Consensus in a distributed system is always the most difficult issue when building a distributed computing system. Various solutions and designs have been born to solve this problem.
Raft is an algorithm that solves this well, as introduced in Part 1. And Raft has divided the consensus problem into three sub-problems:
- Leader Election
- Log Replication
- Safety
In this article, I will discuss the first issue is Leader Election .
The Role of Leader in a Raft Cluster
Raft is a Leader model consensus algorithm, where a Leader will be elected and it will be fully responsible for managing all other machines (cluster), namely that it will replicate the log it receives from the client side to all nodes in the cluster.
As shown in Figure 1 below, S1 is the node elected as Leader when the Raft cluster starts and it will be responsible for receiving requests from the client and replicating the logs containing the commands to the remaining nodes, after the cluster has reached a consensus. in the computation, S1 will return the response to the client .
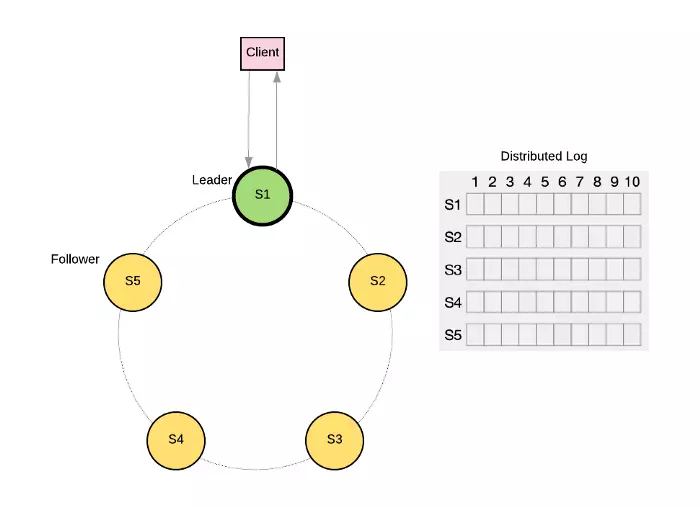
Figure 1. Raft cluster
In order for a node to be a leader , it must receive at least (N / 2 + 1) votes, where N is the number of nodes in the cluster. Thus, a Raft cluster must have at least 3 nodes or more to be active and 5 or more nodes to function effectively.
State rotation of a node in Raft
When a cluster starts to work or a cluster Raft is active but the leader of that cluster is disconnected, a new Leader will be elected through the voting process between the cluster member nodes. Therefore, at a certain time a node can only carry one of the following three states: Follower , Candidate , Leader .
Leader will be fully responsible for managing Raft cluster, capturing and processing commands sent from client side. And the Follower will be in a passive position and they only perform the requests of Leader and Candidate . When the Raft cluster falls into a state where there is no Leader (due to a faulty former Leader), any Follower can become Candidate and send requests to other members to request votes from them.
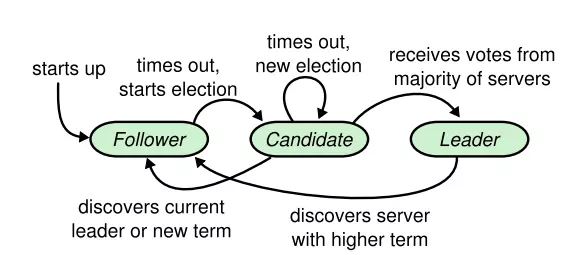
Figure 2. Node state transition.
Term (term) in Raft
In the Raft, times are divided into units called Terms (terms). As shown in Figure 3, each Term will be started with an election and then the elected Leader will serve until the end of the Term if it does not suffer any errors in the process of being a Leader.
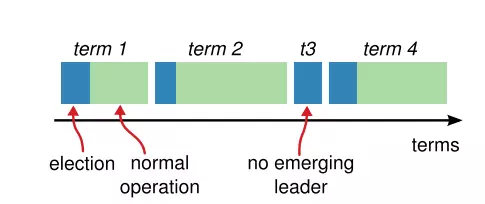
Figure 3. Term
In some cases, a vote of where 2 Candidates may receive the same number of votes (this is called split vote scenarios ) a new election needs to begin immediately. Terms are numbered incrementally to indicate what term it is, and this value is always included in the communication between cluster members. The cluster nodes will communicate with each other using RPC (remote procedure calls).
