Why have this tool?
Cha is one day the boss assigned me the task of learning about scrapy to scratch data, incidentally, a few days later I just bought a reading machine, so I also needed to search for free ebooks. That day I found sachvui.com that had a lot of free ebooks and I discovered that this web can make tools to get all the ebooks easily, today I would like to share the tools I wrote.
Let’s get to work
Read sachvui.com structure first
Before embarking on the code, let’s learn about the sachvui page structure and some basic knowledge about the XPath first.
- You go to https://sachvui.com/the-loai/tat-ca.html to list all ebooks offline
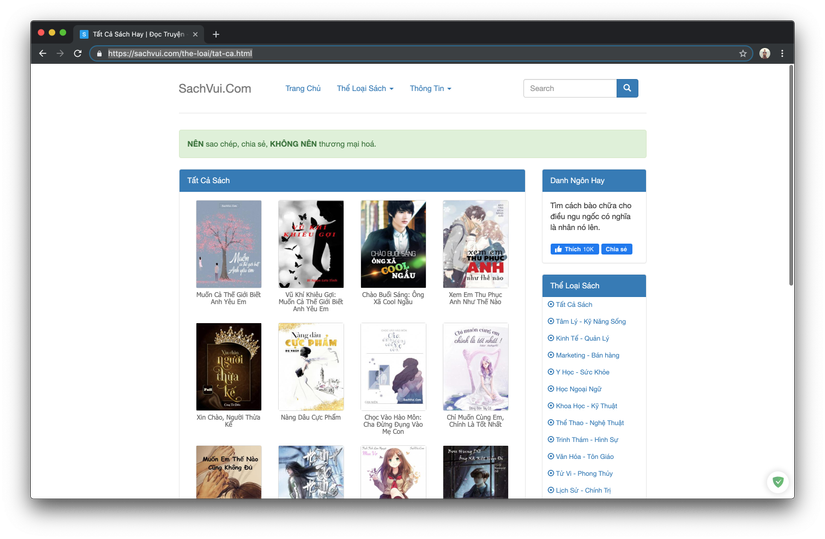
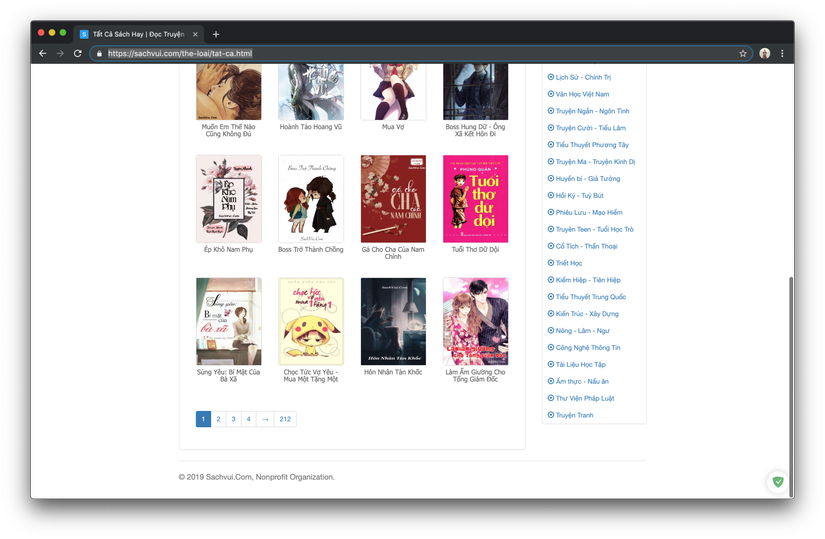
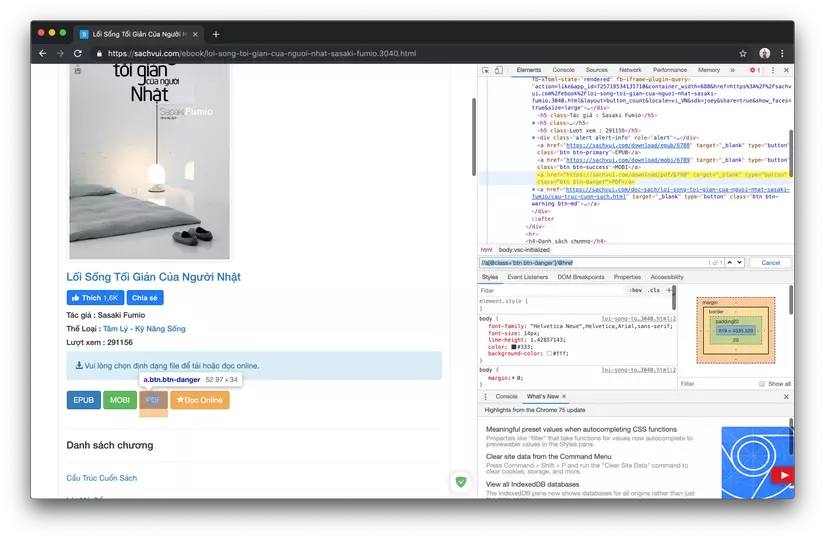
- Click on any ebooks and you will get to a page with a structure similar to the following:
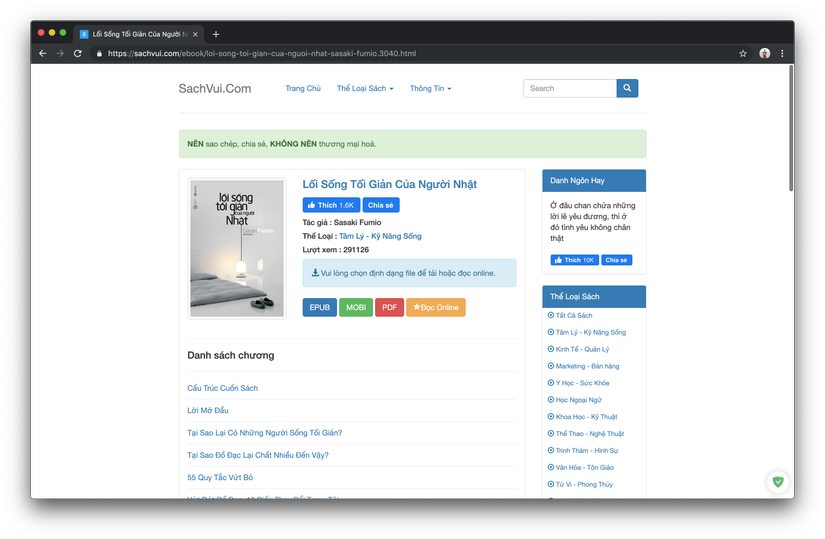
