Humans have been storing information for a very long time. From rudimentary methods such as stone carving, book recording, cassette tapes, floppy disks, files… to today are database systems. In the modern era, databases are everywhere and are used to enhance our daily lives. From cloud storage to e-commerce, many of the services we use today are made possible by databases.
Today, invite you to learn about the popular types of databases today and their applications.
Database Classification
A database is an organized collection of data that is stored and accessed electronically.
Database-related disciplines that we often encounter include:
- Data modeling
- Efficient data storage
- Query language
- Security
- Distributed computing – including concurrent access support and fault tolerance.
Database technologies from their inception to the present have passed through generations in various forms with the aim of providing a consistent and efficient way to store and access data continuously through the development of management systems.
Relational-databases were born and widely used in the 1970s and 1980s. Relational Database Management System, or RDBMS, has become a recognized term and used as a standard and is still a legacy today.
Besides, around the end of the 20th century appeared a type of database called NoSQL (Non-Relation Database). However, it was not until 2009-2010, when the amount of data became too large to make ordinary SQL difficult, that we saw the extremely strong return of NoSQL along with a series of technologies for big data processing and distributed computing.
Today, the two most popular database management systems in use are still:
Relational Database (SQL)
A relational database , also known as an SQL database, is a system that stores data in the form of tables and rows (also known as records). In each table stores information about an object and the values of their attributes. For example, below we have an example of storing product customer information and purchase history.
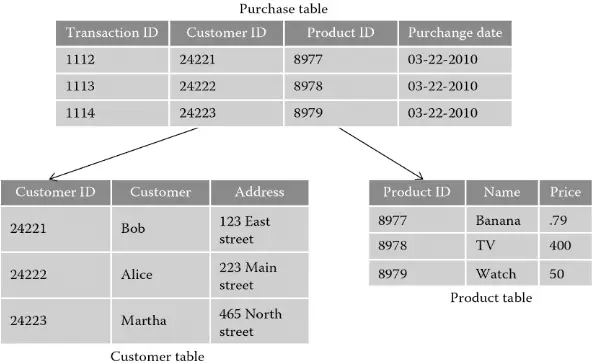
A relational database consists of the following components:
- Tables : Data is structured in the form of tables containing information, a database usually consists of many tables that make up a relational schema.
- Records (Records/Rows) : Rows of a table in the database, corresponding to an object and containing information about the object to be stored.
- Attribute fields (Columns/Fields) : Characteristics of objects stored in the database, for example, for customer information, we need attribute fields such as name, address,…
- Keys : A key is a special field that creates a relationship between tables.
- Primary key : In each table, there is a primary key field with a unique value for each record, which identifies that record.
- Foreign key (Foreign keys) : is a field in one table that points to the primary key field of another table, which has the effect of linking the tables.
- Relationships : Describes how tables are linked via keys and share information.
- One-to-one : each record in one table corresponds exactly to the record in the other table. For example: a person has only 1 citizenship identity.
- One-to-many : each record in a table can be associated with many records in another table. Ex: A person can have multiple home addresses
- Many-to-many : similar to one-to-many but bidirectional. For example: a person can have many addresses and conversely in an address can have many people live.
- Database Schema : The blueprint for the database, describing how we will store information and how that information will relate to each other. Includes rules for fields, table relationships,…
- Indexes : indexing one or more fields makes searching in the database easier and faster.
In addition, relational databases are known for their transaction processing capabilities, which guarantee the following 4 ACID (atomicity, consistency, isolation, and durability) properties.
| Attribute | Funtion | description |
|---|---|---|
| Atomicity | Transaction Manager | Transactions involving multiple operations are only successful when all operations are successful |
| Consistency | Application programmer | Data needs to return to the state before the transaction if an error is encountered (rollback) |
| Isolation | Concurrency Control Manager | Execute independent transactions concurrently |
| Durability | Recovery Manager | Ensure transaction data is stored even in case of system failure |
The most popular relational databases today are Microsoft SQL Server , Oracle Database , MySQL and IBM DB2 . Several free versions of these RDBMS platforms have grown in popularity over the years, such as SQL Server Express, PostgreSQL, SQLite, MySQL và MariaDB.
Advantage:
- Works with structured data, is table and row oriented so it’s very intuitive
- The relationships in the system have constraints, which promote a high level of data integrity.
- Provides the ability to write complex SQL (structured query language) queries for powerful data manipulation, analysis, and reporting
Defect:
- A major disadvantage we can easily see is that it is difficult to modify and expand due to the increasing number of connections.
- The data structure needs to be predefined before adding data.
Non-relational database (NoSQL)
In fact, the part systems we build do not necessarily require relational data. Not all software requires consistency, accuracy in complex transactions or queries. Typically Facebook Messenger , where we hope to be able to message 24/24 with more visitors than precise transactions. Facebook also understood that, so they built Cassandra, one of the famous opensource NoSQL-Databases later licensed by Apache.
Many NoSQL databases sacrifice consistency (mentioned in the CAP theorem ) in favor of availability, partition capacity, and access speed.
