you need to import some necessary libraries
1 2 3 4 5 6 7 8 | <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np <span class="token keyword">import</span> torch <span class="token keyword">from</span> torch <span class="token punctuation">.</span> nn <span class="token keyword">import</span> Parameter <span class="token keyword">from</span> torch <span class="token punctuation">.</span> nn <span class="token punctuation">.</span> modules <span class="token punctuation">.</span> module <span class="token keyword">import</span> Module <span class="token keyword">import</span> torch <span class="token punctuation">.</span> nn <span class="token punctuation">.</span> functional <span class="token keyword">as</span> F <span class="token keyword">import</span> math <span class="token keyword">from</span> torch <span class="token keyword">import</span> nn |
Building base model
The trimming model should be inherited from the Pytorch base module . As I told you from the theory section, the nature of pruning is to select a threshold to filter out weights that are smaller than that (less important weights). For simplicity, he will use the standard deviation to calculate the threshold.
1 2 3 4 5 6 7 8 9 10 | <span class="token keyword">class</span> <span class="token class-name">PruningModule</span> <span class="token punctuation">(</span> Module <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">prune_by_std</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> s <span class="token operator">=</span> <span class="token number">0.25</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token comment"># Note that module here is the layer</span> <span class="token comment"># ex) fc1, fc2, fc3</span> <span class="token keyword">for</span> name <span class="token punctuation">,</span> module <span class="token keyword">in</span> self <span class="token punctuation">.</span> named_modules <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> name <span class="token keyword">in</span> <span class="token punctuation">[</span> <span class="token string">'fc1'</span> <span class="token punctuation">,</span> <span class="token string">'fc2'</span> <span class="token punctuation">,</span> <span class="token string">'fc3'</span> <span class="token punctuation">]</span> <span class="token punctuation">:</span> threshold <span class="token operator">=</span> np <span class="token punctuation">.</span> std <span class="token punctuation">(</span> module <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token operator">*</span> s <span class="token keyword">print</span> <span class="token punctuation">(</span> f <span class="token string">'Pruning with threshold : {threshold} for layer {name}'</span> <span class="token punctuation">)</span> module <span class="token punctuation">.</span> prune <span class="token punctuation">(</span> threshold <span class="token punctuation">)</span> |
You can customize the parameter s = 0.25 to calculate the value of the threshold to be trimmed
Build trimming module
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | <span class="token keyword">class</span> <span class="token class-name">MaskedLinear</span> <span class="token punctuation">(</span> Module <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">__init__</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> in_features <span class="token punctuation">,</span> out_features <span class="token punctuation">,</span> bias <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token builtin">super</span> <span class="token punctuation">(</span> MaskedLinear <span class="token punctuation">,</span> self <span class="token punctuation">)</span> <span class="token punctuation">.</span> __init__ <span class="token punctuation">(</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> in_features <span class="token operator">=</span> in_features self <span class="token punctuation">.</span> out_features <span class="token operator">=</span> out_features self <span class="token punctuation">.</span> weight <span class="token operator">=</span> Parameter <span class="token punctuation">(</span> torch <span class="token punctuation">.</span> Tensor <span class="token punctuation">(</span> out_features <span class="token punctuation">,</span> in_features <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token comment"># Initialize the mask with 1</span> self <span class="token punctuation">.</span> mask <span class="token operator">=</span> Parameter <span class="token punctuation">(</span> torch <span class="token punctuation">.</span> ones <span class="token punctuation">(</span> <span class="token punctuation">[</span> out_features <span class="token punctuation">,</span> in_features <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> requires_grad <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token keyword">if</span> bias <span class="token punctuation">:</span> self <span class="token punctuation">.</span> bias <span class="token operator">=</span> Parameter <span class="token punctuation">(</span> torch <span class="token punctuation">.</span> Tensor <span class="token punctuation">(</span> out_features <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">else</span> <span class="token punctuation">:</span> self <span class="token punctuation">.</span> register_parameter <span class="token punctuation">(</span> <span class="token string">'bias'</span> <span class="token punctuation">,</span> <span class="token boolean">None</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> reset_parameters <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">reset_parameters</span> <span class="token punctuation">(</span> self <span class="token punctuation">)</span> <span class="token punctuation">:</span> stdv <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">.</span> <span class="token operator">/</span> math <span class="token punctuation">.</span> sqrt <span class="token punctuation">(</span> self <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> size <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> data <span class="token punctuation">.</span> uniform_ <span class="token punctuation">(</span> <span class="token operator">-</span> stdv <span class="token punctuation">,</span> stdv <span class="token punctuation">)</span> <span class="token keyword">if</span> self <span class="token punctuation">.</span> bias <span class="token keyword">is</span> <span class="token operator">not</span> <span class="token boolean">None</span> <span class="token punctuation">:</span> self <span class="token punctuation">.</span> bias <span class="token punctuation">.</span> data <span class="token punctuation">.</span> uniform_ <span class="token punctuation">(</span> <span class="token operator">-</span> stdv <span class="token punctuation">,</span> stdv <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">forward</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> <span class="token builtin">input</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token comment"># Caculate weight when forward step</span> <span class="token keyword">return</span> F <span class="token punctuation">.</span> linear <span class="token punctuation">(</span> <span class="token builtin">input</span> <span class="token punctuation">,</span> self <span class="token punctuation">.</span> weight <span class="token operator">*</span> self <span class="token punctuation">.</span> mask <span class="token punctuation">,</span> self <span class="token punctuation">.</span> bias <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">__repr__</span> <span class="token punctuation">(</span> self <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">return</span> self <span class="token punctuation">.</span> __class__ <span class="token punctuation">.