
Recommender System (Recommender System) is a sub-branch of the information filtering system (Infomation filtering system), to try to predict the rating (rating) of the user (user) will give for 1 product (item ). They are mainly used in e-commerce applications.
For example: Introducing products on Amazon, songs on Spotify, movies on Netflix or articles on Medium, …
In essence, the problem of the suggestion system is to define the mapping (u, i) -> R, where u represents 1 user, i represents 1 product and R is the rating of u on i . Then, u user ratings on all respective i products will be sorted, and take the N products with the highest rating to give suggestions to user u.
The concept of ‘reviews’ here is quite abstract, can be measured by the user’s actions such as buying the product, clicking on the product, or clicking “do not show again”, …
1. Ranking vs Recommender
There are a lot of people who still mistakenly think the Ranking and the Recommender system (Recommender), but it’s a different problem:
- The ranking system is based on all the products that the user offers to give the search query, the user knows which product they are looking for. The suggestion system does not have any clear input from the user, in order to discover products that they have never seen before.
- The ranking system often places related products near the top of the displayed list while the suggestion system sometimes tries not to be overly specialized.
- The suggestion system puts the greatest emphasis on personalization
2. Suggested systems
Suggestion systems are generally classified into the following categories:
- Content-base filtering
- Collaborative filtering (Collaborative filtering)
- Hybrid Method
Depending on whether the system learned from the data or not, the following categories are divided:
- Memory-based
- Model-based
2.1. Content-base filtering
Content-based filtering is based on the total number of items (for users) and the profile of the user rating. It is best suited for known data about the item and how the user has previously interacted with the suggestion system, but lacks user information.
In essence, the prediction of user u’s rating on item i is based on the user’s ratings for other items in the past.
Suppose that Wi is the profile vector for item i and Wu is the profile vector for user u. A profile vector is understood as a summary of the user ratings for all previous entries.
2.1.1. Memory base example
Using a rating system as an example, one way to model a user profile vector is through a rating weighted average, ie:
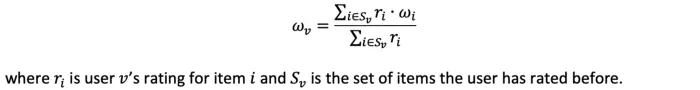
Then, evaluation (u, i) becomes:
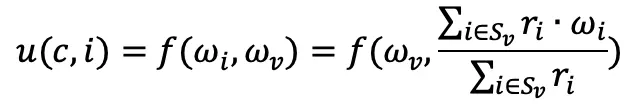
Utility functions are often represented in information retrieval documents by the cosine similarity measure:
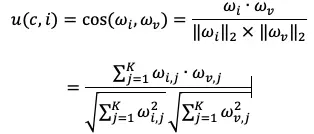
Here, K is the dimension of the item and the user profile vector.
2.1.2. Model base example
The Naive Bayes classification has been widely used, typically for the suggestion system content-based filtering approach.
We use the video suggestion system as an example, and the user rating is measured by clicking on the suggested video or not. More precisely, the problem suggested here is the estimated probability of clicking on a video: 
According to Bayes’ theorem:
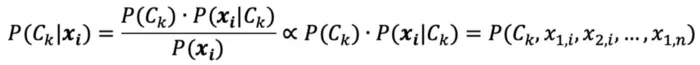
According to the chain rule technique:
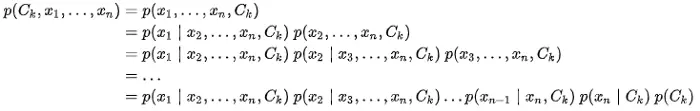
With the support of the Naive independent assumption, we get:
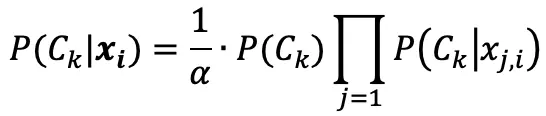
Here, alpha is a normalized parameter to ensure the resulting probability is in the segment [0, 1]. However, this is not necessary for some suggestion systems, where we are only concerned with the relative rankings of the items.
2.1.3. Limit
- Sparse data, based on memory or patterns, both leverage the user’s historical interaction with the suggestion system. Therefore, for those who are just starting to use the (Cold Start) system, the suggestion system may not work correctly.
- In the case of a new user (Cold Start) it won’t work.
Collaborative filtering overcomes these limitations by leveraging the information of multiple users.
2.2. Collaborative filtering (Collaborative filtering)
Collaborative filtering is suitable for known data types about the user but lacks data for items or makes it difficult to perform feature extraction for items of interest.
Unlike content-based filtering, collaborative filtering tries to predict the rating of user u for an item i based on other user ratings for that item.
2.2.1. Memory base example
Using the rating system example again, memory-based methods are basically the method of predicting the rating of user u for item i based on collecting ratings for that product from users. other:
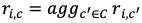
In which, C is the user set that does not include the user c is interested in
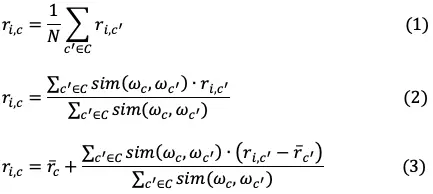
(1) is simply an average rating for the product from all other users. (2) attempt to weigh another user’s rating by user similarity c. One way to measure the function similarity between the feature vectors of two users. (3) is to solve the problem that users can have different rating scales.
2.2.2. Model base example
Collaborative filtering based on historical data (from other users) to explore a model. For the ranking example, a model is a linear regression against the user profile as the features and ratings for each individual item.
2.2.3. Limit
- The data is sparse, for items that are less popular or less appreciated, collaborative filtering is difficult to produce accurate results.
- For new users, this method is also not applicable.
2.3. Hybrid Method
Because both methods above have their own limitations, at the same time this method can solve the limitations of the other, so they can be hybridized.
Combinations:
- Implement 2 methods separately and combine their predictions. This is essentially a synthetic model.
- Incorporate content-based features and collaborative filtering. The way to do this is to take advantage of the user’s profile to measure the similarity between 2 users, and use this similarity as a weight in the step of synthesizing the two methods.
- A multi-user model and multiple items. This is to build a model that has both the item feature and the user feature as input, such as a linear regression model, a tree model, a neural network model, etc.
3. Expansion
Some suggestion systems are very time sensitive (New feed of facebook) or depending on season (suggest tourist destination). For these suggestive systems, we need to build a time series model (Arima, RNN). There are also suggestion systems where the recommendations are more related to the user’s most recently viewed item (Youtube), in which case the Markov-based model might be more suitable.
Source: TowardsDataScience