You can see the EPUB, MOBI, PDF items are the ebook download buttons with different formats, when you click on the ebook will start downloading. Note that not all ebooks have files to download
- Okey now you can understand the structure of it simply shows all the ebooks up in the form of pages (there are 212 pages per page of 20 books)
- Return to the page that opens all Inspect books and go to the Elements tab
- Press Command + F (Control + F with windows) to bring up the search box
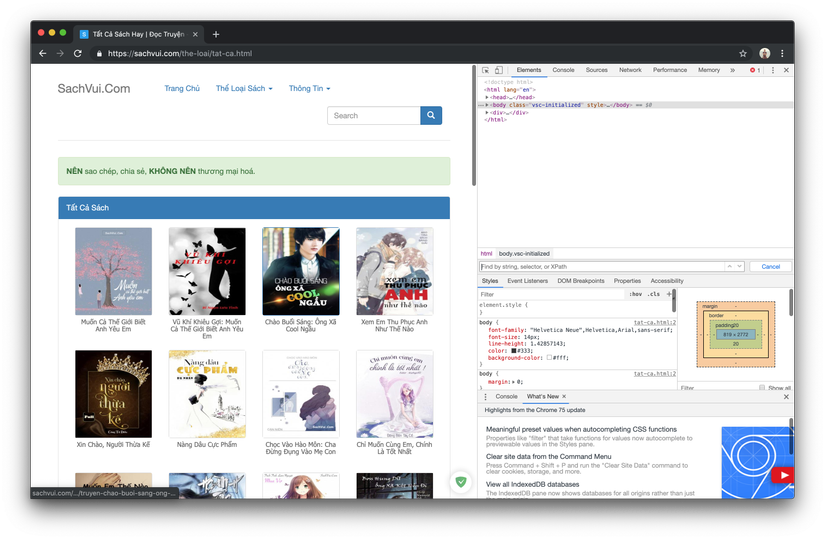
- Start typing XPath to get urls of ebooks (Please find out more about XPath). I took a simple example to use for you in this case:
Typing in
//div[contains(@class,"ebook")]will get as shown below.Simply put, you will get the div tags containing the class called ebooks, here there are 20 eye counting tests you can see that there are 20 ebooks present on the page, so our xpath seems correct.