</span> __name__ <span class="token operator">+</span> <span class="token string">'('</span> <span class="token operator">+</span> <span class="token string">'in_features='</span> <span class="token operator">+</span> <span class="token builtin">str</span> <span class="token punctuation">(</span> self <span class="token punctuation">.</span> in_features <span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token string">', out_features='</span> <span class="token operator">+</span> <span class="token builtin">str</span> <span class="token punctuation">(</span> self <span class="token punctuation">.</span> out_features <span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token string">', bias='</span> <span class="token operator">+</span> <span class="token builtin">str</span> <span class="token punctuation">(</span> self <span class="token punctuation">.</span> bias <span class="token keyword">is</span> <span class="token operator">not</span> <span class="token boolean">None</span> <span class="token punctuation">)</span> <span class="token operator">+</span> <span class="token string">')'</span> <span class="token comment"># Customize of prune function with mask</span> <span class="token keyword">def</span> <span class="token function">prune</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> threshold <span class="token punctuation">)</span> <span class="token punctuation">:</span> weight_dev <span class="token operator">=</span> self <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> device mask_dev <span class="token operator">=</span> self <span class="token punctuation">.</span> mask <span class="token punctuation">.</span> device <span class="token comment"># Convert Tensors to numpy and calculate</span> tensor <span class="token operator">=</span> self <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> mask <span class="token operator">=</span> self <span class="token punctuation">.</span> mask <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> new_mask <span class="token operator">=</span> np <span class="token punctuation">.</span> where <span class="token punctuation">(</span> <span class="token builtin">abs</span> <span class="token punctuation">(</span> tensor <span class="token punctuation">)</span> <span class="token operator"><</span> threshold <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> mask <span class="token punctuation">)</span> <span class="token comment"># Apply new weight and mask</span> self <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> data <span class="token operator">=</span> torch <span class="token punctuation">.</span> from_numpy <span class="token punctuation">(</span> tensor <span class="token operator">*</span> new_mask <span class="token punctuation">)</span> <span class="token punctuation">.</span> to <span class="token punctuation">(</span> weight_dev <span class="token punctuation">)</span> self <span class="token punctuation">.</span> mask <span class="token punctuation">.</span> data <span class="token operator">=</span> torch <span class="token punctuation">.</span> from_numpy <span class="token punctuation">(</span> new_mask <span class="token punctuation">)</span> <span class="token punctuation">.</span> to <span class="token punctuation">(</span> mask_dev <span class="token punctuation">)</span> |
In the above function, you need to pay attention to some main functions as follows:
- Mask : do you notice the
self.masklayer is defined? This is a mask or filter that allows us to decide which weights are calculated and which ones are not. This mask was originally initialized as a full-number matrix. After trimming any weights you no longer need, it will be zero. - Forward function This function performs weight calculation function, instead of multiplying weight directly with normal input, then weight will be multiplied by filter first. This eliminates unnecessary weight after pruning
1 2 | F <span class="token punctuation">.</span> linear <span class="token punctuation">(</span> <span class="token builtin">input</span> <span class="token punctuation">,</span> self <span class="token punctuation">.</span> weight <span class="token operator">*</span> self <span class="token punctuation">.</span> mask <span class="token punctuation">,</span> self <span class="token punctuation">.</span> bias <span class="token punctuation">)</span> |
- The prune function performs the main function of pruning. At each trimming it will calculate the numbers that have a weight smaller than the specified threshold, update the mask and weight at those locations to the value of 0. It’s quite simple, isn’t it?
Fully Connected network settings
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <span class="token keyword">class</span> <span class="token class-name">LeNet</span> <span class="token punctuation">(</span> PruningModule <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">__init__</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> mask <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token builtin">super</span> <span class="token punctuation">(</span> LeNet <span class="token punctuation">,</span> self <span class="token punctuation">)</span> <span class="token punctuation">.</span> __init__ <span class="token punctuation">(</span> <span class="token punctuation">)</span> linear <span class="token operator">=</span> MaskedLinear <span class="token keyword">if</span> mask <span class="token keyword">else</span> nn <span class="token punctuation">.</span> Linear self <span class="token punctuation">.</span> fc1 <span class="token operator">=</span> linear <span class="token punctuation">(</span> <span class="token number">784</span> <span class="token punctuation">,</span> <span class="token number">300</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> fc2 <span class="token operator">=</span> linear <span class="token punctuation">(</span> <span class="token number">300</span> <span class="token punctuation">,</span> <span class="token number">100</span> <span class="token punctuation">)</span> self <span class="token punctuation">.</span> fc3 <span class="token operator">=</span> linear <span class="token punctuation">(</span> <span class="token number">100</span> <span class="token punctuation">,</span> <span class="token number">10</span> <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">forward</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">:</span> x <span class="token operator">=</span> x <span class="token punctuation">.</span> view <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">784</span> <span class="token punctuation">)</span> x <span class="token operator">=</span> F <span class="token punctuation">.</span> relu <span class="token punctuation">(</span> self <span class="token punctuation">.</span> fc1 <span class="token punctuation">(</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> x <span class="token operator">=</span> F <span class="token punctuation">.</span> relu <span class="token punctuation">(</span> self <span class="token punctuation">.</span> fc2 <span class="token punctuation">(</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> x <span class="token operator">=</span> F <span class="token punctuation">.</span> log_softmax <span class="token punctuation">(</span> self <span class="token punctuation">.</span> fc3 <span class="token punctuation">(</span> x <span class="token punctuation">)</span> <span class="token punctuation">,</span> dim <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> x |
Simply connect all the modules together, just like the common classification problems, guys. This network consists of 3 fully connected classes (which is the instance of the MaskedLinear class installed in the front). These 3 layers connect to each other to form our network.
