I recently learned about recommendation system. And today I will share with you some of the content I learn about the Content-based Filtering method, the content-based suggestion method.
1. Overview of Suggestion System
1.1. Concept
The suggestion system (Recommender Systems – RS) is a form of information filtering system, which is used to predict preferences or ratings that users can use for an item. certain information (items) they haven’t considered in the past (items can be songs, movies, video clips, books, articles, ..).
Actually, this is not a problem too strange for us, right? As suggestions for us on Lazada, Youtube, Facebook, … or most obviously, in Viblo system, there are also suggestions for you articles that are likely to interest you.
1.2. Components of a suggested system
The suggestion system is very familiar and close, so to build a suggestion system, we need to have:
- Data: First we need to have data about users, items, feedback
Inside,
- users is a list of users
- items is the product list, the object of the system. For example, articles on viblo pages, youtube videos, etc. And each item may contain descriptive information.
- Feedback is the interaction history of the user with each item, which can be the evaluation of each user with an item, the number of ratings, or the comment, whether the user clicks, views or buys the product, …
- User-item matrix: Utility matrix
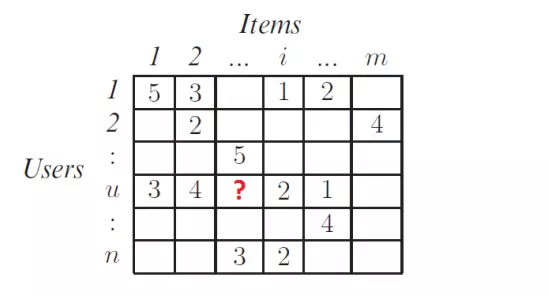
This is a matrix representing the level of interest (rating) of users with each item. This matrix is built from data (1). But this matrix has a lot of worth miss. The task of the main hint system is to rely on the cells that have values in the above matrix (data obtained in the past), through the built model, predict the empty cells (of the current user). then sort the predicted results (for example, from high to low) and choose the Top-N items in the order of descending ratings, thereby suggesting them to the user.
- Suggested method: There are 2 main suggestion methods, often used to build suggestion system, that is:
- Content-based Filtering: Suggest items based on user profiles or content / attributes (attributes) of similar items that the user has selected in the past.

- Collaborative Filtering: Suggest items based on correlations between users and / or items. It is understandable that this is a way to suggest a user based on users with similar behavior.
And in this article, we will learn about Content-based Filtering method
- Content-based Filtering: Suggest items based on user profiles or content / attributes (attributes) of similar items that the user has selected in the past.

2. Content-based suggestion method (Content-based Filtering)
2.1 Ideas
The idea of this algorithm is, from the item’s description information, to represent the item in the form of attribute vector. Then use these vectors to learn each user’s model, which is the user weight matrix for each item.
Thus, content-based algorithm consists of 2 steps:
- Step 1: Represent items in the form profile – item profile
- Step 2: Learn each user’s model
2.2. Build Items Profile
In content-based systems, we need to build a profile for each item. This profile is represented in the form of math as an n-dimensional “feature vector”. In simple cases (for example, item is textual data), the feature vector is directly extracted from the item. From there we can identify items with similar content by calculating the similarities between their feature vectors.
Some commonly used methods for building feature vectors are:
- Use TF-IDF
- Use binary representation
- Using TF-IDF: Explain a bit:
TF (t, d) = (number of times t appears in the text d) / (the total number of words in the text d)
IDF (t, D) = log_e (Total number of documents in sample D / Text number containing word t)
Example : Suppose we search for “IoT and analytics” on the Internet and find the following articles:
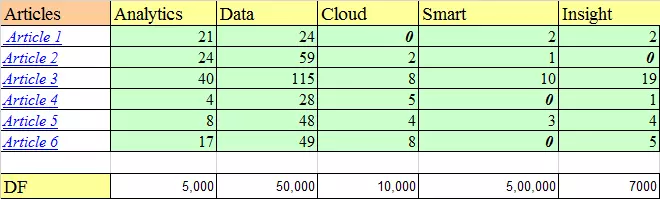 In articles, 5000 contains analytics, 50,000 contains data and the same amount for other words. Let us assume that the total number of documents is 1 million (10 ^ 6).
In articles, 5000 contains analytics, 50,000 contains data and the same amount for other words. Let us assume that the total number of documents is 1 million (10 ^ 6).
- Calculate TF: We will calculate TF for each word in each articleFor example, TF (analytics) = 1 + lg21 = 2.322

