The Command and Query Responsibility Segregation (CQRS) pattern separates read and write data. Deploying CQRS in your application can optimize performance, scalability, and security. The flexibility of CQRS allows the system to grow better over time and prevent update commands that cause conflicts at the domain level.
Problem
In traditional architecture, the same data model is used for both reading and writing in a database. That is simple and works well for common additions, fixes, and deletions (CRUDs). However, in more complex applications, this approach can make the application more and more burdensome. For example, data readers can perform many different queries, returning data transfer objects (DTOs) in many different forms. Object mapping can become complex. The data logger, the model, can implement complex validation and business logic. As a result, you can get a complex model and do too many different things.
The read and write workloads are often unrelated, with lots of differences in performance and expansion requirements.
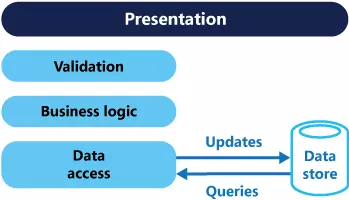
- There are often data mismatches between read and write, such as the addition of columns and attributes that must be updated even though they are not required in processing.
- Data disputes can occur when operations are performed in parallel on the same data set.
- The traditional approach can have a negative effect on performance due to load on the data store and data access tier, and queries to receive data become complicated.
- Managing security and permissions (permissions) can be difficult and complex, because each entity has both read and write operations, which can expose data in the wrong context.
Solution
CQRS splits reading and writing into different models, using the command to update and query to read data.
- Command should be task based instead of data focused (“Hotel reservation”, don’t set “ReservationStatus to Reserved”)
- Command can be placed in a queue for asynchronous processing instead of being processed synchronously (synchronous).
- Query never modifies database data. A query returns a DTO without encapsulating any domain knowledge.
Models can be isolated, isolated from each other, as shown in the diagram below, although this is not an absolute requirement.
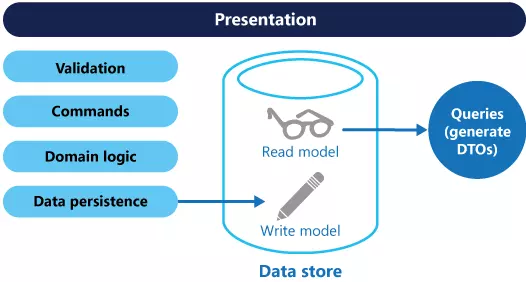
Separate models for reading and writing make the design and deployment process simpler. However, one disadvantage of CQRS is that the code cannot be automatically generated from the database’s schema using scaffolding mechanism like ORM tool.
For better isolation, you can split the read and write data. Reading databases can use their own data schema to optimize queries. For example, it can store the Materialized View of the data, in addition to avoiding joins and complicated mapping. It can even use a different type of data storage. For example, the record database can be a relational database, while the reading database is a document database. In short, the database of read and write is separate and it is possible to use two different types.
If read and write database operations are performed, they must be kept in sync with each other. Usually this is accomplished by having the model log out an event anytime there is an update in the database. Updating and exporting events must occur in a transaction.
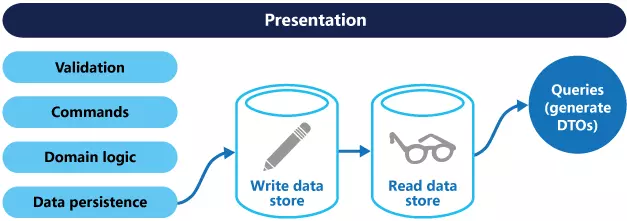
The read database may be a read-only copy of the write database or they may have a completely different structure. Using multiple read-only copies can increase performance, especially in distributed scenarios where read-only copies are located near application instances.
Splitting the read and write database also allows each one to have a proper extension to accommodate the load capacity. For example, the read database usually loads much higher than the write database.
Some implementations of CQRS use the Event Sourcing pattern. With this pattern, application state is stored as events. Each event represents a set of data changes. The current state is built by replaying those events. In a CQRS context, the benefit of Event Sourcing is that similar events can be used to notify other components – specifically, to the reader model. The reader model uses events to create a snapshot of the current state, which is more efficient for queries. However, Event Sourcing brings complexity to the design of the application.
Benefits of CQRS include:
- Independent expansion . The CQRS allows for independent read and write workloads and may result in less dispute.
- Optimize schema of data . The reader can use the schema that is optimized for the query, while the reader can use the schema optimized for updating.
- Confidentiality . It is easier to ensure that only authorized domain entities are writing data.
- Split the concerns . Dividing the read and write sides can make the model easier to maintain and flexible.
- The queries are simpler . By storing a materialized view in the database for reading, the application can avoid complicated joins when querying.
Points to consider using
Some of the challenges of implementing this pattern include:
- Complex . The basic idea of CQRS is simple. But it can lead to a complex application design, especially when they use the same Event Sourcing pattern.