Install some hyperparemeter
Before entering the training network, you need to define the necessary parameters of the model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | <span class="token comment"># Define some const</span> BATCH_SIZE <span class="token operator">=</span> <span class="token number">128</span> EPOCHS <span class="token operator">=</span> <span class="token number">100</span> LEARNING_RATE <span class="token operator">=</span> <span class="token number">0.001</span> USE_CUDA <span class="token operator">=</span> <span class="token boolean">True</span> SEED <span class="token operator">=</span> <span class="token number">42</span> LOG_AFTER <span class="token operator">=</span> <span class="token number">10</span> <span class="token comment"># How many batches to wait before logging training status</span> LOG_FILE <span class="token operator">=</span> <span class="token string">'log_prunting.txt'</span> SENSITIVITY <span class="token operator">=</span> <span class="token number">2</span> <span class="token comment"># Sensitivity value that is multiplied to layer's std in order to get threshold value</span> <span class="token comment"># Control Seed</span> torch <span class="token punctuation">.</span> manual_seed <span class="token punctuation">(</span> SEED <span class="token punctuation">)</span> <span class="token comment"># Select Device</span> use_cuda <span class="token operator">=</span> USE_CUDA <span class="token operator">and</span> torch <span class="token punctuation">.</span> cuda <span class="token punctuation">.</span> is_available <span class="token punctuation">(</span> <span class="token punctuation">)</span> device <span class="token operator">=</span> torch <span class="token punctuation">.</span> device <span class="token punctuation">(</span> <span class="token string">"cuda"</span> <span class="token keyword">if</span> use_cuda <span class="token keyword">else</span> <span class="token string">'cpu'</span> <span class="token punctuation">)</span> |
Install dataloader
In this article, he will use the familiar MNIST dataset to make the training speed faster. The grandchildren install with transforms of PyTorch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | <span class="token comment"># Create the dataset with MNIST</span> <span class="token keyword">from</span> torchvision <span class="token keyword">import</span> datasets <span class="token punctuation">,</span> transforms <span class="token comment"># Train loader</span> kwargs <span class="token operator">=</span> <span class="token punctuation">{</span> <span class="token string">'num_workers'</span> <span class="token punctuation">:</span> <span class="token number">5</span> <span class="token punctuation">,</span> <span class="token string">'pin_memory'</span> <span class="token punctuation">:</span> <span class="token boolean">True</span> <span class="token punctuation">}</span> <span class="token keyword">if</span> use_cuda <span class="token keyword">else</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> train_loader <span class="token operator">=</span> torch <span class="token punctuation">.</span> utils <span class="token punctuation">.</span> data <span class="token punctuation">.</span> DataLoader <span class="token punctuation">(</span> datasets <span class="token punctuation">.</span> MNIST <span class="token punctuation">(</span> <span class="token string">'data'</span> <span class="token punctuation">,</span> train <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> download <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> transform <span class="token operator">=</span> transforms <span class="token punctuation">.</span> Compose <span class="token punctuation">(</span> <span class="token punctuation">[</span> transforms <span class="token punctuation">.</span> ToTensor <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> transforms <span class="token punctuation">.</span> Normalize <span class="token punctuation">(</span> <span class="token punctuation">(</span> <span class="token number">0.1307</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token punctuation">(</span> <span class="token number">0.3081</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> BATCH_SIZE <span class="token punctuation">,</span> shuffle <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> <span class="token operator">**</span> kwargs <span class="token punctuation">)</span> <span class="token comment"># Test loader</span> test_loader <span class="token operator">=</span> torch <span class="token punctuation">.</span> utils <span class="token punctuation">.</span> data <span class="token punctuation">.</span> DataLoader <span class="token punctuation">(</span> datasets <span class="token punctuation">.</span> MNIST <span class="token punctuation">(</span> <span class="token string">'data'</span> <span class="token punctuation">,</span> train <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> transform <span class="token operator">=</span> transforms <span class="token punctuation">.</span> Compose <span class="token punctuation">(</span> <span class="token punctuation">[</span> transforms <span class="token punctuation">.</span> ToTensor <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> transforms <span class="token punctuation">.</span> Normalize <span class="token punctuation">(</span> <span class="token punctuation">(</span> <span class="token number">0.1307</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token punctuation">(</span> <span class="token number">0.3081</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> BATCH_SIZE <span class="token punctuation">,</span> shuffle <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> <span class="token operator">**</span> kwargs <span class="token punctuation">)</span> |
Then define the model to prepare for the training step
1 2 | model <span class="token operator">=</span> LeNet <span class="token punctuation">(</span> mask <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> |
Definition of optimizer
You use the familiar Adam Optimizer in the classification problem