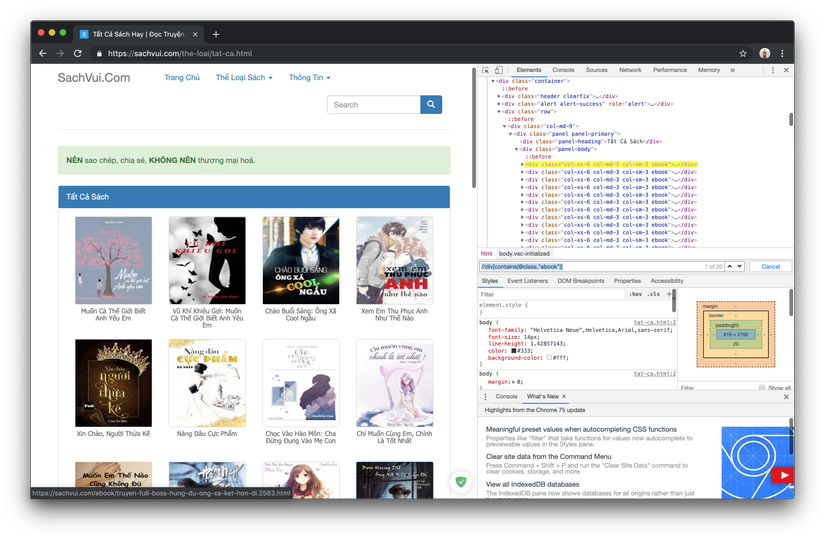
Bung div tag, you can see the first card containing a url of the page that contains the ebook that you spoon into, the work seems quite simple, we started updating the xpath to get a card that you update to the XPath
//div[contains(@class,"ebook")]/aIf you want to add xpath directly, you can update it to the following//div[contains(@class,"ebook")]/a/@hrefwe will be it later in the code.
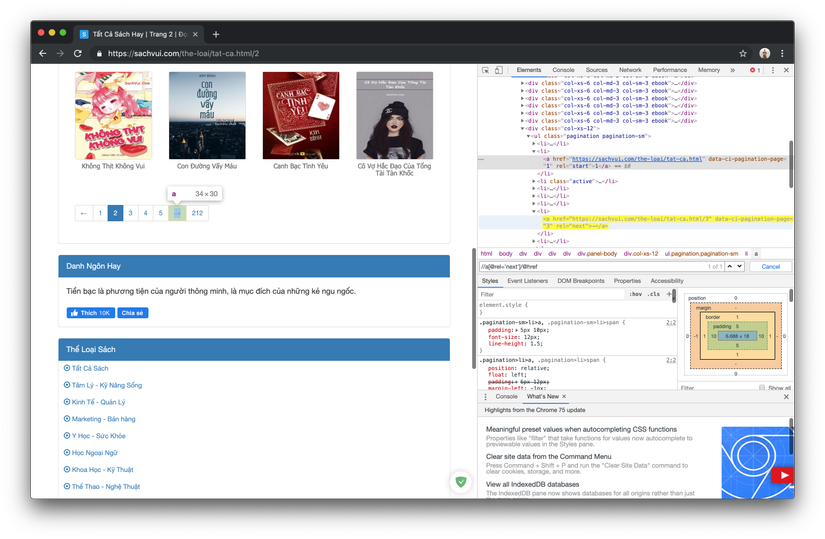
- Now we find the next button to make it easier for us to code later
We type the following xpath:
//a[@rel='next']/@hrefWe will get the url of the next button when clicked, then going to the next page to the next page. If you click like that, you will be able to see all the ebooks.
