As we learned in Part 1 of the Software Design series , we already know two reasons why a software system becomes complex, one of which is constraints. In this article, we will continue to work with John Ousterhout and Philosophy of Software Design to find ways to minimize or maximize constraints in the system, starting with the concept of the depth of the system. modules.
Modules must have depth
One of the most important techniques in managing the complexity of a software system is designing the system so that the programmer faces only a fraction of the total complexity at a time. This approach is called modular design , in this section we will learn its basic principles.
Modular design
In modular design, a software system is decomposed into a group of relatively independent modules. Modules can take many forms, such as classes, subsystems, or services. In an ideal world, each module would be completely independent of the other modules: programmer can work with any module without knowing anything about the modules. other.
However, that ideal world is not possible, because the modules have to work together by calling each other’s functions and methods. As a consequence, these modules have to know the information of another module. As such, constraints will form between modules: if one module changes, then the other modules must change for compatibility. For example, the parameters of a method create a constraint between the method and whatever code calls it; if required parameters are changed, the other code must also be modified to match the new signature. In short, the purpose of the modular design is to minimize the constraints between the modules.
To manage constraints, a module is defined with two parts: interface and implementation .
- The interface includes everything a programmer needs to know, when working with a module, to be able to use that module. Usually, an interface describes the action of the module, not how the module works. An interface contains two types of information: formal and informal.
- The formal part is clearly indicated in the code. For example, the signature of a method includes the name, the data type of the parameters, the data type of the return value, and information about the exceptions.
- The informal section describes high-level behaviors, such as a file deletion function based on the filename parameter. If a class requires constraints when used (as one method must be called before the other), then this is also an informal part of the class’s interface. Unofficial sections can only be described using comments.
- The implementation includes the code that executes the things described by the interface.
A programmer working in a given module must understand the interface and the settings of that module, plus the interfaces of other modules that the current module calls. Importantly, the programmer does not need to understand the settings of the other modules.
Consider an example of a balanced binary tree data structure implementation module. There should be a lot of code in this module that deals with complex logic to ensure the tree is balanced, but the user will not see the complexity. The user will only see a relatively simple interface to add, delete, and retrieve the value of the nodes in the tree. To perform the action of adding node, the user only needs to provide the key (key) and value (value) of the node, and the tree browsing mechanism, node separation are hidden.
For the purposes of books and articles, a module is a unit of code that includes both the interface and the implementation. Thus, each class in object oriented programming (OOP) is a module. Each method in a class or functions in non-object oriented languages is also considered as modules. Subsystems or services are also modules, whose interfaces can exist in various forms, such as kernel calls or HTTP requests.
The best module is the one that has a much simpler interface than its installation. Such modules have two advantages:
- First, the simple interface reduces the complexity of one module imposed on the rest of the system.
- Second, if one module is modified without changing its interface, the other modules will not be affected by this change.
Abstraction
Abstraction is a simplified view of an object in which unimportant details are omitted.
Abstract concepts are intimately tied to modular design. It is very useful because it makes it easy to visualize and manage complex things.
In modular programming, each module provides an abstraction in terms of its interface. The interface shows a simplified view of the module’s functions, while the implementation details are not important from an abstract point of view, so it is not included in the interface. In the definition, the phrase “is not important” deserves attention. The more unimportant details that are removed from the abstraction, the better. However, a detail can only be omitted if it is not important. The key to interface design is to really understand what is needed, then look for designs that minimize the amount of important information.
The file system is an example. Its abstraction does not include details that are unimportant to the user such as the mechanism for selecting a storage device block to use for a file’s data. However, there are some details in the file system settings that are important to the user: most file systems use caches and delay writing of new data to storage devices. storage, for the purpose of increasing efficiency; Some applications, such as databases, need to know exactly when data will be actually written to ensure data integrity. As such, the rules for data writing must be shown in the file system interface.
Deep modules
The best module is the one that offers many powerful features with a simple interface. The adjective “deep” is used to describe such modules, as opposed to “deep” which is “shallow.” The figure below shows the deep and shallow module visually. 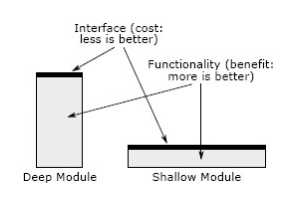
Module depth is a way of thinking about costs and returns. The profitability of a module is its function, and the cost (in terms of complexity) is the interface. The smaller and simpler the interface, the less the complexity will follow. The best module is the one most profitable with the least cost. Layout is good and necessary, but a larger interface, or more interfaces, doesn’t mean better.