1 2 3 4 5 6 | <span class="token keyword">import</span> torch <span class="token punctuation">.</span> optim <span class="token keyword">as</span> optim <span class="token comment"># Define optimizer with Adam function</span> optimizer <span class="token operator">=</span> optim <span class="token punctuation">.</span> Adam <span class="token punctuation">(</span> model <span class="token punctuation">.</span> parameters <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> lr <span class="token operator">=</span> LEARNING_RATE <span class="token punctuation">,</span> weight_decay <span class="token operator">=</span> <span class="token number">0.0001</span> <span class="token punctuation">)</span> initial_optimizer_state_dict <span class="token operator">=</span> optimizer <span class="token punctuation">.</span> state_dict <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
Training model
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | <span class="token keyword">from</span> tqdm <span class="token keyword">import</span> tqdm <span class="token comment"># Define training function </span> <span class="token keyword">def</span> <span class="token function">train</span> <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token punctuation">:</span> model <span class="token punctuation">.</span> train <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> epoch <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> EPOCHS <span class="token punctuation">)</span> <span class="token punctuation">:</span> pbar <span class="token operator">=</span> tqdm <span class="token punctuation">(</span> <span class="token builtin">enumerate</span> <span class="token punctuation">(</span> train_loader <span class="token punctuation">)</span> <span class="token punctuation">,</span> total <span class="token operator">=</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> train_loader <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> batch_idx <span class="token punctuation">,</span> <span class="token punctuation">(</span> data <span class="token punctuation">,</span> target <span class="token punctuation">)</span> <span class="token keyword">in</span> pbar <span class="token punctuation">:</span> data <span class="token punctuation">,</span> target <span class="token operator">=</span> data <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> <span class="token punctuation">,</span> target <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> optimizer <span class="token punctuation">.</span> zero_grad <span class="token punctuation">(</span> <span class="token punctuation">)</span> output <span class="token operator">=</span> model <span class="token punctuation">(</span> data <span class="token punctuation">)</span> loss <span class="token operator">=</span> F <span class="token punctuation">.</span> nll_loss <span class="token punctuation">(</span> output <span class="token punctuation">,</span> target <span class="token punctuation">)</span> loss <span class="token punctuation">.</span> backward <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token comment"># zero-out all the gradients corresponding to the pruned connections</span> <span class="token keyword">for</span> name <span class="token punctuation">,</span> p <span class="token keyword">in</span> model <span class="token punctuation">.</span> named_parameters <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'mask'</span> <span class="token keyword">in</span> name <span class="token punctuation">:</span> <span class="token keyword">continue</span> tensor <span class="token operator">=</span> p <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> grad_tensor <span class="token operator">=</span> p <span class="token punctuation">.</span> grad <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> grad_tensor <span class="token operator">=</span> np <span class="token punctuation">.</span> where <span class="token punctuation">(</span> tensor <span class="token operator">==</span> <span class="token number">0</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> grad_tensor <span class="token punctuation">)</span> p <span class="token punctuation">.</span> grad <span class="token punctuation">.</span> data <span class="token operator">=</span> torch <span class="token punctuation">.</span> from_numpy <span class="token punctuation">(</span> grad_tensor <span class="token punctuation">)</span> <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> optimizer <span class="token punctuation">.</span> step <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">if</span> batch_idx <span class="token operator">%</span> LOG_AFTER <span class="token operator">==</span> <span class="token number">0</span> <span class="token punctuation">:</span> done <span class="token operator">=</span> batch_idx <span class="token operator">*</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> data <span class="token punctuation">)</span> percentage <span class="token operator">=</span> <span class="token number">100</span> <span class="token punctuation">.</span> <span class="token operator">*</span> batch_idx <span class="token operator">/</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> train_loader <span class="token punctuation">)</span> pbar <span class="token punctuation">.</span> set_description <span class="token punctuation">(</span> f <span class="token string">'Train Epoch: {epoch} [{done:5}/{len(train_loader.dataset)} ({percentage:3.0f}%)] Loss: {loss.item():.6f}'</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> model |
This is an important step, after we have reached the architecture of the model, the model training is also very important. Especially training model after pruning, you pay attention to the code below
1 2 3 4 5 6 7 8 9 | <span class="token comment"># zero-out all the gradients corresponding to the pruned connections</span> <span class="token keyword">for</span> name <span class="token punctuation">,</span> p <span class="token keyword">in</span> model <span class="token punctuation">.</span> named_parameters <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'mask'</span> <span class="token keyword">in</span> name <span class="token punctuation">:</span> <span class="token keyword">continue</span> tensor <span class="token operator">=</span> p <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> grad_tensor <span class="token operator">=</span> p <span class="token punctuation">.</span> grad <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> grad_tensor <span class="token operator">=</span> np <span class="token punctuation">.</span> where <span class="token punctuation">(</span> tensor <span class="token operator">==</span> <span class="token number">0</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> grad_tensor <span class="token punctuation">)</span> p <span class="token punctuation">.</span> grad <span class="token punctuation">.</span> data <span class="token operator">=</span> torch <span class="token punctuation">.</span> from_numpy <span class="token punctuation">(</span> grad_tensor <span class="token punctuation">)</span> <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> |