- Messaging . Although CQRS does not require messaging, it is common to use messaging to handle commands and issue event updates. In this case, the application must handle a failed or duplicate message.
- The ultimate unity . If you split the read and write database, the read data may be stale. The reader’s model store must be updated to reflect the changes of the reader’s model store and it can be difficult to detect when a user makes a request based on old read data.
When to use this pattern
Consider CQRS for the scenarios below:
- Collaborative domains where multiple users have parallel access to the same data. CQRS allows you to define the command with enough detail to minimize the conflict at the domain level and the conflicts generated by the command.
- The task-based user interface where the user is guided through complex processes such as a set of steps or with complex domain models. The recording model has a full command-processing stack with business logic, input validation and business validation. The writable model can behave as a set of objects linked as a model unit for changing data (an aggregate, in DDD terminology) and ensure that these objects are always consistent. The read model has no business logic or validation, only returns a DTO in a view model. Model read is consistent with the model.
- Scenario where the performance of data reading must be fine-tuned separately from the performance of data writing, especially when the number of readings is much larger than the number of writes. In this scenario, you can extend the reading model but run the recording model in only a few instances. A small number of instances of the recording model also support to minimize merge conflicts.
- Scenario where one team of programmers can focus on a complex domain model of the recording model part, another team can focus on the reading model and user interface.
- The scenario where the system is expected to evolve over time and may contain multiple versions of the model or where business rules change over time.
- Integration with other systems, especially in coordination with event sourcing, in which temporary subsystem failure does not affect the operation of other systems.
This pattern is not recommended when:
- The domain of the business rule is simple.
- A simple user interface adds, edits, deletes, and sufficient data access.
Consider applying CQRS to a limited number of parts of your system where it is most valuable.
Event Sourcing and CQRS
The CQRS pattern is often used in conjunction with the Event Sourcing pattern. The CQRS-based system uses split reading and writing data models, each adjusted for related tasks and usually located in separate repositories. When used with Event Sourcing , the database of events is the record model and the official source of information. The reading model of the CQRS-based system provides materialized view of data, typically as non-standardized views. These views are adjusted to the interface and display application requirements, maximizing the performance of both queries and queries.
Using the event stream is a logging database, rather than actual data at a time, avoiding updating conflicts in a single aggrefate, maximizing performance and scalability. Events can be used asynchronously to produce a marterialized view of the data that is used to generate the reading database.
Because the event store is the official source of information, it can delete materialized views and re-run all past events to create the current state of the data as the system grows or when the model reads it. change.
When to use CQRS in combination with Event Sourcing , consider the following cases:
- For any system where the read and write databases are split, this pattern-based system is just a final agreement. That will be some delay between the event being produced and the database being updated.
- The pattern adds complexity because code must be generated to initialize and handle events and assemble or update appropriate views, objects requested by queries or a read model. The complexity of the CQRS pattern when used with Event Sourcing can make successful implementation more difficult and require a different approach to system design. However, event sourcing may make it easier to model the domain and make it easier to rebuild views or create new ones because the history of data changes is preserved.
- Generating materialized views for use in the reading model or data history by caching and handling events for entities or collections of entities may require significant processing time and resource usage. This is especially true if it requires aggregation or analysis of values over long periods of time, because all associated events may need to be checked. Solve this problem by deploying snapshots of the data at the scheduled interval, like counting the total number of actions that have occurred or the current picking status of an entity.
For example
The code below is an example of implementing the CQRS pattern that uses different definitions for reading and writing models. Model interfaces do not dictate any feature of the platform database and they can be developed and customized independently because these interfaces are separated.
