1. Overview:
Reading reasearch paper (which I will use as paper for short) is very important if you want to understand deeply about a method or an algorithm in Machine Learning or Deep Learning. This is a job that sounds like simple but really not easy at all. Some people who are new to these two fields have no experience in choosing paper to read or how to read paper inefficiently, which wastes time and effort. In this article, I will point out some of the beginner’s mistakes, as well as give some basic techniques to increase the ability to acquire knowledge and save time when reading a paper. To make it easier to understand, we will answer the following questions in turn:
- What is the general structure of a paper?
- How to choose paper to read?
- How to read effectively?
2. General structure of a paper:
Every organization or individual that publishes a paper has its own ways of presenting it, but most papers follow a common format below.
- Title (*) : is the title of the paper, the section usually refers to the name of the method or model and the author of that paper.
- Abstract (*) : is a summary of the content of paper. The main methods, problems and results of paper are outlined in this section.
- Introduction (*) : is a section that presents problems with paper, may be shortcomings that exist in previous models or methods, and generally outline the method, and how to solve it contained in this paper. .
- Related Work : This refers to the research related to the topic that paper is heading to.
- Model / Method / Approach (*) : is the main content of the paper, the paper studies will be described in detail in this section.
- Results : is the section that gives the results of the paper research, often compared to the results of previous models or methods.
- Conclusion (*) : A summary of the main content contained in paper.
- References : The quoted part of the paper.
In which the items marked with (*) are important items related to the main content of the paper that you need to pay close attention to. In addition, a paper may have other sections such as Discussion or Appendix, which you can check out later.
3. Choose what paper to read:
Each topic included in Machine Learning or Deep Learning has a huge number of papers and this number increases rapidly every year so reading all the papers in a topic is considered impossible !?
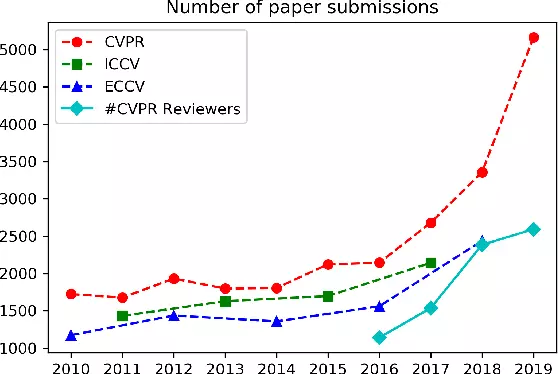
Figure1. Number of papers submitted at some famous conferences in recent years.
Not only that, reading paper in an innocent way can make us dilute our knowledge, away from the topic we are researching and worse, there are papers that do not even bring us knowledge but vice versa. even when reading it also makes us misunderstand nature, deviate in thinking. This is especially true for machine learning or deep learning newbies, who are willing to spend the whole day reading a paper they can find on the internet without even knowing it is really useful for they do not. This makes a lot of effort and time wasted. From here we can draw the first mistake. Inexperienced or do not know how to extract the paper to read
Perhaps many of you will wonder how to choose good-quality papers that are worth reading and ignore those that are not good and should not be read. To answer this question, we first need to identify the types of paper.
Usually papers in a particular topic will be classified into the following 3 groups:
- The groundbreaking papers : these are referred to as “Top papers ” and are often the first papers to refer to widely applied research, or very interesting ideas. These papers are usually published by engineers from reputable organizations or universities (eg. Google, Facebook or Stanford University, etc.) or from groups or universities that have participated. Researcher on this issue for many years. These papers can have very high cited indexes.
- The copycat papers : some teams track and use research from groundbreaking papers and add some improvements to it, announcing a result that surpasses the original research. However, many of these papers lack proper statistical analysis and false conclusions that have actually beat the original research. What their paper provides may not even be more complex than additional enhancements. However, not every copycat paper is bad, some are very good, but this number is very rare.
- The garbage papers : These are papers that are written very carelessly, the content is nowhere else, often these papers are written by inexperienced people. or not invest enough time and effort in research.
Speaking of which, you probably guess that we should choose which paper to read then right. Firstly, try to read groundbreaking papers , you can search google to see if a paper is groundbreaking papers by looking at the author’s information, if the author is an engineer from technology companies. or top universities in the world such as Google, Facebook, Microsoft or Stanford, … or have been the author of another top paper, it is likely that it is a top paper.
Figure 2: Resnet – one of the famous top papers of Deep Learning.
Or check the number of citations, if the paper has a large number of citations, then most likely it is also a top paper (of course the number of citations is only relative, because the top paper is published more) last year there might be a lot of different quotes compared to a top paper published in recent years) or if you have experience reading it is better that you can go in and skim the content of that paper and then evaluate also.
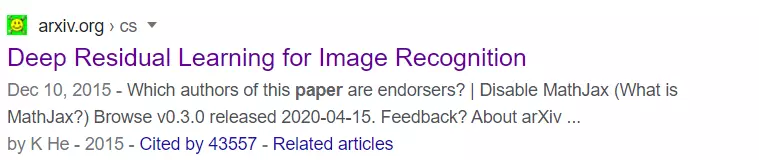
Figure 3: Resnet’s “terrible” number of citations.