This code executes all derivatives of the trimmed weights to 0 so the optimizer will ignore those weights. Please note that this function will not run during the first training, but will run after the network has been trimmed and needs fine tuning. Its purpose is to help the optimizer only optimize on the pruned weights (important). After building this function, you proceed to training according to the command:
1 2 | model <span class="token operator">=</span> train <span class="token punctuation">(</span> model <span class="token punctuation">)</span> |
Make a cup of coffee and wait for the model to run
1 2 3 4 5 6 7 | Train Epoch: 94 [58880/60000 ( 98%)] Loss: 0.005322: 100%|██████████| 469/469 [00:02<00:00, 165.10it/s] Train Epoch: 95 [58880/60000 ( 98%)] Loss: 0.019957: 100%|██████████| 469/469 [00:02<00:00, 163.42it/s] Train Epoch: 96 [58880/60000 ( 98%)] Loss: 0.009064: 100%|██████████| 469/469 [00:02<00:00, 169.39it/s] Train Epoch: 97 [58880/60000 ( 98%)] Loss: 0.001462: 100%|██████████| 469/469 [00:02<00:00, 166.62it/s] Train Epoch: 98 [58880/60000 ( 98%)] Loss: 0.043480: 100%|██████████| 469/469 [00:02<00:00, 161.13it/s] Train Epoch: 99 [58880/60000 ( 98%)] Loss: 0.046619: 100%|██████████| 469/469 [00:02<00:00, 167.76it/s] |
Testing model
After training the children have obtained a model, the next need to test the model and check the number of parameters other than 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | <span class="token keyword">from</span> time <span class="token keyword">import</span> time <span class="token keyword">def</span> <span class="token function">test</span> <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token punctuation">:</span> start_time <span class="token operator">=</span> time <span class="token punctuation">(</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> <span class="token builtin">eval</span> <span class="token punctuation">(</span> <span class="token punctuation">)</span> test_loss <span class="token operator">=</span> <span class="token number">0</span> correct <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">with</span> torch <span class="token punctuation">.</span> no_grad <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> data <span class="token punctuation">,</span> target <span class="token keyword">in</span> test_loader <span class="token punctuation">:</span> data <span class="token punctuation">,</span> target <span class="token operator">=</span> data <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> <span class="token punctuation">,</span> target <span class="token punctuation">.</span> to <span class="token punctuation">(</span> device <span class="token punctuation">)</span> output <span class="token operator">=</span> model <span class="token punctuation">(</span> data <span class="token punctuation">)</span> test_loss <span class="token operator">+=</span> F <span class="token punctuation">.</span> nll_loss <span class="token punctuation">(</span> output <span class="token punctuation">,</span> target <span class="token punctuation">,</span> reduction <span class="token operator">=</span> <span class="token string">'sum'</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> item <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token comment"># sum up batch loss</span> pred <span class="token operator">=</span> output <span class="token punctuation">.</span> data <span class="token punctuation">.</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token punctuation">,</span> keepdim <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token comment"># get the index of the max log-probability</span> correct <span class="token operator">+=</span> pred <span class="token punctuation">.</span> eq <span class="token punctuation">(</span> target <span class="token punctuation">.</span> data <span class="token punctuation">.</span> view_as <span class="token punctuation">(</span> pred <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> <span class="token builtin">sum</span> <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> item <span class="token punctuation">(</span> <span class="token punctuation">)</span> test_loss <span class="token operator">/=</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> test_loader <span class="token punctuation">.</span> dataset <span class="token punctuation">)</span> accuracy <span class="token operator">=</span> <span class="token number">100</span> <span class="token punctuation">.</span> <span class="token operator">*</span> correct <span class="token operator">/</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> test_loader <span class="token punctuation">.</span> dataset <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> f <span class="token string">'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%). Total time = {time() - start_time}'</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> accuracy |
This function is also very basic, you just run it
1 2 | accuracy <span class="token operator">=</span> test <span class="token punctuation">(</span> model <span class="token punctuation">)</span> |
The following results will be obtained:
1 2 | Test <span class="token builtin">set</span> <span class="token punctuation">:</span> Average loss <span class="token punctuation">:</span> <span class="token number">0.0758</span> <span class="token punctuation">,</span> Accuracy <span class="token punctuation">:</span> <span class="token number">9818</span> <span class="token operator">/</span> <span class="token number">10000</span> <span class="token punctuation">(</span> <span class="token number">98.18</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> Total time <span class="token operator">=</span> <span class="token number">0.545386552810669</span> |
Then you can save this log value to a file to track for convenience
1 2 3 4 5 | <span class="token keyword">def</span> <span class="token function">save_log</span> <span class="token punctuation">(</span> filename <span class="token punctuation">,</span> content <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">with</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> filename <span class="token punctuation">,</span> <span class="token string">'a'</span> <span class="token punctuation">)</span> <span class="token keyword">as</span> f <span class="token punctuation">:</span> content <span class="token operator">+=</span> <span class="token string">"n"</span> f <span class="token punctuation">.</span> write <span class="token punctuation">(</span> content <span class="token punctuation">)</span> |
