The R programming language comes to Google Cloud Platform
- Linh Le
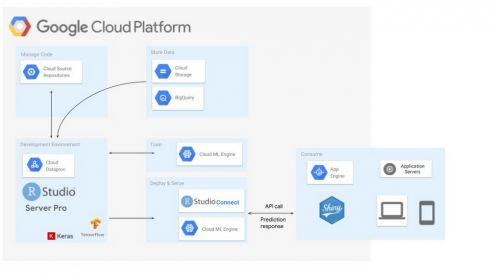
In an effort to bring greater support for the R programming language on Google Cloud Platform, Google has announced the beta release of Spark jobs on Cloud Dataproc. The R language is most commonly used for data analysis tools and statistical apps. According to Google, the rise of cloud computing has opened up new opportunities for R.
“Using GCP for R lets you avoid the infrastructure barriers that used to impose limits on understanding your data, such as choosing which datasets to sample because of compute or data size limits. With GCP, you can build large-scale models to analyze datasets of sizes that previously would have required huge upfront investments in high-performance computing infrastructures,” Christopher Crosbie, product manager of Dataproc and Hadoop, and Mikhail Chrestkha, machine learning specialist, wrote in a blog post.
Cloud Dataproc is a fully managed cloud service for Apache Spark and Apache Hadoop clusters on GCP, while SparkR is a lightweight package that enables Apache Spark from R on the frontend, the company explained.
“This integration lets R developers use dplyr-like operations on datasets of nearly any size stored in Cloud Storage. SparkR also supports distributed machine learning using MLlib. You can use this integration to process against large Cloud Storage datasets or perform computationally intensive work,” Crosbie and Chrestkha wrote.
More ways on how developers can utilize R on GCP are available here.
In addition, Google announced new improvements to Cloud Spanner and Python 3.7 for App Engine.
App Engine now introduces the second-generation Python runtime on GCP. According to the company, developers can now use dependencies from the Python Package Index or private repositories. Cloud Scheduler and Cloud Tasks have also been decoupled from App Engine so developers can use these features across all GCP services.
Updates to Cloud Spanner include query introspection improvements, new region availability and new multi-region configurations. The new introspection capability is designed to provide more visibility into queries. New region availability includes South Carolina, Singapore, Netherlands, Montreal, Mumbai, Northern Virginia, and Los Angeles. The database’s first new configuration is meant for multi-region coverage within the US and designed to reduce latency while the second configuration is for coverage within the EU. More information is available here.
Source : https://sdtimes.com