Hello to all of you, it is great to see each other in the articles on the topic of AI. Today is not the same as every time, it is not about discussing a specific problem, nor is it a good question to use when interviewing technology (when will I have time to write later) . But the topic today I want to discuss is close to doing a more realistic problem and this I think will be very helpful for the project team or you are pursuing employment AI In reality. This is not a common process for all teams but is a step-by-step process that I think is quite suitable for a deployed software application with AI that you can refer to. Ok, no longer will we start now.
Step 1: Understand the problem
This is a very important step, AI is not a new field, but it cannot be admitted that many people are misunderstanding it. Maybe their level of misunderstanding in terms of problem solving or the power of this technology. I have seen a lot of people talk about AI as something very high, beyond human ability to even do things that only God can do as an AI to make Ngoc Trinh have to propose to you And because there are so many misunderstandings, when working with customers (especially non-tech customers) it is normal to get requests (specs) in the sky. What you need to do is explain, analyze and make the exact requirements between yourself and your customers. Consideration should be given to the level of feasibility of the technique and the level of practical effectiveness because there is no AI model in nature for absolute accuracy. We need to commit certain ratios (numbers) to the accuracy of the model before embarking on a problem.

Step 2: Design the overview system
This is a very important step when doing any software. Basically you need to answer the following questions to design the system accordingly:
- What is the input / output of the system? This is the question that you need to answer first, which proves that you are very clear about the problem of the problem. For example, handwriting recognition problem, what are input and output? Many of you will immediately answer that the input is of course an image and the output is handwriting. Oh, that sounds simple, but that is standing at the end user’s perspective. In technical view, you need to clarify this input and output. The input example may be an image (file format) or path (URL), or an encoded Base64 string. The output of the system of being a JSON contains the result that the word is identified in the image. With each of those requirements, we will design the system accordingly.
- On which platform is the system run? There are many friends right after receiving the request of the problem of building face recognition system, they immediately went to search for data and training model so as to achieve the highest results. You use a CNN network up to several tens of millions of parameters to achieve the best results and patting your chest proudly that your model is very good and can be put into practice right away. However, when it was time to run on a Rapsbery Pi, did it start the program one by one, but the system was stopped because the model was too heavy, let alone predict the good? So you need to explicitly define the environment to implement and deploy the problem. You can do experiments with dozens of gigantic GPUs, but that doesn’t mean you have to ask for that in a test environment.
- How does the new data update take place? A created AI model may be right and good at the present time, but does not mean that it will be right and good in the future when data changes constantly. So we need to consider how to update new data. Updating the model when the data changes is a fairly long problem and we will discuss it further in the next sections. However, the system design must ensure that your AI model always responds to constantly updated data.
Step 3: Make a survey of methods to perform problems
There is a situation of new learners or new AI workers who are too focused on testing models but forget about something we still do from the bottom of our feet to the field. This is search and survey solutions. Even if you have experience with similar problems, do not jump into experimenting with models right away, so make a survey of the methods to do that first.

Benefits of job survey
This has some of the following benefits:
- Update new technology: even if you have experienced this problem for many years, it does not mean that the method you use is always new. The nature of the survey is to rummage through, find all the new-to-old methods for the current problem, so of course you will have the opportunity to interact with new technologies. Imagine if you were working on a Speech to Text model, people who didn’t know Deep Learning would only think of GMM and HMM. Nothing will change in their system if they do not constantly investigate new technologies.
- Having more background on the issue that no one can be confident that they have the full background of all problems, it is from surveying that you will have to read through a lot of paper, lots of blogs Techniques from them are linked to a lot of paper or other references to help you gain more knowledge.
- Finding new solutions if you are going into a technological path, surveying can help you get new ideas and solutions to a problem.
Surveyable sources
So the question is, what sources do the survey take? Here are some channels that you can refer to:
- Paper and journaling at specialized seminars for a field with many academic elements such as AI, finding information from paper is an indispensable thing. There are many people who do not form the habit of reading the paper and are also a bit lazy because the words in it are not intuitive and easy to understand such as reading a technology tutorial. However, reading the paper is the place that contains the most information because there is no problem you can also have step-by-step tutorial by step and not the problem which is given as a tutorial is also the best solution. However, reading the paper also needs to be filtered to avoid reading the paper shit that takes time and is misleading. It is best to search for paper at the top technology workshops of that area or follow famous publishers in the field such as IEEE or Springer …
- The textbook reading books gives you the most general concepts of the field being studied, though it may not be the latest knowledge like paper. However, the information given in the textbook is standard, not worrying about quality.