The following code shows the definition of the read model:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | <span class="token comment">// Query interface</span> <span class="token keyword">namespace</span> ReadModel <span class="token punctuation">{</span> <span class="token keyword">public</span> <span class="token keyword">interface</span> <span class="token class-name">ProductsDao</span> <span class="token punctuation">{</span> <span class="token class-name">ProductDisplay</span> <span class="token function">FindById</span> <span class="token punctuation">(</span> <span class="token keyword">int</span> productId <span class="token punctuation">)</span> <span class="token punctuation">;</span> ICollection <span class="token operator"><</span> ProductDisplay <span class="token operator">></span> <span class="token function">FindByName</span> <span class="token punctuation">(</span> <span class="token keyword">string</span> name <span class="token punctuation">)</span> <span class="token punctuation">;</span> ICollection <span class="token operator"><</span> ProductInventory <span class="token operator">></span> <span class="token function">FindOutOfStockProducts</span> <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">;</span> ICollection <span class="token operator"><</span> ProductDisplay <span class="token operator">></span> <span class="token function">FindRelatedProducts</span> <span class="token punctuation">(</span> <span class="token keyword">int</span> productId <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">class</span> <span class="token class-name">ProductDisplay</span> <span class="token punctuation">{</span> <span class="token keyword">public</span> <span class="token keyword">int</span> Id <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">string</span> Name <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">string</span> Description <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">decimal</span> UnitPrice <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">bool</span> IsOutOfStock <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">double</span> UserRating <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">class</span> <span class="token class-name">ProductInventory</span> <span class="token punctuation">{</span> <span class="token keyword">public</span> <span class="token keyword">int</span> Id <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">string</span> Name <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">int</span> CurrentStock <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> |
The system allows users to rate the product. The application code does this by using the RateProduct command shown in the code below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <span class="token keyword">public</span> <span class="token keyword">interface</span> <span class="token class-name">ICommand</span> <span class="token punctuation">{</span> <span class="token class-name">Guid</span> Id <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">class</span> <span class="token class-name">RateProduct</span> <span class="token punctuation">:</span> <span class="token class-name">ICommand</span> <span class="token punctuation">{</span> <span class="token keyword">public</span> <span class="token function">RateProduct</span> <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">this</span> <span class="token punctuation">.</span> Id <span class="token operator">=</span> Guid <span class="token punctuation">.</span> <span class="token function">NewGuid</span> <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token class-name">Guid</span> Id <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">int</span> ProductId <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">int</span> Rating <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">public</span> <span class="token keyword">int</span> UserId <span class="token punctuation">{</span> <span class="token keyword">get</span> <span class="token punctuation">;</span> <span class="token keyword">set</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> |
The system uses the ProductsCommandHandler class to handle commands sent by the application. Clients normally send commands to domains via a messaging system like queue. The command handler accepts commands and invokes methods of the domain interface. The granularity of each command is designed to reduce the chance of conflicting requests. The code below shows an outline of the ProductsCommandHandler class
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | <span class="token keyword">public</span> <span class="token keyword">class</span> <span class="token class-name">ProductsCommandHandler</span> <span class="token punctuation">:</span> <span class="token class-name">ICommandHandler</span> <span class="token operator"><</span> AddNewProduct <span class="token operator">></span> <span class="token punctuation">,</span> ICommandHandler <span class="token operator"><</span> RateProduct <span class="token operator">></span> <span class="token punctuation">,</span> ICommandHandler <span class="token operator"><</span> AddToInventory <span class="token operator">></span> <span class="token punctuation">,</span> ICommandHandler <span class="token operator"><</span> ConfirmItemShipped <span class="token operator">></span> <span class="token punctuation">,</span> ICommandHandler <span class="token operator"><</span> UpdateStockFromInventoryRecount <span class="token operator">></span> <span class="token punctuation">{</span> <span class="token keyword">private</span> <span class="token keyword">readonly</span> IRepository <span class="token operator"><</span> Product <span class="token operator">></span> repository <span class="token punctuation">;</span> <span class="token keyword">public</span> ProductsCommandHandler <span class="token punctuation">(</span> IRepository <span class="token operator"><</span> Product <span class="token operator">></span> repository <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">this</span> <span class="token punctuation">.</span> repository <span class="token operator">=</span> repository <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token keyword">void</span> Handle <span class="token punctuation">(</span> <span class="token class-name">AddNewProduct</span> command <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">}</span> <span class="token keyword">void</span> Handle <span class="token punctuation">(</span> <span class="token class-name">RateProduct</span> command <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token keyword">var</span> product <span class="token operator">=</span> repository <span class="token punctuation">.</span> <span class="token function">Find</span> <span class="token punctuation">(</span> command <span class="token punctuation">.</span> ProductId <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token keyword">if</span> <span class="token punctuation">(</span> product <span class="token operator">!=</span> <span class="token keyword">null</span> <span class="token punctuation">)</span> <span class="token punctuation">{</span> product <span class="token punctuation">.</span> <span class="token function">RateProduct</span> <span class="token punctuation">(</span> command <span class="token punctuation">.</span> UserId <span class="token punctuation">,</span> command <span class="token punctuation">.</span> Rating <span class="token punctuation">)</span> <span class="token punctuation">;</span> repository <span class="token punctuation">.</span> <span class="token function">Save</span> <span class="token punctuation">(</span> product <span class="token punctuation">)</span> <span class="token punctuation">;</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> <span class="token keyword">void</span> Handle <span class="token punctuation">(</span> <span class="token class-name">AddToInventory</span> command <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">}</span> <span class="token keyword">void</span> Handle <span class="token punctuation">(</span> <span class="token class-name">ConfirmItemsShipped</span> command <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">}</span> <span class="token keyword">void</span> Handle <span class="token punctuation">(</span> <span class="token class-name">UpdateStockFromInventoryRecount</span> command <span class="token punctuation">)</span> <span class="token punctuation">{</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">.</span> <span class="token punctuation">}</span> <span class="token punctuation">}</span> |
Conclusion
Command and Query Responsibility Segregation is an interesting and novel pattern for many people. Its strengths are performance, scalability and security. It is suitable for large and complex systems rather than simple systems. Hopefully the article will give you a basic look at this pattern and can be applied in your system. Thank you for watching.
Article translated from source: