Multi Task Learning (MTL) is not a new method, but its level of effectiveness has been recognized by a large number of researchers. In this article, I will give an overview of multitasking learning including the dynamics behind using, the benefits, and some methods of using Multi Task Learning in Deep Learning in which we will only focus. Auxiliary tasks, mainly on auxiliary tasks.
I. Introduction:
Traditional machine learning methods focus on solving a single task with a single model. This can cause us to ignore information that could help us perform better on the task we care about, coming from other tasks related to it. Take a simple example when you want to predict the price of a house based on a number of features such as area, number of rooms, number of floors, proximity to any commercial mids or not, etc. .. then obviously adding a few tasks like predicting this house is in the inner city or suburban or whether it’s a villa or an apartment will give us a lot of information for predicting its price.

Figure 1: Instead of just predicting home prices, we can predict other information that gives us the benefits of price prediction.
From a professional perspective, Multi Task Learning allows tasks to share a common representation of data, so that we can capture a potentially more generalized model on the original task in which we are care.
Multi Task Learning is also known by several names such as Joint Learning, Learning to Learn, Learning with Auxiriary Task, every time we work on an optimal problem with more than one loss function, we assume that We are solving a problem related to Multi Task Learning.
II. Motivation:
Biologically, multitasking learning is inspired by the way people learn, when we need to learn to perform a new task, we often apply the knowledge we have acquired through. through learning from the assignments involved. For example, a child will learn to recognize where a face is and then be able to apply those knowledge to object recognition.
From a pedagogical perspective, we often learn skills that provide the foundation for us to learn more complex techniques. Finally, from a machine learning perspective, Multi Task Learning provides an inductive bias which will bias models that can solve more than one task.
III. Benefit:
Let’s assume that we have 2 related missions A A A and B B B , I will give some benefits of Multi Task Learning when studying at the same time A A A and B B B.
III.1. Data Augmentation
Multitasking effectively increases the size of the sample set we use in the coaching process. Because each task contains some noise. When training the model on the mission A A A , our goal is to find a representation for A, which is ideally good if it’s generalized and independent of noise. Because tasks all contain different noise paterns, a model of learning two tasks at the same time is likely to learn a more general representation. Learning A A A risk of overfitting A while studying at the same time A A A and B B B allows the model to learn a better performance by averaging the noise paterns for each task.
III.2. Attention Focusing
If a task contains a lot of noise, or the data is limited and located in a space with some height. It will be very difficult for our model to differentiate between relevant and unrelated features. Multitasking can help the model focus its attention on truly important features, because other tasks will provide useful information for discovering what is an important feature and what is. is not important,
III.3. Eavesdropping
Some of the features can be very easy to learn by the task B B B while it is very difficult to A A A can learn it, this will be far away A A A interacts with those features in a very complex way, or learning of other features is hindering the ability to learn the characteristic. A A A. Through the MTL, we can learn features that are difficult to learn with A A A , through B B B. An effective way to do this is that we will directly train the model to predict important features.
III.4 Representation bias
MTL bias is not only useful on a particular mission, but on many different missions. This allows us to generalize on a class of tasks, performing well on a set of tasks will give us the ability to perform well on a new task in the future, as long as the tasks. This department also shares the same environment.
III.5 Regularization
MTL is capable of reducing overfitting by bias useful representations across multiple tasks, so the likelihood of the model overfitting on a given task is reduced.
IV. Multi Task Learning in Neural Network:
MTL has many different uses, but in the context of Deep Learning, I would like to introduce only two methods: Hard Parameter Sharing and Soft Parameter Sharing .
IV.1. Hard Parameter Sharing.
Hard Sharing is a method that is used a lot in Neural Network. It is done by sharing the hidden layers above all the tasks, while keeping only the output layers being different.
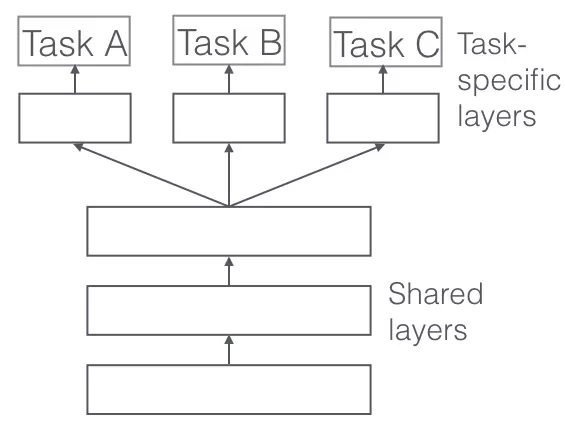
Figure 2: Hard Parameter Sharing.