- Back to the ebook site we also use xpath to get the url of the download button
I have written the XPaths for you to use as follows. We will not pay attention to the online reading
EPUB:
//a[@class='btn btn-primary']/@hrefMOBI:
//a[@class='btn btn-success']/@hrefPDF:
//a[@class='btn btn-danger']/@href
The site structure is ok and now let’s get started on the code
environment settings
- First need to install python for the machine, how to install you learn google help me is also simple.
- Install scrapy.
pip install scrapy - Initialize project.
- First, you need to open the terminal (cmd in windows) and then move to the folder you want to store the project.
- Start typing in the terminal
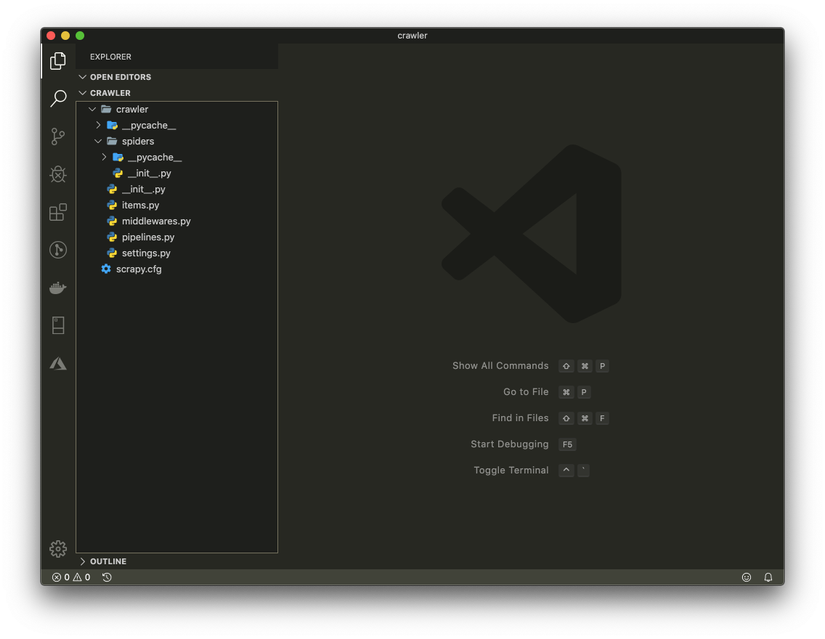
scrapy startproject crawler
A folder named crawler will be created, you use any IDE to open up, you use VSCode. You will get a project with the following structure:
- Create a file named
sachvui.pyin the spiders folder and copy this code into it
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | import scrapy class SachVuiSpider(scrapy.Spider): name = 'sachvui' def start_requests(self): urls = [ 'https://sachvui.com/the-loai/tat-ca.html' ] for url in urls: yield scrapy.Request(url = url, callback=self.parsePage) def parsePage(self, response): for page in response.xpath("//div[contains(@class,'ebook')]/a"): page_url = page.xpath('./@href').extract_first() yield { "url": page_url } |
The start_requests function will be run first
The
yield scrapy.Request(url = url, callback=self.parsePage)understands simply that when the request is made, the html page that is received will be processed with the parsePage function.Here we have the urls array is the list of urls that start running, the above url is of all books on sachvui.com , you can go to each category such as economy, finance, story or something to get another url if You just want to get one genre book.