- Technology blogs can sometimes refer to technology blogs with a few articles related to what you are doing. However, one disadvantage of these types of blogs is often more instructive , so it is difficult to understand a problem well. Not to mention the content on these blogs often does not give us the best solution . This is easy to understand, if you want to have a good solution, you have to work hard and study. No free lunch
- Github you can refer to the solutions presented in the repo published on giithub and this has an advantage that you can read the source code directly and try installing them. This is also a good way if combined with a specific paper. This makes us more interested in reading paper. However, I still advise people to read the paper in combination with running the code to avoid falling into the situation of not understanding the nature of the problem that leads to running but it is difficult to maintain if there is a change.
After completing the survey, we will select the method and try to implement it to select the best method with our problem.
Example of a survey form
A survey form in a specific AI problem should contain the following sections:
- Name of the study : The name of the research that we are surveying and should follow the link on the network (if available)
- Research-related links If there are current research-related references, it is necessary to clearly list the references and concepts related to it.
- The main purpose of the study best describes the purpose of research after survey, usually a summary of the work done in that research.
- The results achieved are the results of the study, note that the results will be done on a certain data set and to avoid misunderstandings, the data set must be stated.
- Advantages and disadvantages, relevance to the problem of assessing the most general advantages and disadvantages of the level consistent with the current problem.
Step 4: Make data
 There is an indisputable fact that data making is the most important step of every AI system. You can use a simple model to solve the problem as long as you have a good enough data set. Doing data also often tells your team a lot of time and meticulously. You can carefully study your problem and choose the strategy to make data accordingly. Here are some ways you can consult:
There is an indisputable fact that data making is the most important step of every AI system. You can use a simple model to solve the problem as long as you have a good enough data set. Doing data also often tells your team a lot of time and meticulously. You can carefully study your problem and choose the strategy to make data accordingly. Here are some ways you can consult:
- Finding, asking or buying data sets available with some math problems can still be done in this way but there are some disadvantages that don’t always find the right set of data. my team, or can find it but it is not easy to get or buy. One more thing is that the data files are unlikely to meet the quality needs in the product you are requesting.
- Creating data yourself can help you control the quality of data more and help us proactively focus on the right domain that the problem requires. However, this job also makes us spend a lot of time, you can do it in a way that is done on the whole data or done on the part of the data then training the model to predict the remaining data then validate that data. Depending on the workload and the size of the workforce, we choose the right strategy but no matter how you work, you must ensure the accuracy of the data. This is the most important thing.
Step 5: Training models
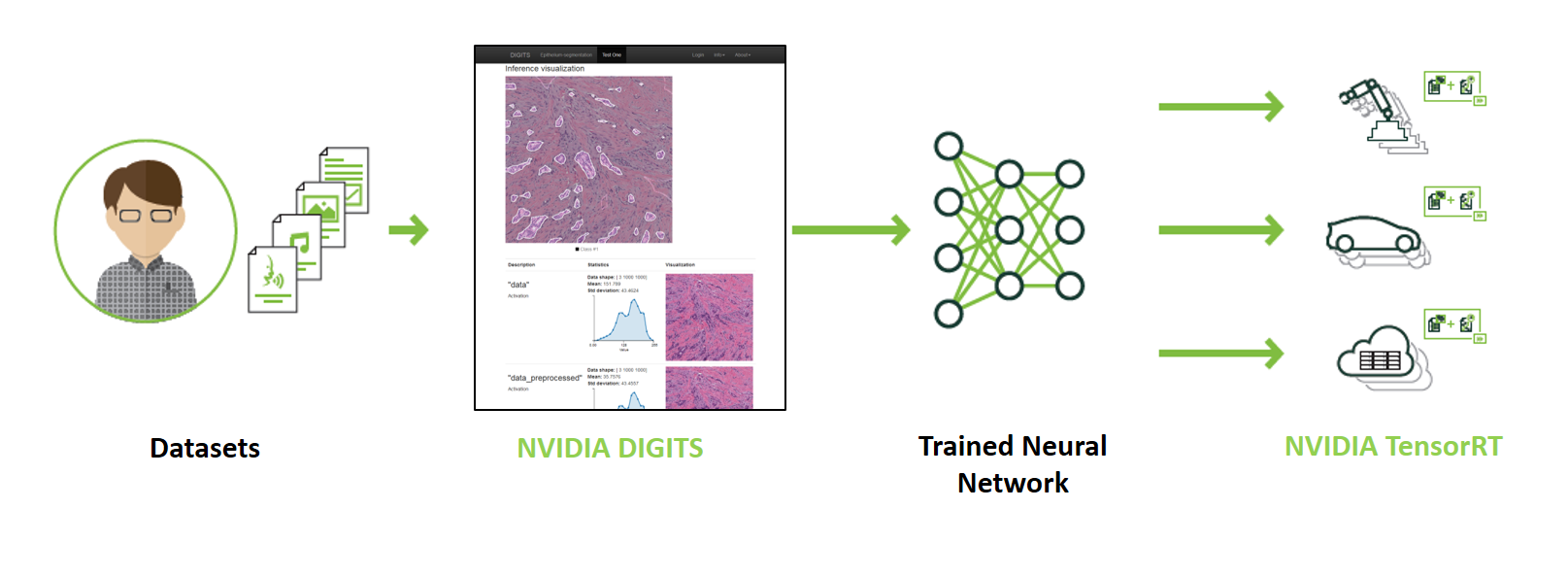