In many cases, if you cannot find a top paper in the topic you are researching, it is okay to start from a copycat paper, after reading a turn or trying to check the citations included in the article. paper, there will likely be a top paper cited in the copycat paper you are reading that.
If you are a newbie who has just stepped into a specific topic, needing an overview of the research or methods already in this topic, I suggest reading the paper. The fourth is survey paper . Survey paper is a general paper that summarizes the knowledge and research in a certain field, usually these papers do not go into details of methods but only list and assess the existing research. before. And most likely in the survey paper will cite the top papers included in the topic you are exploring, please pay attention.
See more here :
- https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap
- https://github.com/terryum/awesome-deep-learning-papers
4. Read how to effectively:
Another mistake of people who are new to Machine Learning or Deep Learning when reading a paper is that they read it from beginning to end and didn’t miss anything . For short papers of 8 to 10 pages, I do not object to this reading, but with papers of up to 20 or 30 pages, this is a completely different story. Try to read everything in many cases this is not good, on the contrary it can make you forget important parts of paper and waste time. To overcome this problem, try to learn how to extract the necessary information and eliminate unnecessary things.

Figure 4: The original LSTM paper is up to 32 pages long.
As stated above, items such as Title, Abstract, Introduction, Method / Model and Conclusion are the parts directly related to the main content of the paper. These are important parts that you are not allowed to ignore and must read carefully. The section like Related Works or Result you can ignore, but if you are new to the topic of paper, it is best to check the methods or research mentioned in the Related Works section, so will help you have a better overview of knowledge related to this paper and if you already know everything in this section then you can ignore it, or when you want to re-implement the algorithm of this paper, the Result section This is what you use to compare results, and sometimes the author will leave the model’s Hyper Parameters in this section.
However, in each case, try to decide which parts are kept and which ones are discarded. And try to ignore the applied sections and not much related to the main content of the paper. For example, if you are reading a paragraph: “Deep convolutional neural networks have led to a series of breakthroughs for image classification ..” then this section will mainly talk about the effect of Deep Neural Network with Image Classification. always, so we can save a lot of time, as well as omitting the non-meaningful information.
And finally, I would like to share with you a method of reading paper that I still often use named 3 reads . True to its name, we will read paper in 3 times, each time we will read in a different way and hope after the 3rd reading, we can grasp most of the knowledge contained in paper .
Time 1: Reading Surfing
The first reading will give you an overview of the knowledge as well as the main ideas contained in paper. In this first reading, follow these steps:
- Read carefully the Title , Abstract and Introduction section of the paper.
- Look through all the pictures in the paper if available.
- Read all the headings in Model / Method and skip the details.
- Read carefully the Conclusion section.
- Browse through the References section to see if any papers you’ve read about and been cited already.
- Skip sections containing math formulas.
After this first reading, try to answer the following questions:
- What kind of paper is this? ( groundbreaking or copycat )
- What is the problem presented by the author in the paper?
- The method, the model that the author used to solve that problem?
- What are the effectiveness of those methods and models?
Based on answering the above questions, you will get an overview of the main content contained in the paper, based on which you can decide whether to read this paper or skip it and move on to one. other paper. The first reading takes place very quickly, you can complete this section in just about 10 to 15 minutes.
2nd: Read + Take Notes
At the second reading, we will consolidate the general knowledge gained at the first reading and begin to go into details of the solutions and models outlined in the paper. In order to avoid reading before and after, you should have a notebook to record the main content of each section above.
In the 2nd, please follow these steps:
- Read + take note of the main ideas included in the Title , Abstract and Introduction sections.
- Read + write down the main ideas in Model / Method . Copy the illustration of the model or method if needed.
- Copy the math formulas included in the paper if available.
- Check carefully the References section, highlighting papers related to the main knowledge.
- Read + take notes of the main ideas of the Conclusion section.
After this second reading, we will stop at a relative “know” of the methods and models outlined in paper. If you think you have enough knowledge and want to understand those methods deeply, proceed to the third reading, otherwise stop it and move on to read another paper that you have marked as relevant. The main knowledge in this paper that you do not understand. The 2nd reading usually takes about 1 to 2 hours.
3rd: Reading Comprehension
In this third reading, we will reread the paper in conjunction with the notes we made at the 2nd reading. Read carefully the mathematical formulas or prove them again, understand. clear the illustrations included in the paper. The goal is to understand and answer some of the questions in more detail, such as the following.
- How are the mathematical formulas understood?
- How is the Ground Truth of the model built?
- Data Flow when passing data through the model?
- Which error function does the model use?
- What is the architecture of the model?
- Metric used to evaluate?
- …..
After this 3rd time, you will be able to really grasp the knowledge and methods contained in paper. This is also the most time-consuming part, although it can take several days, or longer than a week, depending on the amount and knowledge of each person.
In my opinion, do 2 readings in case you just want to know the model and method in paper, and make 3 readings in case you want to deepen or re-apply this paper. And remember, you don’t need to remember all the specifics in paper, because you can review it whenever you need it, it’s important that you know what you need to see in the paper.
Above are the experiences I have learned during the process of reading a paper, as well as referencing it online. Thank you for watching.