Tips and tricks
OR is in JOIN, WHERE on multiple columns
SQL SERVER can effectively filter data by using the index through the WHERE clause or any filter combination separated by the AND operator. In a unique way, these operations take data and cut it into smaller pieces, until only our dataset is left.
OR is another story. Because it is implied, SQL SERVER cannot handle them in one execution. Instead, each OR component must be handled independently. When this execution is completed, the results will be concatenated and returned to us.
The worst scenario that occurs when we use OR is that there are multiple tables or columns involved in the clause. We not only need to evaluate each element of the OR clause, but also need to track through other filters and tables in the query. Even if there are only a few tables or columns, the performance of a query can be unbelievably bad.
Here is a simple example of how OR can make a query much slower than you might imagine:
1 2 3 4 5 6 7 8 | SELECT DISTINCT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.ProductID = DETAIL.ProductID OR PRODUCT.rowguid = DETAIL.rowguid; |
The query is simple: concatenate 2 tables and check ProductID and rowguid. Even if none of these columns are indexed, our hope is to scan the Product and SalesOrderDetail tables. Too costly, but there is at least something we can understand. This will be the result of this query:
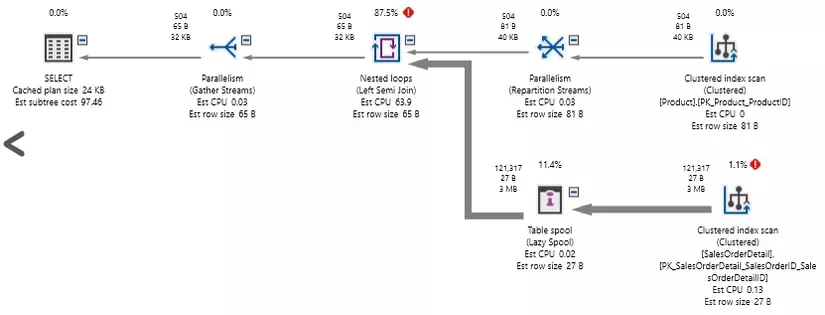

SQL SERVER has scanned both tables, but the OR processing takes an unreasonable amount of calculations. 1.2 million read has been made! Assuming the Product table only contains 504 records and SalesOrderDetail contains 121317 records, we have read more than the data of these two tables. Also, the query takes about 2 seconds to execute on computers with relatively fast SSDs.
The highlight of this scary demo is that SQL SERVER can easily handle an OR condition on multiple columns. The best way to deal with OR is to either remove it (if possible) or break it down into smaller queries. Dividing a short query into a longer query is not very optimal, but it is usually the best option:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SELECT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.ProductID = DETAIL.ProductID UNION SELECT PRODUCT.ProductID, PRODUCT.Name FROM Production.Product PRODUCT INNER JOIN Sales.SalesOrderDetail DETAIL ON PRODUCT.rowguid = DETAIL.rowguid |
In this rewrite, we took each component of the OR and turned it into a separate SELECT statement. UNION concatenates results and eliminates duplicates. Here is the resulting performance:
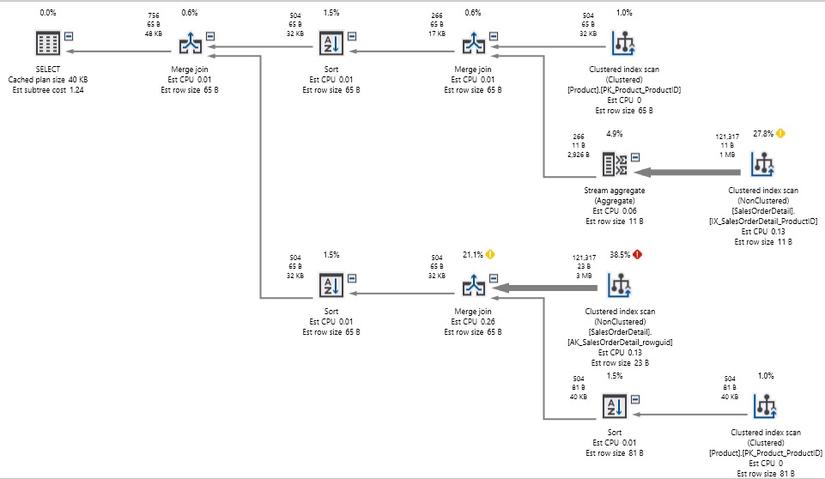