After selecting the training methods and performing on the data sets, the next thing to do is to train the models. A lot of you consider this the most important step but forget that this step only becomes the most important if you have done well above. You should divide the team into small teams to train different models, do experiments and compare results. The training of models depends on the problem but there may still be some general rules for it. Here are a few rules that you can apply in your project:
- If you can try to transfer learning in advance with your problems, if you find the pretrained models, the advice is to test them with the method of transferring learning first. This makes the time to validate the results more quickly, the transfer from a pretrained model often brings better results and the training time is usually faster than the same training model but the The parameter is initialized from the beginning.
- Minimizing the dependency between models of dependency between models is inevitable in a large project. Imagine an example of a system that identifies digital papers (identity cards, red books, passports …). After a survey, you give an overview of the system as follows:
- Step 1: Document classification of a classification model is used to automatically identify your identity papers. Accuracy is 95%
- Step 2: Crop papers a model used to crop and align back papers with an accuracy of 98%
- Step 3: Extract the information an object detection model is used to extract information from that paper with 90% accuracy.
- Step 4: OCR a print recognition model used to identify letters in paper with an accuracy of 90%
This is not worth mentioning if the accuracy of the following steps depends on the accuracy and accuracy of the previous steps, ie the output of the previous step is taken as the following input of the step. You must be very careful and minimize this dependency level. For example, instead of classifying papers, you can split them into modules at the intersection so that users are required to upload the correct papers. This reduces the risk of the system more. And the more this dependency is reduced, the more accurate the training model becomes.
- Balancing the accuracy and speed of adjusting the balance between accuracy and speed is a consideration when selecting training models, depending on your problem requirement and selecting a tissue training picture accordingly.
- Considering this deployment step needs to be clarified and considered carefully before training, there are some models that can only run well when there is a GPU (for example, CuDNNLSTM in Keras for example) that when converted to CPU The result is worse or worse, it cannot be used on other devices. That helps you have a mindset to learn first about the deploy environment before conducting a model training.
Step 6: Evaluate the model
The evaluation of models must be defined internally by the team and ensure the following factors:
- Build a test data set to test the test data to ensure the maximum cover of the cases can be met in practice. Must be built meticulously and independently of the model trianing process.
- Completely independent of test data The test data is completely independent and cannot be used directly or indirectly (creating very small variations) in the model training step. The test division can be used for the whole team to ensure objectivity between models. Testing on the test set is an important step to evaluate whether a model is really good and can be used in practice.
- Always use Confusion Matrix for this classification to make the classification model more objective and help us find out the characteristics of each model. For example, Model A predicts better for class 1, model B better predicts for class 2 …. and that is very convenient for ensemble models later on.