And make a save wieght of the model
1 2 3 | save_log <span class="token punctuation">(</span> LOG_FILE <span class="token punctuation">,</span> f <span class="token string">"initial_accuracy {accuracy}"</span> <span class="token punctuation">)</span> torch <span class="token punctuation">.</span> save <span class="token punctuation">(</span> model <span class="token punctuation">,</span> f <span class="token string">"save_models/initial_model.ptmodel"</span> <span class="token punctuation">)</span> |
Calculate the number of non-zeros parameters
This makes sense and is essential for children to decide which layers to trim
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <span class="token comment"># Print number of non-zeros weight in model </span> <span class="token keyword">def</span> <span class="token function">print_nonzeros</span> <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token punctuation">:</span> nonzero <span class="token operator">=</span> total <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> name <span class="token punctuation">,</span> p <span class="token keyword">in</span> model <span class="token punctuation">.</span> named_parameters <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'mask'</span> <span class="token keyword">in</span> name <span class="token punctuation">:</span> <span class="token keyword">continue</span> tensor <span class="token operator">=</span> p <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> nz_count <span class="token operator">=</span> np <span class="token punctuation">.</span> count_nonzero <span class="token punctuation">(</span> tensor <span class="token punctuation">)</span> total_params <span class="token operator">=</span> np <span class="token punctuation">.</span> prod <span class="token punctuation">(</span> tensor <span class="token punctuation">.</span> shape <span class="token punctuation">)</span> nonzero <span class="token operator">+=</span> nz_count total <span class="token operator">+=</span> total_params <span class="token keyword">print</span> <span class="token punctuation">(</span> f <span class="token string">'{name:20} | nonzeros = {nz_count:7} / {total_params:7} ({100 * nz_count / total_params:6.2f}%) | total_pruned = {total_params - nz_count :7} | shape = {tensor.shape}'</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> f <span class="token string">'alive: {nonzero}, pruned : {total - nonzero}, total: {total}, Compression rate : {total/nonzero:10.2f}x ({100 * (total-nonzero) / total:6.2f}% pruned)'</span> <span class="token punctuation">)</span> |
Then test run
1 2 | print_nonzeros <span class="token punctuation">(</span> model <span class="token punctuation">)</span> |
You can get the following result:
1 2 3 4 5 6 7 8 | fc1.weight | nonzeros = 235200 / 235200 (100.00%) | total_pruned = 0 | shape = (300, 784) fc1.bias | nonzeros = 300 / 300 (100.00%) | total_pruned = 0 | shape = (300,) fc2.weight | nonzeros = 30000 / 30000 (100.00%) | total_pruned = 0 | shape = (100, 300) fc2.bias | nonzeros = 100 / 100 (100.00%) | total_pruned = 0 | shape = (100,) fc3.weight | nonzeros = 1000 / 1000 (100.00%) | total_pruned = 0 | shape = (10, 100) fc3.bias | nonzeros = 10 / 10 (100.00%) | total_pruned = 0 | shape = (10,) alive: 266610, pruned : 0, total: 266610, Compression rate : 1.00x ( 0.00% pruned) |
It can be seen that when not pruned, this network has all weights that are nonzero.
Proceed to pruning
Run a single command
1 2 3 4 5 6 7 | <span class="token comment"># Pruning</span> model <span class="token punctuation">.</span> prune_by_std <span class="token punctuation">(</span> SENSITIVITY <span class="token punctuation">)</span> <span class="token operator">>></span> <span class="token operator">></span> Output Pruning <span class="token keyword">with</span> threshold <span class="token punctuation">:</span> <span class="token number">0.07490971684455872</span> <span class="token keyword">for</span> layer fc1 Pruning <span class="token keyword">with</span> threshold <span class="token punctuation">:</span> <span class="token number">0.11689116805791855</span> <span class="token keyword">for</span> layer fc2 Pruning <span class="token keyword">with</span> threshold <span class="token punctuation">:</span> <span class="token number">0.37801066040992737</span> <span class="token keyword">for</span> layer fc3 |
Then test it again to see how much accuracy has been reduced
1 2 3 4 | accuracy <span class="token operator">=</span> test <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token operator">>></span> <span class="token operator">></span> Output Test <span class="token builtin">set</span> <span class="token punctuation">:</span> Average loss <span class="token punctuation">:</span> <span class="token number">1.2319</span> <span class="token punctuation">,</span> Accuracy <span class="token punctuation">:</span> <span class="token number">5805</span> <span class="token operator">/</span> <span class="token number">10000</span> <span class="token punctuation">(</span> <span class="token number">58.05</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> Total time <span class="token operator">=</span> <span class="token number">0.6268196105957031</span> |
Save the results to the log file and double check the number of parameters of the network
1 2 3 4 5 6 7 8 9 10 11 12 | save_log <span class="token punctuation">(</span> LOG_FILE <span class="token punctuation">,</span> f <span class="token string">"accuracy_after_pruning {accuracy}"</span> <span class="token punctuation">)</span> print_nonzeros <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token operator">>></span> <span class="token operator">></span> Output fc1 <span class="token punctuation">.</span> weight <span class="token operator">|</span> nonzeros <span class="token operator">=</span> <span class="token number">13395</span> <span class="token operator">/</span> <span class="token number">235200</span> <span class="token punctuation">(</span> <span class="token number">5.70</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token operator">|</span> total_pruned <span class="token operator">=</span> <span class="token number">221805</span> <span class="token operator">|</span> shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">300</span> <span class="token punctuation">,</span> <span class="token number">784</span> <span class="token punctuation">)</span> fc1 <span class="token punctuation">.