There are 4 common Nosql-Database types:
1. Columns:
As the name implies, data in the database is stored as columns instead of rows.
Inspired by Google Bigtable , data is organized as columns, separated by the value of one or more properties. Each column usually has only Name, Value, TimeStamp
Column-DBMS uses the same keyspace as the database schema in an RDBMS so it can be considered a semi-relational database. Each key is used to store metadata for the column-family. The column-family can be thought of like a table in an RDBMS, consisting of a family of related columns. The example below shows the equivalence between the AuthorProfile table and its column-family.
As we can see the data is separated into columns and grouped into column-family with key (in the picture is based on author name). Obviously, if we store it like normal SQL, there will be a lot of null values, leading to a waste of storage space. In addition, as the query splits into queries on columns, it results in faster performance in query, search, and aggregate functions.
Columnar database is used in the field of storing large data, the operation is more read than write data.
Famous databases based on Column: Cassandra , HBase , Vertica
2. Key-value:
Simple data is stored as (key,value) , data prices may not be of the same type. In terms of query speed extremely fast and highly scalable.
Basically key-values are considered as tables with only 2 columns and no joins like tables in SQL. These databases are usually simple, small in size, distributed in many places and stored in RAM to increase processing speed.
Typical key-value databases: CouchDB , Dynamo , Redis , Riak , Berkeley DB
3. Documents:
Is an extension of Key-Value , where values are stored in structured documents like XML or JSON. Document makes it easy to map objects in an object-oriented way to a database.
The document database doesn’t have a fixed schema, you don’t need to define the schema in advance and stick to it. It allows us to store complex data in document formats (JSON, XML, etc.) in a very flexible way.
The document database does not support relations. Each document in the repository is independent and has no relational integrity. This helps us reduce a lot of linked tables as well as nested-joins like in SQL. We can completely access multi-level nested properties instead of having to join complicated tables.
Some commonly seen Document Database today: Apache CouchDB , DocumentDB , MongoDB , OrientDB , Elasticsearch
4. Graph:
The above non-relational data models store information about entities such as key-value values, rows in multi-column tables or documents. However, the growing number of graph-oriented association datasets, such as Semantic Web , Web Mining has created a need for efficient entity relationships. This has spurred the emergence of graph databases to efficiently store these datasets and provide efficient operations for querying and analysis.
These databases are based on a strong graph theory foundation, where the graph consists of vertices representing entities and edges representing relationships between them. There are many ways to build a graph-database such as based on undirected graphs, labeled graphs or attribute graphs, etc. Here is an example in a sematic Web representation using the RDF standard. Relationships are represented by triples (Subject, Predicate, Object) and are mapped by RML each time a URI is queried.
Popular graph databases: AllegroGraph , Neo4J , OrientDB , Virtuoso , Stardog .
Advantage:
- Available: Data is usually distributed over several servers and regions, thus more stable and flexible.
- Performance: NoSQL delivers excellent query performance in both throughput and latency.
- Scalability: Non-relational databases are dynamically scalable and scale horizontally instead of vertically, which provides a clear advantage over SQL databases.
- Flexible: Unstructured and predefined data types give us flexibility during system development.
- Data models: diverse data models, which tend to be extremely specialized in specific use cases, allowing them to outperform relational databases.
Defect:
- Does not yet support transactions on multiple documents well. Typically consistency (Consistency – “C” in ACID) will need to be trade-off with Available and Performance properties as mentioned in the CAP theorem .
- Inefficient for complex queries that use multiple joins.
- Incomplete: Relational models have been around for a while compared to NoSQL models, and as a result they have evolved into more functional and stable systems over the years.
SQL vs NoSQL
| SQL | NoSQL |
|---|---|
| Data several Gigabytes to Terabytes | Data from Petabytes(1kTB) to Exabytes(1kPB), Zetabytes(1kEB) |
| Concentrate | Disperse |
| Structured | Semi-structured or unstructured |
| Structured Query Language | No declarative query language |
| Complex Relationships | Less complex relationships |
| ACID Property | Eventual Consistency |
| Transaction priority | Prioritize availability, expand |
| Joins Tables | Embedded structures |
summary
Just like the beginnings of database history and database management, the future will be associated with overall developments in data processing and computation. Machine learning and artificial intelligence will continue to improve and become an integral part of databases and database administration. Faster and more efficient database management tools will be built and evolved on legacy standards. In the end, the future looks extremely bright for the database industry. ⭐
Hopefully, this article can help you better visualize database management systems and their applications. In the next sections, I will continue to talk about the components and techniques in the Database, if you are interested, please read it. 💖
References:
- https://en.wikipedia.org/wiki/Database
- https://blog.airtable.com/what-is-a-relational-database/
- Davoudian, A., Chen, L., & Liu, M. (2018). A survey on NoSQL stores. ACM Computing Surveys (CSUR), 51(2), 1-43.
- https://www.quickbase.com/articles/timeline-of-database-history
- https://database.guide/what-is-a-column-store-database/