- Go back to the terminal and type
scrapy crawl sachvui -o sachvui.jsonto run the test crawler - You will see a sachvui.json file has been created and saved to the url of the ebooks page of the first page into it.
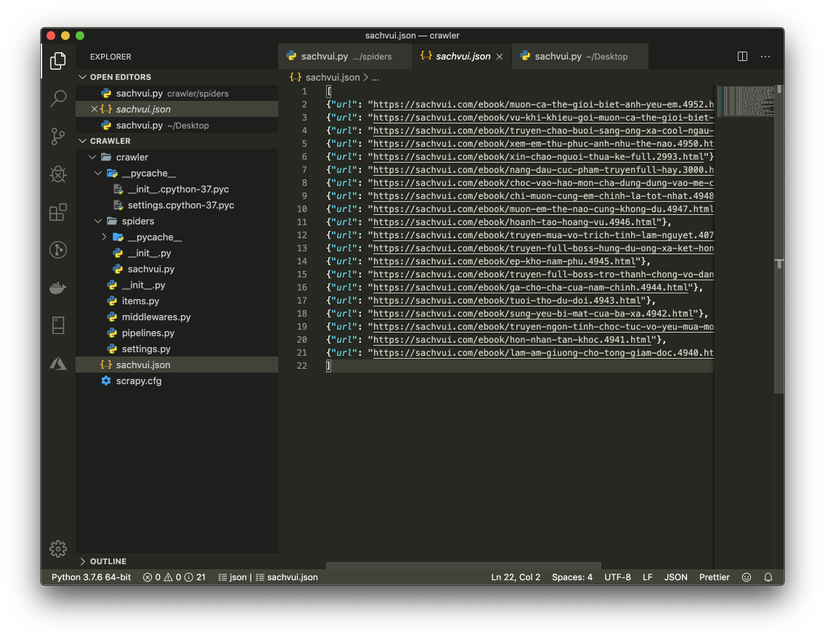
- The next step we need to simulate clicking the next button to go to the page, you update the code as follows
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import scrapy class SachVuiSpider(scrapy.Spider): name = 'sachvui' def start_requests(self): urls = [ 'https://sachvui.com/the-loai/tat-ca.html' ] for url in urls: yield scrapy.Request(url = url, callback=self.parsePage) def parsePage(self, response): for page in response.xpath("//div[contains(@class,'ebook')]/a"): page_url = page.xpath('./@href').extract_first() yield { "url": page_url } nextButtonUrl = response.xpath("//a[@rel='next']/@href").extract_first() if nextButtonUrl is not None: yield scrapy.Request(url = nextButtonUrl, callback=self.parsePage) |
Literally, the parsePage function will get the url data of all ebooks shown on the page, then we take the url of the next button and save it to the nextButtonUrl variable. Then we continue to create a new request with the above url, the parsePage function will be called on the next page Run the
scrapy crawl sachvui -o sachvui.jsoncommandscrapy crawl sachvui -o sachvui.jsonin the terminal and return to the file sachvui.json we will see all the ebooks page url somewhere more than 4,000 ebooks
- Now, we do not need to save the ebooks url to the sachvui.json file, but when the url is available, we go to that url to get the url of the download page, we update the code as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | import scrapy class SachVuiSpider(scrapy.Spider): name = 'sachvui' def start_requests(self): urls = [ 'https://sachvui.com/the-loai/tat-ca.html' ] for url in urls: yield scrapy.Request(url = url, callback=self.parsePage) def parsePage(self, response): for page in response.xpath("//div[contains(@class,'ebook')]/a"): page_url = page.xpath('./@href').extract_first() yield scrapy.Request(url = page_url, callback=self.parse) nextButtonUrl = response.xpath("//a[@rel='next']/@href").extract_first() if nextButtonUrl is not None: yield scrapy.Request(url = nextButtonUrl, callback=self.parsePage) def parse(self, response): epubUrl = response.xpath("//a[@class='btn btn-primary']/@href").extract_first() mobiUrl = response.xpath("//a[@class='btn btn-success']/@href").extract_first() pdfUrl = response.xpath("//a[@class='btn btn-danger']/@href").extract_first() yield { 'epub': epubUrl, 'mobi': mobiUrl, 'pdf': pdfUrl, } |