</span> bias <span class="token operator">|</span> nonzeros <span class="token operator">=</span> <span class="token number">300</span> <span class="token operator">/</span> <span class="token number">300</span> <span class="token punctuation">(</span> <span class="token number">100.00</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token operator">|</span> total_pruned <span class="token operator">=</span> <span class="token number">0</span> <span class="token operator">|</span> shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">300</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> fc2 <span class="token punctuation">.</span> weight <span class="token operator">|</span> nonzeros <span class="token operator">=</span> <span class="token number">2100</span> <span class="token operator">/</span> <span class="token number">30000</span> <span class="token punctuation">(</span> <span class="token number">7.00</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token operator">|</span> total_pruned <span class="token operator">=</span> <span class="token number">27900</span> <span class="token operator">|</span> shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">100</span> <span class="token punctuation">,</span> <span class="token number">300</span> <span class="token punctuation">)</span> fc2 <span class="token punctuation">.</span> bias <span class="token operator">|</span> nonzeros <span class="token operator">=</span> <span class="token number">100</span> <span class="token operator">/</span> <span class="token number">100</span> <span class="token punctuation">(</span> <span class="token number">100.00</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token operator">|</span> total_pruned <span class="token operator">=</span> <span class="token number">0</span> <span class="token operator">|</span> shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">100</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> fc3 <span class="token punctuation">.</span> weight <span class="token operator">|</span> nonzeros <span class="token operator">=</span> <span class="token number">59</span> <span class="token operator">/</span> <span class="token number">1000</span> <span class="token punctuation">(</span> <span class="token number">5.90</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token operator">|</span> total_pruned <span class="token operator">=</span> <span class="token number">941</span> <span class="token operator">|</span> shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">10</span> <span class="token punctuation">,</span> <span class="token number">100</span> <span class="token punctuation">)</span> fc3 <span class="token punctuation">.</span> bias <span class="token operator">|</span> nonzeros <span class="token operator">=</span> <span class="token number">10</span> <span class="token operator">/</span> <span class="token number">10</span> <span class="token punctuation">(</span> <span class="token number">100.00</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token operator">|</span> total_pruned <span class="token operator">=</span> <span class="token number">0</span> <span class="token operator">|</span> shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">10</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> alive <span class="token punctuation">:</span> <span class="token number">15964</span> <span class="token punctuation">,</span> pruned <span class="token punctuation">:</span> <span class="token number">250646</span> <span class="token punctuation">,</span> total <span class="token punctuation">:</span> <span class="token number">266610</span> <span class="token punctuation">,</span> Compression rate <span class="token punctuation">:</span> <span class="token number">16.</span> 70x <span class="token punctuation">(</span> <span class="token number">94.01</span> <span class="token operator">%</span> pruned <span class="token punctuation">)</span> |
You see that the model is reducing accuracy quite a lot, from 98.18% to 58.05% while the number of parameters is trimmed is 94.01% corresponding to the compression ratio of about 16 times. Our next thing to do is to retrain it. Also by a single command
1 2 3 4 5 | <span class="token comment"># Retraining</span> optimizer <span class="token punctuation">.</span> load_state_dict <span class="token punctuation">(</span> initial_optimizer_state_dict <span class="token punctuation">)</span> <span class="token comment"># Reset the optimizer</span> model <span class="token operator">=</span> train <span class="token punctuation">(</span> model <span class="token punctuation">)</span> |
Sit back and drink coffee and wait for the results. After the training is complete, you will retest the accuracy of the model
1 2 3 4 5 | accuracy <span class="token operator">=</span> test <span class="token punctuation">(</span> model <span class="token punctuation">)</span> <span class="token operator">>></span> <span class="token operator">></span> Output Test <span class="token builtin">set</span> <span class="token punctuation">:</span> Average loss <span class="token punctuation">:</span> <span class="token number">0.0800</span> <span class="token punctuation">,</span> Accuracy <span class="token punctuation">:</span> <span class="token number">9839</span> <span class="token operator">/</span> <span class="token number">10000</span> <span class="token punctuation">(</span> <span class="token number">98.39</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> Total time <span class="token operator">=</span> <span class="token number">0.5431315898895264</span> |
Have you seen the miracle yet, the accuracy is a little higher than the original model while the compression ratio of the model is 16 times already. If you continue to save logs, we will finish the trimming of the model
1 2 3 | save_log <span class="token punctuation">(</span> LOG_FILE <span class="token punctuation">,</span> f <span class="token string">"accuracy_after_retraining {accuracy}"</span> <span class="token punctuation">)</span> torch <span class="token punctuation">.</span> save <span class="token punctuation">(</span> model <span class="token punctuation">,</span> f <span class="token string">"save_models/model_after_retraining.ptmodel"</span> <span class="token punctuation">)</span> |
Next to proceed to increase the compression ratio we will come to quantization and share weight.