The execution plan becomes significantly more complex, because we are querying each table twice, instead of once, but the result has been cut from 1.2 million to 750 and the query is done well in 1 second, instead of 2 seconds.
Note that there are still a large number of index scans in progress, but even though we have to scan the tables 4 times to meet our query, the performance is still much better than before.
Be cautious when writing queries with OR. Check and verify that the performance is good and you will not accidentally introduce a bomb as seen in the above example.
Search for wildcard strings
Searching for strings can become a challenge. For frequently searched string columns, we must ensure that:
- Indexing for search columns
- These indexes can be used
- If not, we can use the full-text index
- If not, can we use hashes, n-grams, or other solutions?
As long as you don’t use additional features or design considerations, SQL SERVER performs fuzzy search as well. That is, if you want to detect the presence of a string anywhere in a column, retrieving the data won’t work:
1 2 3 4 5 6 7 8 | SELECT Person.BusinessEntityID, Person.FirstName, Person.LastName, Person.MiddleName FROM Person.Person WHERE Person.LastName LIKE '%For%'; |
In the above string search, we will check LastName for the presence of the word “For” anywhere in the string. When % is placed at the beginning of the string, we cannot use any other ascending index. Similarly, when one % is placed at the end of the string, we cannot use the descending index. Here is the performance of the above query:
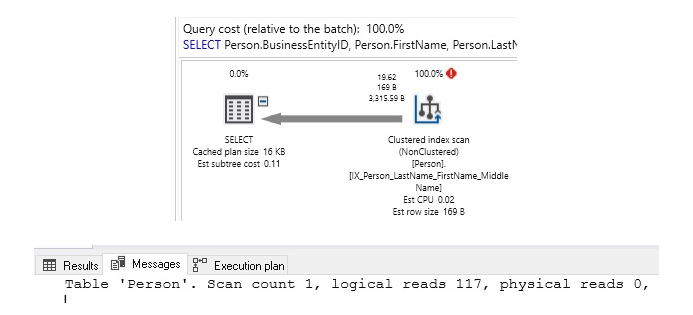
As expected, the above query result will scan on the Person table. The only way to know if a string exists in a text is to go through each character in each text, looking for the occurrence of the string. On a small table, this is acceptable, but for any large data set, this will be very slow and we have to wait for a long result.
There are many different ways to remedy this situation, including:
- Re-evaluate the application. Do we really have to perform wildcard searches this way? Do users really want to search all parts of this column for that series? If not, then this problem will definitely disappear, because we do not need to perform a search
- Can we apply any other filters to the query to reduce the size of the data before we perform a string search? If we can filter the date, time, status, etc., maybe we can reduce the data we need to perform a search down to a level small enough for performance to be acceptable
- We can use leading string search, instead of wildcard search. Can
%For%be replaced with%For? - Indexing all available text?
- Can we perform a hash or n-gram query for that case?
The first 3 solutions are considerations for design / architecture because they are the first one that helps optimize your application. They ask: can we make assumptions, changes or understandings about this query to make it well? All are at the level of application knowledge or the ability to change the return data of a query. These are not always possible solutions, but it is important to include all stakeholders to address them first. If a table has billions of records and users want to search frequently in a column of type NVARCHAR (MAX), then serious discussion is needed about why users want to do this and if the alternatives are available. If that function is really important, then we have to take into account the level of resource consumption, which is extremely important.
Indexing for full-text is a feature in SQL SERVER that can create indexes that allow flexible string searches across documents. This includes wildcard searches. Although flexible, it is an additional feature that needs to be installed, configured and modified. For string-focused search, it may be the most perfect solution.
One last available solution and a great solution for short string columns. N-Grams are string segments that can be stored separately from search data strings and can provide finding substrings without having to scan a large table. Before discussing this issue, it is important to fully understand the search rules used in the application. For example:
- Is there a minimum or maximum number of characters allowed in the search?
- Are blank searches (table scans) allowed?
- Are there many phrases / syntax?
- Do we need to save the substring that starts a string? It can collect with index if necessary
When these solutions are evaluated, we can take a column and divide it into string segments. For example, consider a search system in which the search length is at least 3 characters and is stored. Here are the sub-strings of the word “Dinosaur” saved ino, inos, inosa, inosau, inizard, nos, nosa, nosau, nizard, osa, osau, osaur, after, saur, aur.
If we create a separate table that stores these strings (also called n-grams), we can associate those n-grams with the record that has the column containing the word “Dinosaur”. Instead of scanning a large table to find the results, we can search the n-gram table. For example, if we search for the “dino” wildcard, the search can be redirected through the following query:
1 2 3 4 5 6 | SELECT n_gram_table.my_big_table_id_column FROM dbo.n_gram_table WHERE n_gram_table.n_gram_data = 'Dino'; |
Assuming n-gram is indexed, it will then quickly return the id of the large table with the word “dino” anywhere in it. The n-gram table requires only 2 columns and we can bind the size of the n-gram sequence using the rules outlined above. Even if this table becomes large, it is still very quick to search
Forget hitting indexes
SQL SERVER provides an interface to let us know when indexes are missing:

This alert tells us that there is a way to improve query performance. The green text gives us the details of the new indexes but we need to do some work before considering the advice from SQL SERVER.
- Is there an index similar to this one that can cover this case?
- Do we need to index all the columns? Or just index on sorted items?
- Impact of indexing? How does it improve query performance?
- Does this index already exist, but for some reason, the SQL SERVER optimizer doesn’t select it?
Typically, proposed indexes are numerous. For example, this is the index statement created for the partial plan shown above:
1 2 3 4 | CREATE NONCLUSTERED INDEX <Name of Missing Index, sysname,> ON Sales.SalesOrderHeader (Status,SalesPersonID) INCLUDE (SalesOrderID,SubTotal) |
In this case, there is an index above SalesPersonID. The state that occurs is a column in which the table consists mainly of only one value, meaning that as a sorted column, it will not provide many values. 19% of impact has no value. We will need to ask if the query is important enough to warrant this improvement. If it is done 1 million times a day, 20% improvement in the query is a must.