Clear the data in sachvui.json file then run the
scrapy crawl sachvui -o sachvui.jsoncommand then you can see all the download url will be saved to sachvui.json
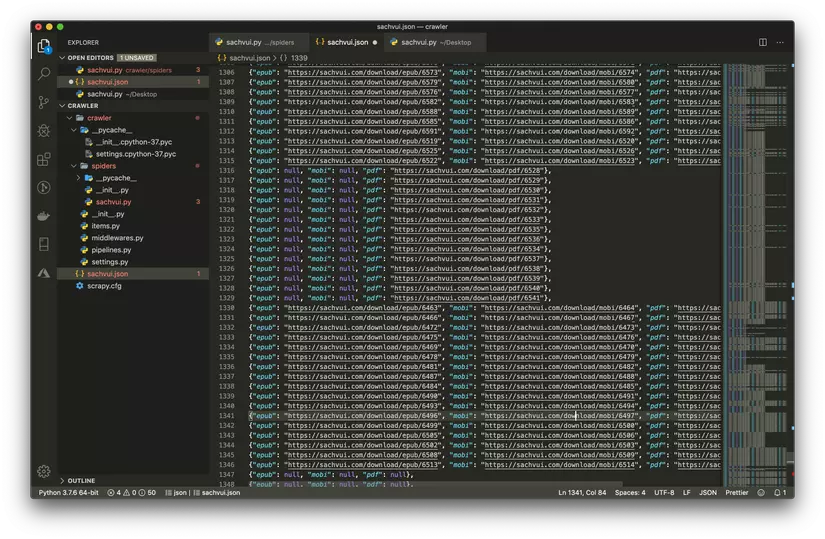
- There is a url and then write a download function, update the code as below
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | import scrapy import os class SachVuiSpider(scrapy.Spider): name = 'sachvui' def start_requests(self): urls = [ 'https://sachvui.com/the-loai/tat-ca.html' ] for url in urls: yield scrapy.Request(url = url, callback=self.parsePage) def parsePage(self, response): for page in response.xpath("//div[contains(@class,'ebook')]/a"): page_url = page.xpath('./@href').extract_first() yield scrapy.Request(url = page_url, callback=self.parse) nextButtonUrl = response.xpath("//a[@rel='next']/@href").extract_first() if nextButtonUrl is not None: yield scrapy.Request(url = nextButtonUrl, callback=self.parsePage) def parse(self, response): epubUrl = response.xpath("//a[@class='btn btn-primary']/@href").extract_first() mobiUrl = response.xpath("//a[@class='btn btn-success']/@href").extract_first() pdfUrl = response.xpath("//a[@class='btn btn-danger']/@href").extract_first() if mobiUrl is not None: yield scrapy.Request(url = mobiUrl, callback=self.download) def download(self, response): path = response.url.split('/')[-1] dirf = r"../sachvui/" if not os.path.exists(dirf):os.makedirs(dirf) os.chdir(dirf) with open(path, 'wb') as f: f.write(response.body) |
Run
scrapy crawl sachvuiand wait for the resultIn the above code, I just want to get the mobi file to use for reading machines, you want to get the remaining files, add the download code only
All downloaded ebooks are stored in the sachvui folder in parallel with the crawler folder
In
dirf = r"../sachvui/"you can change the location to where you want to save your ebooksHMM, download the same folder and lazy to split it too, you can use filter type in the folder to sort it out
Git repo: https://github.com/dpnthanh/EbooksCrawler.git
This is the end, the article is a bit sketchy as well as the knowledge is not wide enough and the first article I wrote, hope there is something wrong, please contribute your ideas to me, thank you for Read up to here