
Foreword
In the first part of the article MySQL Architecture and History , I introduced the most basic concepts as well as “interior” in our MySQL house. After grasping the interior of the house, we will use them as effectively as possible. In this article, I will introduce the first 2 methods to optimize MySQL. It is schema optimization, and data type optimization. We don’t always need to follow but the rules are learned in school. Sometimes redundant data helps to increase the performance of the system significantly. No sliver bullet – that’s the nature of Software Engineering.
Select the appropriate data type
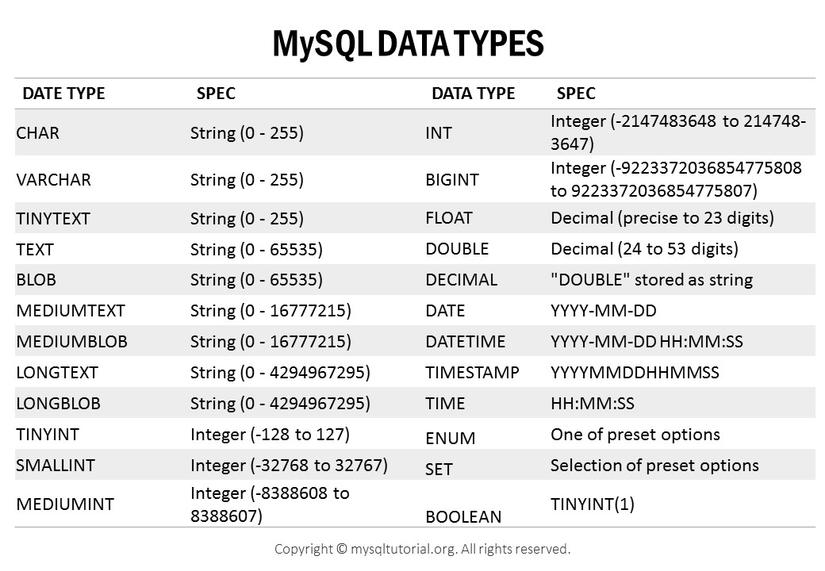
As we all know, MySQL “home” has a “kitchen” that is the data type. That kitchen has a lot of different spices. Choose the right spices to create the best food possible. Rules for selecting the appropriate data type:
Compact is usually better
This is also a fairly straightforward rule, because the smaller data type uses less memory on disk, cache, and internal memory. They also require less CPU cycles to process. It’s not foolish to use BIGINT to store fields as age in the persons table. Unless we have a record, Sun Wukong.

Simple is good
Using simple data types will help us reduce the number of processing operations to achieve the desired results. For example, you should store dates in MySQL with DATETIME data types instead of text types. Understand simply because string is an array of characters. The comparison rule makes it difficult to compare dates stored by strings.
If possible, do not use NULL

NULL controls for queries become difficult to optimize. Because NULL makes indexing, indexing, and comparison of values very complicated. Although NULL is annoying, the improvement of system performance in moving from NULL to NOT NULL is not much, so we need to consider finding and changing priority on existing tables. Unless you see NULL is causing problems.
Thus, from the points noted above we will have 1 flow to select the appropriate data type.
- First, we have to see what is the common layer of the column we are considering: numeric, string, or datetime, …
- Next, choose your own data type. For example DATETIME and TIMESTAMP can save the same data type: date and time, to the exact second. TIMESTAMP uses only half the memory as DATETIME . However, the allowable value of TIMESTAMP is less and its ability to bring is also less.
In the next part of this article, I will introduce the basic data types in MySQL.
Whole number
In MySQL, there are 2 types of numeric data: whole number ( real number ) and real number ( real number ). Integer data types include TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT. Here is a brief summary of these data types.
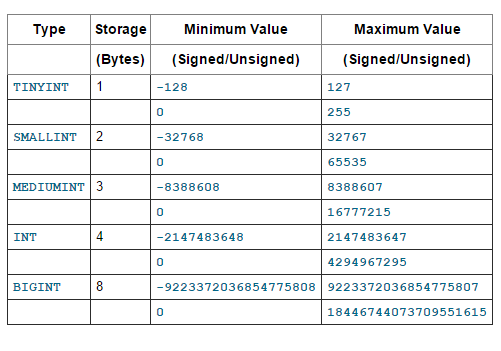
We can use the UNSIGNED attribute to not allow negative values and also to increase the upper limit value. For example, with the INT data type, the allowable range is [-2147483648, 2147483647]. If using UNSIGNED we have a new allowable value range of [0, 4294967295]. Interestingly, right ? MySQL allows you to specify “width” for numeric data types. For example INT (11) . However, this seems to be quite meaningless when, such saving does not limit the amount of INT allowed.
In terms of memory and computing power, INT (11) and INT (1) are the same.
Real number
Real numbers are the data types we approach slowly when we are in high school. It is a decimal data type. However, we can use DECIMAL to store large values that BIGINT is not enough to store. It is possible that the value of Bill Gates’s property when converted into VND for example.