Hard parameter sharing reduces overfitting very well. Sharing hidden layers between tasks forces our model to learn the appropriate general representations on multiple tasks, so the likelihood of overfitting on a particular task is reduced. so many, so much.
IV.2. Soft Parameter Sharing.
Soft Parameter Sharing is completely different, each task will have its own model, as well as its own parameters, however the spacing of parameters between the tasks will then be bound to make these parameters. There is a high degree of similarity between the missions. Here we can use Norms to constraint.
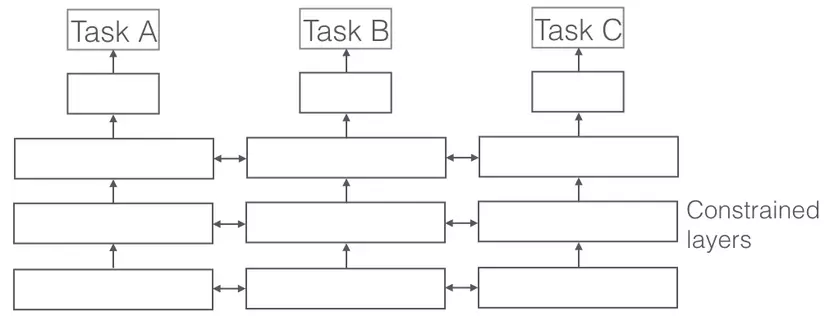
Figure 3: Soft Parameter Sharing.
If you have heard of Ridge Regression this method has quite a lot in common with it, except that Ridge Regression constrains parametric strength, and Soft Parameter Sharing will bind distance.
V. Auxiliary task:
In many cases, we only care about the performance of a specific task, but we want to take advantage of the benefits that MTL offers, in cases like this we can add some Tasks are related to the main task that we care about with the aim of further improving performance on the main task. These tasks are called Auxiliary tasks.
How the use of Auxiliary tasks vs. Main tasks has been a long-standing problem, however, there is no solid theoretical evidence that using Auxiliary tasks will result in an improvement in the main task. Below I will point out a few empirical suggestions from previous studies regarding how to use auxilirary tasks effectively.
V.1. Share Layers. But Share What?
This is a question that has been posed for a long time, previous studies have shown that low-level tasks (such as POS tagging or NER) should be used at the lowest layers, in contrast to the high-levels. Tasks that require more information can be used on the top layers (such as Chunking, Dependency Parsing or Relation Extraction).
Specifically Sogaard, A. and Goldberg 2016 show that using POS on lower layers results in improvements in Chunking’s performance (which I did to confirm and see it correct). Meanwhile, Hashimoto et al. 2017 builds a linguistic tiered model for a different set of NLP tasks.
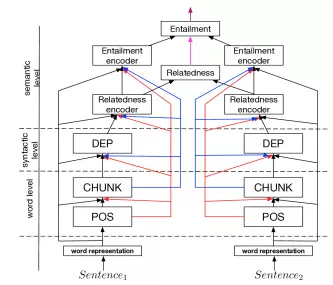
Figure 3: Stratified architecture proposed by Hashimoto.
V.2. Weighted Loss
When we work with MTL, that is when we are working with more than one loss function, since the final loss function is a weighted sum of the loss functions component.
L f i n a l = ∑ i λ i L i L_ {final} = sum_ {i} lambda_i L_i L f i n a l = i Σ λ i L i
Inside λ i lambda_i λ i is the weight of each loss function. Weight selection λ i lambda_i λ i How is an important job, the simplest you can choose λ i = c lambda_i = c λ i = c with c c c is any constant that can be searched for with cross validation.
V.3. Some of the commonly used Auxiliary Tasks.
Specific auxiliary tasks can be customized, but in general all Auxiliary Tasks can be classified into the following four categories.
Statistical: These are the simplest backend tasks, we will use tasks that predict the statistical properties of the data such as the Auxiliary Tasks. eg guessing Log Freqency of a word, Pos Tag, etc.
Selective Unsupervised:: These are the tasks that require us to predict a part of the input, specifically as in Sentiment Analysis we can predict when the sentence contains a Positive Sentiment or Negative Sentiment Word.
Supervised: These tasks can be Adversarial Tasks or Inverse Tasks or Data-related monitoring tasks (eg Predict Inputs for example). .
Unsupervised: These are the tasks involved in predicting all parts of the input data.
BECAUSE. Conclude:
Multi Task Learning is a not new method, but the effectiveness it brings is really no need to argue. Above is just a little introduction to MTL, you want to understand more deeply can refer to Phd Thesis below for more specific information. Next time I will probably introduce a method quite close to MTL that is Sequential Learning, hope you will support and follow.
VII. Refer.
https://ruder.io/thesis/neural_transfer_learning_for_nlp.pdf