Neo4j Cypher
- Tram Ho
1. Introducing the Cypher query language
Cypher is a graphical database querying language, with which we can interact, such as querying, updating or administering effectively with a graph database. This language is designed to make it convenient for both developer and professionals to work with neo4j. Cypher is inherently simple by design, yet it’s very powerful.
Cypher is inspired by many different approaches, some keywords like WHERE, ORDER BY are inspired by SQL language, while pattern matching is borrowed from SPARQL. Also some semantics are borrowed from other languages like Haskell and Python. Cypher’s structure is based on the English language, with semantics convenient for manipulating the language, which makes writing and reading queries easier as well.
Structure
Cypher has a structure similar to SQL. Queries are built from many different clauses. Clauses are chains linked together. Below are some examples of using clauses to read data from a graph database:
- MATH: matches matching patterns. This is the most common way to get data from graphs
- WHERE: is not a regular clause, but it is part of MATCH, OPTIONAL MATCH and WITH. WHERE will add constraints to the pattern, or filter the results obtained through WITH
- RETURN: returns the result
We will better understand MATCH and RETURN through the following example:
1 2 3 4 5 6 7 8 | CREATE (john:Person {name: 'John'}) CREATE (joe:Person {name: 'Joe'}) CREATE (steve:Person {name: 'Steve'}) CREATE (sara:Person {name: 'Sara'}) CREATE (maria:Person {name: 'Maria'}) CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve) CREATE (john)-[:FRIEND]->(sara)-[:FRIEND]->(maria) |
The figure below will illustrate the Graph that we have created:
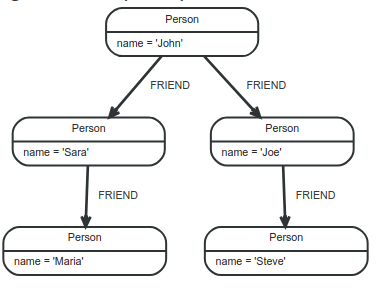
With the Graph above, if you want to write a query to find a user named John and his friends (you can understand indirectly here), we can write the following:
1 2 3 4 5 | MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof) RETURN john.name, fof.name # Kết quả sẽ trả về *"Maria"* và *"Steve"* |
Next let’s add a filter to the query, assuming we have a list of the names of the users and now we want to find out all the nodes in the database match the names in the other list. Along with finding nodes we also have to return information of friends of those nodes provided that the name begins with the letter “S”.
1 2 3 4 5 6 | MATCH (user)-[:FRIEND]->(follower) WHERE user.name IN ['Joe', 'John', 'Sara', 'Maria', 'Steve'] AND follower.name =~ 'S.*' RETURN user.name, follower.name # Kết quả sẽ trả về *"Sara"* và *"Steve"* |
Above are examples of how to use the propositions in graph, in addition to the statements above we also use a number of other propositions:
- CREATE (or DELETE): used to create or delete nodes or relationships
- SET (or REMOVE): SET will be used to set trji values for attributes and assign labels to nodes and REMOVE will be used to delete them.
- MERGE: Used to Match existing ones or create new nodes or patterns, MERGE is useful when we use it in combination with unique constraints.