FLOAT and DOUBLE support the approximate type approximation according to floating-point standards. Since the version of MySQL 5.0 DECIMAL supports accurate calculation. Because real numbers mostly revolve around floating point issues, I will not cover this article. You can refer to the floating-point documentation on the Internet to understand why in some languages 0.1+ 0.2 == 0.3 is false. I will draw only a few small notes as follows:
- We need DECIMAL types when we need accurate calculations. The calculations that errors can be ignored should use the other two data types because DECIMAL needs more space and cost to calculate than FLOAT and DOUBLE.
- We can use BIGINT to replace DECIMAL in some cases. For example, instead of saving 1/10000 1 cent of US (1 dollar = 100 cents). We can multiply the values in the table by 10 ^ 6 to save these values as BIGINT , to save space and computational costs.
String
VARCHAR and CHAR
Varchar Varchar stores strings as custom lengths. It may use less memory than a fixed length string. Because it will only use memory according to the length of the string. Varchar uses 1 or 2 bytes for length storage. 1 byte if the string length <= 255, 2 bytes if bigger. For example:
- VARCHAR (10) will use 11 bytes of storage
- VARCHAR (1000) will use 1002 bytes to store
Char Char is a fixed length string type. Char is useful when storing short data and column values are almost the same. Because Char k needs more bytes to store the length.
Blog and Text
Blog and text are two data types to store a large amount of data as well as binary strings, characters, … Unlike other data types, MySQL treats BLOB and TEXT as an object with the identifier of them. BLOB stores binary data without collation , or character sets. TEXT has its own set of characters and collations. (From here on collation, I couldn’t find a word so I left it up for your reference.)
Note: MySQL will not index the entire length of these data types, and cannot use the index for sorting.
Date and Time
MySQL has a variety of date and time data types. For example YEAR , DATE , … 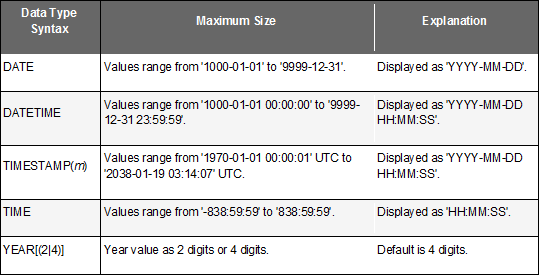
MySQL has two data types that ensure the accuracy of every second: DATETIME , and TIMESTAMP . TIMESTAMP uses 4 bytes of data storage compared to DATETIME ‘s 8 bytes so TIMESTAMP has a smaller value. You should note, if the application has you connected from different Time zones. With TIMESTAMP , the saved value will be correlated with the current Time zone, and with DATETIME , nothing will change, because the saved DATETIME value is treated as a text representing the date and time.
Above are the basic data types in MySQL, you can learn more other data types such as BIT , SET , …
Design effective schema
After saving the appropriate data types for the columns, we need to design an effective schema to achieve optimal results later. The following design issues will cause your DB performance to decrease:
Too many columns
This is understandable because a multi-column table query will take time for tables with fewer columns.
Too many joins
Too many joins when retrieving data also reduce the speed of the query
The column accepts Null values
In the first part of this article, I talked about the benefits of not accepting Null
From the above issues, we will have a way to avoid helping DB design more effectively. But not only that we need to normalize or denormalize the schema so that DB performance can be improved.
Normalization and Denormalization
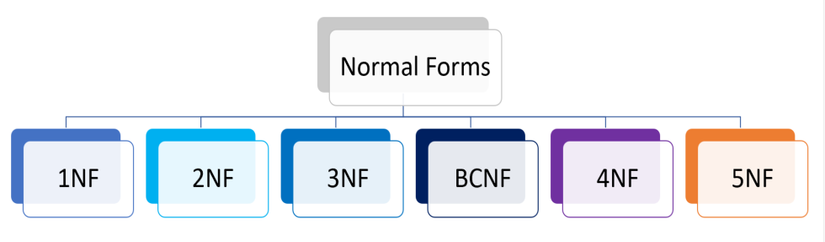
Normalization is a very good concept in DB to help avoid redundant data, helping to make the table structure more optimal. There are many standards of normalization such as 1NF, 2NF, 3NF, Boyce Code NF (3.5 NF), 4NF, … You can learn more about normalization here.
We will start with a simple example to understand a little bit about normalization as follows:
| EMPLOYEE | DEPARTMENT | HEAD |
|---|---|---|
| Jones | Accounting | Jones |
| Smith | Engineering | Smith |
| Brown | Accounting | Jones |
| Green | Engineering | Smith |
The obvious problem with this table is that the data may not be consistent when updated. For example, now Brown is in charge of the accounting department, we need to update many rows on this table. To solve this problem. We need to divide the original table into 2 tables, the employees table and the departments table as follows:
| EMPLOYEE | DEPARTMENT |
|---|---|
| Jones | Accounting |
| Smith | Engineering |
| Brown | Accounting |
| Green | Engineering |
| DEPARTMENT | HEAD |
|---|---|
| Accounting | Jones |
| Engineering | Smith |
Our tables are already type 2, and make data changes less costly.