The file I / O (file I / O) mechanism of the Unix operating system and its descendants, like Linux, is a great example of the deep interface. There are five basic system commands for import and export, with simple symbols:
1 2 3 4 5 6 | int open(const char* path, int flags, mode_t permissions); ssize_t read(int fd, void* buffer, size_t count); ssize_t write(int fd, const void* buffer, size_t count); off_t lseek(int fd, off_t offset, int referencePosition); int close(int fd); |
Modern implementations of the Unix I / O interface require hundreds of thousands of lines of code, to handle all the complex write-offs we encounter with file I / O. These settings are all hidden from the user. Each year these settings are changed significantly, but for users, the five system commands mentioned above remain unchanged.
Shallow modules
A module, on the other hand, is considered shallow if its interface is relatively complex compared to the feature it provides. If a module is shallow, you will have to spend a lot of time getting used to the interface, compared to the amount of time that the module saves you. Here is a clear example:
1 2 3 4 | <span class="token keyword">private</span> <span class="token keyword">void</span> <span class="token function">addNullValueForAttribute</span> <span class="token punctuation">(</span> <span class="token class-name">String</span> attribute <span class="token punctuation">)</span> <span class="token punctuation">{</span> data <span class="token punctuation">.</span> <span class="token function">put</span> <span class="token punctuation">(</span> attribute <span class="token punctuation">,</span> <span class="token keyword">null</span> <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> |
From a complexity management perspective, this approach doesn’t make the system any better, it just gets worse. The aforementioned method does not bring any abstraction, because all of its features are represented through the interface, so it is not easier to visualize by the interface than to visualize with the entire implementation of the method. If the method is carefully documented, the document will be longer than the entire code. Furthermore, the user has to type more keys to call the method instead of directly working with the data variable. In short, the aforementioned method increases complexity without bringing any profit.
Classitis syndrome
Unfortunately, today, the value of deep classes is not widely appreciated. IT students are often taught that the class should be small, not deep, and need to divide the class into smaller classes. Or a similar advice is often given: “Any method longer than N lines of code should be broken down into several different methods” (N can be as little as 10). This approach results in a large number of shallow classes and methods, which causes the overall complexity of the system to increase.
The extreme “class so small” approach is called classitis syndrome by John Ousterhout. In systems with this syndrome, programmers are encouraged to minimize the amount of features in each new class: if you want more functionality, create a class. Classitis can make each class simple, but it increases the complexity of the entire system. Small classes do not contribute many features, so there are many classes, each with its own interface. These interfaces aggregate and create considerable complexity at the system level. Many small classes also make code cumbersome, because the boilerplate is required for each class.
Example: Java I / O
The Java language itself doesn’t require many small classes, but classitis syndrome is slowly creeping into the java community. Let’s take a look and discuss a piece of code used to open files and read serialized objects:
1 2 3 4 | <span class="token class-name">FileInputStream</span> fileStream <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">FileInputStream</span> <span class="token punctuation">(</span> fileName <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token class-name">BufferedInputStream</span> bufferedStream <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">BufferedInputStream</span> <span class="token punctuation">(</span> fileStream <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token class-name">ObjectInputStream</span> objectStream <span class="token operator">=</span> <span class="token keyword">new</span> <span class="token class-name">ObjectInputStream</span> <span class="token punctuation">(</span> bufferedStream <span class="token punctuation">)</span> <span class="token punctuation">;</span> |
The FileInputStream object only provides rudimentary input and output: it cannot perform input and output with a buffer, nor can it read and write the transformed object. The BufferedInputStream object adds a buffer to the FileInputStream, and the ObjectInputStream object allows reading and writing of the transformed object. The first two objects are never used once the file has been opened, after which all operations use only objectStream.
It’s annoying (and probably error-prone) when a buffer has to be requested directly by creating a separate BufferedInputStream object. If a programmer forgets to create this object, there will be no buffers and the performance of I / O is reduced. Perhaps Java programmers will argue that not all want to use a buffer, so it should not be included in the default mechanism. They might also argue that it would be better to keep the buffering feature separate, and give people the choice of whether to use it or not. While offering choice is good, the interface should be designed in such a way that common cases are as simple as possible . Most people prefer to use buffers when importing and exporting files, so it should be provided by default. And in some cases a buffer is not needed, the library can provide a mechanism to disable it. The de-buffering mechanism should be isolated (for example, by creating a different constructor for the FileInputStream, or adding a method to disable or modify the buffer), thanks to which most developers it does not need to be known.
Conclude
In this article, we have understood the concept of module depth. In the next article, we will learn techniques for creating deep modules.