1. Motivation
Personalization in news suggestions is very important for current online reading platforms, which increases the user experience significantly. Existing recommendation methods rely only on a single information representation of a story (e.g. title, body,…) and that is not enough. Therefore, a different approach is needed to increase the accuracy of suggesting news articles for users.
2. Donate
The authors propose a method to use neural networks to suggest news articles. The core is to use the users encoder and the news encoder. The basic idea is as follows:
- In the news encoder, the authors use an attentive multi-view learning model to learn a unified representation of a story from its title, body, and topic. We consider title, body and topic as different views of the article.
- Using word-level and view-level attention mechanism for news encoder to select important words and views, this makes news representation better.
- User representations are learned based on their browsing history, and the attention mechanism is used to select useful stories with the goal of learning user representations more effectively.
3. Method
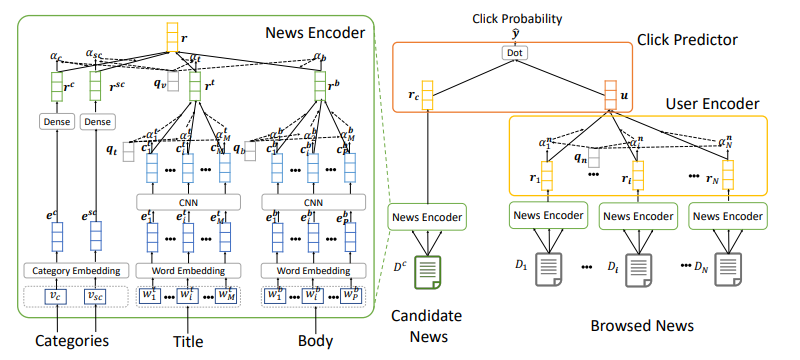
3.1. News Encoder
The news encoder module is used to learn the representation of a news story from information about the title, body, and topic of that news story. Because these information have different characteristics, we cannot combine them into a long text for learning to represent news stories. The authors propose an attentive multi-view learning framework to learn a unified representation for news stories by treating this information as specific views. There are four components in the news encoder.
The first component is the title encoder, which is used to learn the news representation from the title. There are 3 layers used. The first layer is word embedding used to convert the title of the article from a sequence of words to a low-dimensional semantic vector string.
The second layer is the CNN network. The local context of words is important in representing news headlines. For example in the title “Xbox One On Sale This Week”, the local context of the word “One” is “Xbox” and “On Sale” is useful for understanding that it is a game console. Therefore, the authors use CNN to learn the contextual representation of words by capturing the local context of those words. The way to calculate the context representation of words is as follows:
c i t = ReL U ( F t × e ( i − KY ) ⋅ ( i + KY ) t + b t ) c _ { i } ^ { t } = operatorname { R e L } U ( F _ { t } times e _ { ( i – K ) cdot ( i + K ) } ^ { t } + b _ { t } )
In there:
- e ( i − KY ) : ( i + KY ) t mathbf{e}_{(iK):(i+K)}^t is concat word embedding from position
- F t ∈ CHEAP WOMEN f × ( 2 KY + first ) EASY mathbf{F}_t in mathcal{R}^{N_f times(2 K+1) D} and
- WOMEN f N_f is the number of CNN filters and
The third layer is a word-level attention network. The goal of this layer is to pick out the important words in the title. attention . weight
α i w alpha^w_i
of the word th
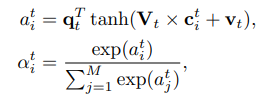
In there
DRAW w mathbf{V}_w
and
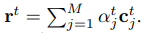
The second component in the news encoder module is the body encoder built to learn the news representation from the body of that news story. The construction idea is exactly the same as the title encoder.
The third component is the category encoder used to learn the story representation from the topic of that article. The input of the category encoder is the ID of the category
v c v_c
and the ID of the subcategory
- The first layer is an embedding category ID layer. This layer transforms from discrete IDs into low-dimensional dense representations.
- The second layer is a dense layer that is used to learn hidden representations of the category according to the following formula:

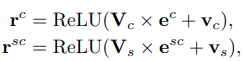
The fourth component is attention pooling. According to the author, the types of news stories have different levels of importance. Depending on the article, we will weight the importance of title, body and topic. Call
α t , α b , α c alpha_t, alpha_b, alpha_c
and
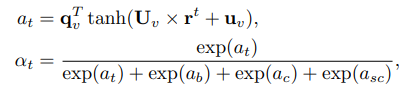
The other attention weights for body, category, and subcategory are calculated similarly.
The final representation of the story is the sum of the weighted products with the story representations of the different views.
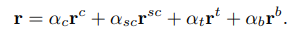
3.2. User Encoder
User encoders are used to learn user representations from news articles they have viewed. Based on the idea that the articles users see are related to each other. The authors use news attention network to learn user representation by selecting important news stories.
The attention weight of the news story
i t H I th}
approved by user
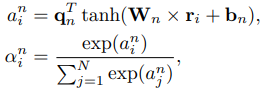
in there
W n , b n mathbf{W}_n, mathbf{b}_n
and
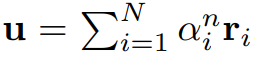
3.3. Click Predictor
The idea of click predictor is the same as in the article Neural News Recommendation with Multi-Head Self-Attention. Click predictor module is used to predict the probability that a user clicks on a candidate post. That probability is calculated as the dot product of the user vector and the news vector.
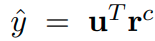
The authors also study other scoring methods, but the dot product is still effective and gives the best performance.
3.4. Model Training
The idea of model training is the same as in the article Neural News Recommendation with Multi-Head Self-Attention. The authors use negative sampling technique to train inter-models. The idea is as follows:
- For each article viewed by the user (positive sample), we take it at randomKY KY news samples are also displayed at the same time but the user does not click on it (negative sample).
- Shuffle the order of posts to avoid positional biases (simply understood that the position of the article on the message board greatly affects the user’s click to view). The formula for calculating the probability of a user clicking on a postive sample is standardized as follows:
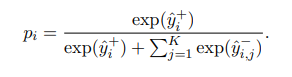
The loss function used is the negative log-likelihood of all positive samples
S mathcal{S}
is calculated as follows:
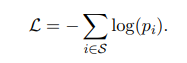
4. Experiments
The group of authors experimented on the actual data set with the following statistics:

The proposed method of NAML is better than the other methods.
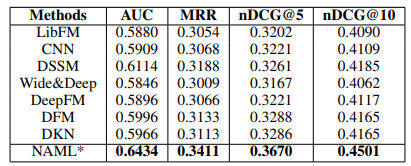
Effective when using the multi-view learning framework approach and the attention networks.

The author group actually visualized the attention weight in different views and found that the weight values of title and body view are mostly small.
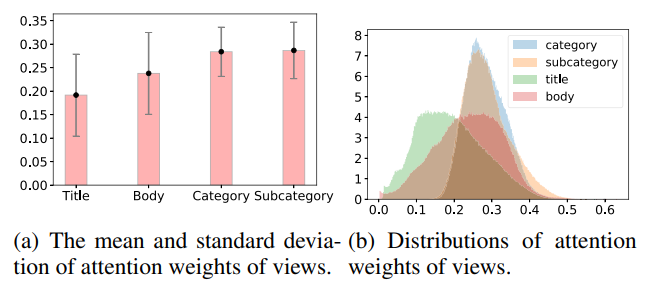
This may be because the title and body are ambiguous and not useful for learning to represent the story. In this case, the category can provide additional information to the recommendation system and this has been proven to be as effective as the model proposed by the paper.
5. Conclusion
The good point of the article is that it makes the most of the information contained in an article (title, body and topic). The main idea of the encoder is still to use the attention mechanism and the learning method is not too complicated. The difference lies in the multi-view element to represent the news effectively.
6. References
[1] Neural News Recommendation with Attentive Multi-View Learning
[2] Recommender Systems: Machine Learning Metrics and Business Metrics – neptune.ai
[3] IJCAI2019-NAML/NAML.ipynb at master wuch15/IJCAI2019-NAML ( github.com )