What does Raft use to detect an existing term in danger of ending and triggering a new one?
In the Raft, each node uses heartbeat mechanisms to detect that the current term has ended and a new election begins. That is, during normal operation, Leader will have to periodically send heartbeat messages to all members of the cluster to announce that it is still active and that the remaining nodes must maintain Follower ‘s state. If not, the other nodes will tell the current Leader is dead and trigger a new election.
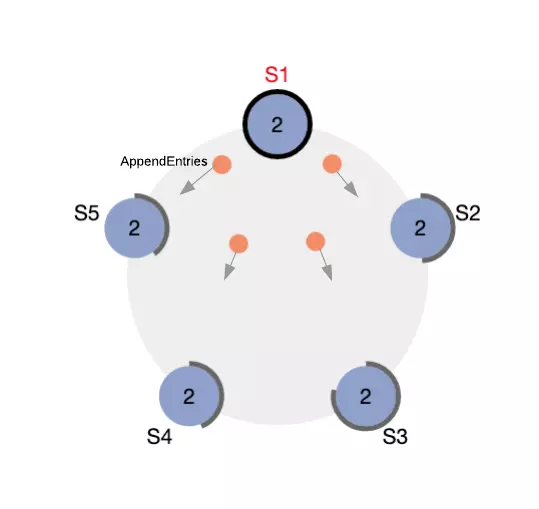
Figure 4. Heartbeat messages are sent periodically from Leader to Followers
Heartbeat has the same message type (that is, AppendEntries RPC) as the messages Leader uses to send new log entries to Follower , but those AppendEntries RPC have an entry field [] that is empty to denote that it is a Heartbeat message.
If a Follower does not receive a Heartbeat message during an election timeout it will initiate a new election.
Process of initiating an election
When a Follower after a period of timeout that it does not receive any AppendEntries RPC (either Heartbeat or the message containing log entries ) from the Leader it will consider the Leader failed and start a new election procedure by :
- Increase its currentTerm
- Vote for yourself and RequestVote RPC to the rest of the members to vote it to become the Leader.
In Figure 5 it is assumed that S1 is the node that reaches the first election timeout in the cluster, so S1 goes into the Candidate state and sends RequestVote RPC to S2, S3, S4, S5.
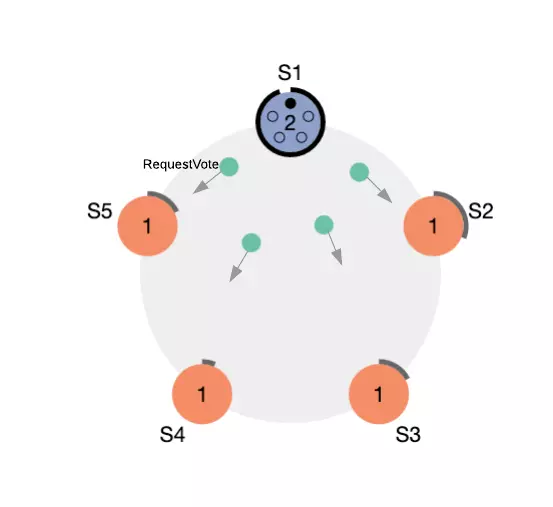
Figure 5. Election process, RequestVote RPC, votes
Possible outcomes of an election
Based on the responses that Candidate received from the cluster nodes, the election will likely end with one of three results:
- Candidate wins the election with a majority of the votes of the nodes in the cluster, when it gets from (N / 2 + 1) or more votes, in which, N is the number of nodes in the cluster.
- While S1 waits, it may receive an AppendEntries RPC from a node declaring it just became Leader.If Candidate’s currentTerm is lower than the term it received in the message, then S1 will give up and acknowledge it. That node is Leader.
- Split vote scenario : This situation can happen when multiple nodes become Candidate at the same time without a single Candidate receiving the majority of votes, this situation is called a split vote , when meeting must this situation every Candidates timeout and a new election will begin.
Randomize Election Timeout to limit Split Vote status
To minimize the chance of the Raft cluster falling into a split vote situation, Raft uses a randomize election timeout mechanism, in which case each node will have a different election timeout value, thus minimizing the chance of 2 nodes starting. create a new election at the same time.
References
https://raft.github.io/raft.pdf
https://medium.com/@kasunindrasiri/understanding-raft-distributed-consensus-242ec1d2f521