Quantization and Share weight
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> cluster <span class="token keyword">import</span> KMeans <span class="token keyword">from</span> scipy <span class="token punctuation">.</span> sparse <span class="token keyword">import</span> csc_matrix <span class="token punctuation">,</span> csr_matrix <span class="token keyword">def</span> <span class="token function">apply_weight_sharing</span> <span class="token punctuation">(</span> model <span class="token punctuation">,</span> bits <span class="token operator">=</span> <span class="token number">5</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> module <span class="token keyword">in</span> model <span class="token punctuation">.</span> children <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> dev <span class="token operator">=</span> module <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> device weight <span class="token operator">=</span> module <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> data <span class="token punctuation">.</span> cpu <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> numpy <span class="token punctuation">(</span> <span class="token punctuation">)</span> shape <span class="token operator">=</span> weight <span class="token punctuation">.</span> shape mat <span class="token operator">=</span> csr_matrix <span class="token punctuation">(</span> weight <span class="token punctuation">)</span> <span class="token keyword">if</span> shape <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token operator"><</span> shape <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token keyword">else</span> csc_matrix <span class="token punctuation">(</span> weight <span class="token punctuation">)</span> min_ <span class="token operator">=</span> <span class="token builtin">min</span> <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> data <span class="token punctuation">)</span> max_ <span class="token operator">=</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> data <span class="token punctuation">)</span> space <span class="token operator">=</span> np <span class="token punctuation">.</span> linspace <span class="token punctuation">(</span> min_ <span class="token punctuation">,</span> max_ <span class="token punctuation">,</span> num <span class="token operator">=</span> <span class="token number">2</span> <span class="token operator">**</span> bits <span class="token punctuation">)</span> kmeans <span class="token operator">=</span> KMeans <span class="token punctuation">(</span> n_clusters <span class="token operator">=</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> space <span class="token punctuation">)</span> <span class="token punctuation">,</span> init <span class="token operator">=</span> space <span class="token punctuation">.</span> reshape <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> n_init <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">,</span> precompute_distances <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> algorithm <span class="token operator">=</span> <span class="token string">"full"</span> <span class="token punctuation">)</span> kmeans <span class="token punctuation">.</span> fit <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> data <span class="token punctuation">.</span> reshape <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> new_weight <span class="token operator">=</span> kmeans <span class="token punctuation">.</span> cluster_centers_ <span class="token punctuation">[</span> kmeans <span class="token punctuation">.</span> labels_ <span class="token punctuation">]</span> <span class="token punctuation">.</span> reshape <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">)</span> mat <span class="token punctuation">.</span> data <span class="token operator">=</span> new_weight module <span class="token punctuation">.</span> weight <span class="token punctuation">.</span> data <span class="token operator">=</span> torch <span class="token punctuation">.</span> from_numpy <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> toarray <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> to <span class="token punctuation">(</span> dev <span class="token punctuation">)</span> <span class="token keyword">return</span> model |
Explain a little more about this function. There are a few points to note
- Stored in compressed sparse row (CSR) or compressed sparse column (CSC) format, these are two formats for sparse matrix storage for easy calculation due to memory savings. Do you remember that their weight is a very sparse matrix with 94% of the weights being different from zero? Therefore, an appropriate structure is needed to store and calculate. He did not explain the format in depth, if necessary you can find out for yourself here .
- Using Kmean to cluster : This is done in the following function
1 2 3 4 5 6 7 | min_ <span class="token operator">=</span> <span class="token builtin">min</span> <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> data <span class="token punctuation">)</span> max_ <span class="token operator">=</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> data <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> min_ <span class="token punctuation">,</span> max_ <span class="token punctuation">)</span> space <span class="token operator">=</span> np <span class="token punctuation">.</span> linspace <span class="token punctuation">(</span> min_ <span class="token punctuation">,</span> max_ <span class="token punctuation">,</span> num <span class="token operator">=</span> <span class="token number">2</span> <span class="token operator">**</span> bits <span class="token punctuation">)</span> kmeans <span class="token operator">=</span> KMeans <span class="token punctuation">(</span> n_clusters <span class="token operator">=</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> space <span class="token punctuation">)</span> <span class="token punctuation">,</span> init <span class="token operator">=</span> space <span class="token punctuation">.</span> reshape <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> n_init <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">,</span> precompute_distances <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> algorithm <span class="token operator">=</span> <span class="token string">"full"</span> <span class="token punctuation">)</span> kmeans <span class="token punctuation">.</span> fit <span class="token punctuation">(</span> mat <span class="token punctuation">.</span> data <span class="token punctuation">.</span> reshape <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> |
Here the number of bits used to store the weight values is 5. Therefore you will have a maximum of
2 5 = 32 2 ^ 5 = 32 clusters of Kmeans. After performing clustering, then you share centroid to the weight position with the function
1 2 | new_weight <span class="token operator">=</span> kmeans <span class="token punctuation">.</span> cluster_centers_ <span class="token punctuation">[</span> kmeans <span class="token punctuation">.</span> labels_ <span class="token punctuation">]</span> <span class="token punctuation">.</span> reshape <span class="token punctuation">(</span> <span class="token operator">-</span> <span class="token number">1</span> <span class="token punctuation">)</span> |
After carrying out the share weight, you need to recalculate the accuracy
1 2 3 | accuracy <span class="token operator">=</span> test <span class="token punctuation">(</span> model <span class="token punctuation">)</span> Test <span class="token builtin">set</span> <span class="token punctuation">:</span> Average loss <span class="token punctuation">:</span> <span class="token number">0.0705</span> <span class="token punctuation">,</span> Accuracy <span class="token punctuation">:</span> <span class="token number">9840</span> <span class="token operator">/</span> <span class="token number">10000</span> <span class="token punctuation">(</span> <span class="token number">98.40</span> <span class="token operator">%</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> Total time <span class="token operator">=</span> <span class="token number">0.5958971977233887</span> |
Can see the accuracy after the share weight slightly better than before the share weight. This is also the case, the kids are not always higher. If the results are worse, you should review the pruning thresholds so that the result after fine tune is as high as possible.
Conclude
The technique of modeling compression is one of the very good and important techniques in the deploy step. This technique makes it possible to deploy the model to low-profile hardware, taking advantage of the computer memory’s storage space. For other networks, the model size after decompression is greatly reduced. You can see an example in the following picture:

Hopefully, with this article, you will be able to perform operations related to model pruning yourself. Goodbye everyone and see you in the next post