The benefits and limitations of the schema are normalized
Benefit:
- Updating the data after normalizing is usually faster than before normalizing as you can see in the example above
- Normalized tables are usually smaller, so they require less memory
- Normalized tables help to avoid data redundancy, leading us not to need DISTINCT , GROUP BY in queries.
Besides the benefits that normalize brings, it also has limitations. As we can see from the division of 1 table -> 2 tables as above leads to many queries need joins. Joins is a very expensive action, and can result in us not being able to take advantage of indexes in these queries.
Benefits and limitations of schema do not normalize
The schema does not normalize to avoid joins with multiple tables to achieve the desired results when querying. We can use indexes because we don’t need joins for tables. Putting data into a table helps us to select the appropriate index type to make the query faster. For example, you have a website that allows users to post their news, some of them are “premium” members. If you use normalize, when you want to query the last 10 items from premium members, the query will look like this:
1 2 3 4 5 6 | <span class="token keyword">SELECT</span> message_text <span class="token punctuation">,</span> user_name <span class="token keyword">FROM</span> message <span class="token keyword">INNER</span> <span class="token keyword">JOIN</span> <span class="token keyword">user</span> <span class="token keyword">ON</span> message <span class="token punctuation">.</span> user_id <span class="token operator">=</span> <span class="token keyword">user</span> <span class="token punctuation">.</span> id <span class="token keyword">WHERE</span> <span class="token keyword">user</span> <span class="token punctuation">.</span> account_type <span class="token operator">=</span> <span class="token string">'premium'</span> <span class="token keyword">ORDER</span> <span class="token keyword">BY</span> message <span class="token punctuation">.</span> published <span class="token keyword">DESC</span> <span class="token keyword">LIMIT</span> <span class="token number">10</span> <span class="token punctuation">;</span> |
To execute this query, MySQL needs to scan the published index in the message table. For each record found, we have to go to the user table to check if it is a premium member. This is an ineffective query solution when only a small number of users are premium. With a schema denormalize, we have the following query:
1 2 3 4 5 6 | <span class="token keyword">SELECT</span> message_text <span class="token punctuation">,</span> user_name <span class="token keyword">FROM</span> user_messages <span class="token keyword">WHERE</span> account_type <span class="token operator">=</span> <span class="token string">'premium'</span> <span class="token keyword">ORDER</span> <span class="token keyword">BY</span> published <span class="token keyword">DESC</span> <span class="token keyword">LIMIT</span> <span class="token number">10</span> <span class="token punctuation">;</span> |
The query is more efficient because it prevents the join join and takes advantage of the index published
Combine normalize, denormalize
In fact rarely, we come across schema just normalize, denormalize. We often combine the two to bring the highest efficiency. A common way to denormalize data is to copy and cache columns from one table to another. Since MySQL 5.0, you can use triggers to update cached data.
Besides normalize, denomalize, we still have other techniques to improve DB performance. Continue !!!
Cache table and summary table
Sometimes, the redundancy of data greatly improves the performance of the system. But sometimes, we need to build separate tables for cache and summary purposes.
Summary tables often work faster to query results from GROUP BY operations . For example, you need to count the number of tatas posted on the webiste in the last 24 hours. You can use a summary table to count the number after each hour instead of having to query the messages table as well.
Cache tables are often used to optimize search queries. For example, you need different index types for 1 table data. But because MySQL does not support a table with 2 different storage engines, we can use a cache table. In the original table, if the storage engine is InnoDB , in the cache table (containing some columns from the original table) we can use the MyISAM engine. As such we will be able to query = index of both storage engines this supports. It is useful, isn’t it. 
When using the summary and cache tables, we need to decide whether updating the tables will be real time or periodic. Usually, a periodic update will save resources because we may only need to update once every hour. Make your choice depending on your application requirements. Here I will show some applications of the summary table and cache table.
Materialized Views
Many database management systems such as SQL Server and Oracle have a feature that is materialized views . This feature is similar to the summary table I just pointed out. MySQL does not yet support this feature, but you can use open source tools to build yourself
Counter tables
For example, a school needs to count the number of students in the school. Instead of counting each time a query is made, we can use a counter variable to count. This night variable will be changed every time a copy of a student is added or deleted. . Because counting is an extra cost every time you add or delete records. So we often apply this technique to tables that have few changes, but get a lot of queries
Epilogue
Thus, in this article I have presented some basic techniques to optimize performance by the method of optimizing data types and optimizing schema. In the next parts of this series, I will present other optimization techniques to make DB performance as efficient as possible. We hope for your support and suggestions. Happy coding. 
Refer
https://www.percona.com/blog/2015/01/20/identifying-useful-information-mysql-row-based-binary-logs/
https://viblo.asia/p/mysql-architecture-and-history-RQqKLkd057z
http://shop.oreilly.com/product/0636920022343.do
https://www.quora.com/What-is-normalized-vs-denormalized-data