- End users are the best, even if testing on the test set can help you get the application for customers, there is nothing that confirms your model will run well in practice. There is always a feedback listening system from the user to find the improvement directions for your problem.

Step 7: Deploy the system
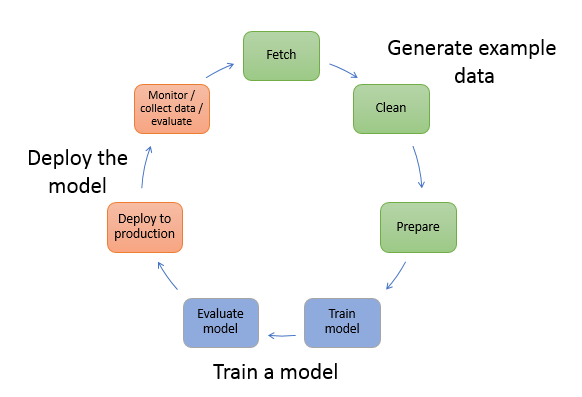
After all, the ultimate goal that users want is to experience an actual AI product without losing too much technology. That is the step we deploy the model. Deploying an AI model system is not too different from other systems; it must still ensure the core elements:
- Limiting the maximum down time in the process of deploying, the down-time occurrence is inevitable so all of our deploying methods as well as updating the model must ensure the maximum time limit that time. This also means that our service can operate at its maximum. (Up time is approximately 100%)
- We have to consider the time of predicting more than once in this article, I mentioned the test of time, which proves that this is one of the most important factors in most current problems when the target real time is being considered by many applications.
- There must be a system to store the data and the results of the model tracking the results of the model help us to plan accordingly to update the model accordingly. Because as mentioned at the beginning, there is no one model that guarantees never wrong every time, every space. So, storing the actual data helps us to add new, unfamiliar cases in history.
- Easy scaling for deploying must ensure that scaling up the system becomes easier and ensures maximum risks during scale up. This makes our application scalable in all conditions and circumstances.
Step 8: Keeping Your Models Up-To-Date
 If you surf the web, you’ll find many tutorials that show you how to train and evaluate AI models. You can even find tutorials that teach you how to deploy those models and make predictions from your end-user applications. However, you will find it difficult to find documents that show you how to maintain those AI systems. You must answer questions like:
If you surf the web, you’ll find many tutorials that show you how to train and evaluate AI models. You can even find tutorials that teach you how to deploy those models and make predictions from your end-user applications. However, you will find it difficult to find documents that show you how to maintain those AI systems. You must answer questions like:
- How do you ensure your prediction continues to correct?
- How do you keep your models updated with new data?
Let’s take an example of predicting house prices. House prices change all the time. The data you used to train machine learning models predicted home prices six months ago can provide false predictions for today. For house prices, it is imperative that you have up-to-date information to train your models. When designing a real AI system, it is important to understand how your data will change over time. A well-structured system takes this into account and must have a plan to keep your models up to date with new data. There are two solutions that you can choose for your system.
Training manual
Basically we will redo the steps that have made the new data to help the model learn better. This is quite time consuming and it will be a little difficult if your team has new people in the project, it will take time to read the model and data flow. Moreover, putting the training time back into the model is also very manual like daily training, weekly, monthly …. and you have to divide the resource for that. However, this method has an advantage that when you retrain your models yourself, you can discover a new algorithm or a new feature set of data that provides improved accuracy.
Continuous learning
Another way to keep your models up to date is to have an automated system to continually evaluate and retrain your models. This type of system is often called continuous learning and is often designed as follows:
- Save new training data when you receive it. For example, if you are getting updated home prices in the market, save that information in the database.
- When you have enough new data, check its accuracy for your old model.
- If you find the accuracy of your model has decreased accuracy over time, use new data or combine new data and old training data to build and deploy a new model.
The benefit of designing this system is that it can be updated continuously and completely automatically. Some cloud like IBM Watson also supports this re-training form. In system design step you should clarify this first to consider infra. You can also combine the above two methods to achieve optimal results.
Conclude
Through this article, I hope to give people an overview when implementing a project related to AI in practice. It is not too academic but close to the technical brothers. Looking forward to receiving feedback from everyone.