- Calculate IDF:
IDF is calculated by taking the logarithmic inverse of the document frequency in the entire corpus. So if there is a total of 1 million documents returned by our search query and among those documents, for example, if smart words appear in 0.5 million times in the document, the value Its IDF will be: Log10 (10 ^ 6/5000000) = 0.30.

- Calculate weight TF-IDF: First we use the following formula to calculate tf-df:
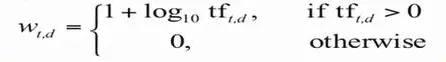
Then standardize the vector feature by dividing the vector by its own length.
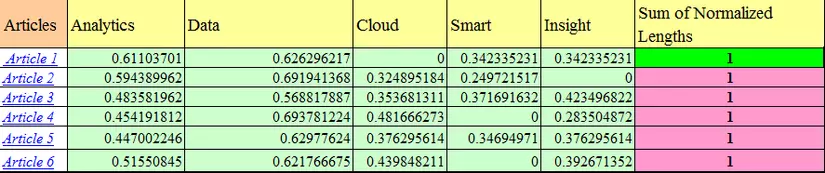
Thus, we can get the characteristic vectors for each article. We can then use cosine similarity to calculate the distance between them.
- Use binary representation: For example:
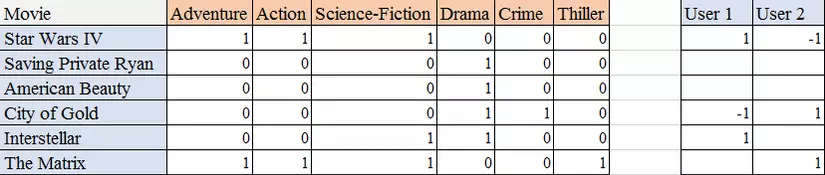
Above is a list of 6 movies. Each 0/1 value represents the movie / whether it belongs to the category in the corresponding column. Besides, a user profile is also created, with 1 being interested, -1 is not, and null is not yet evaluated. As in the example above, User 1 is interested in Star Wars IV, while User 2 does not.
2.3 Study user representation model
In this article, I will consider an example with a linear model.
Suppose we have:
- N users
- M items
- Y user-item matrix. In which, y (i, j) is the level of interest (here is the number of stars that have been rated) of user i with the jth product that the system has collected. The Y matrix has many missing elements corresponding to the values that the system needs to predict.
- R is a rated or not matrix that shows whether a user has rated an item or not. Specifically, rij = 1 if the i item is already rated by user j, otherwise rij = 0 if the i item is not already rated by user j.
Apply linear model:
Suppose that we can find a model that calculates the level of interest of each user with each item with a linear function:
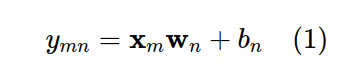
where, x (m) is the characteristic vector of item m.
Our goal will be to learn the model of the user, ie find w (n) and b (n).
Considering any n user, if we consider training set to be a set of filled elements of yn, we can build a loss function similar to the following:
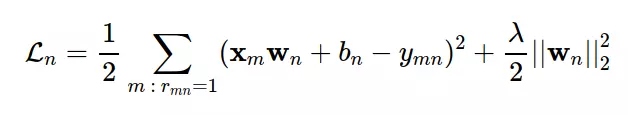
In it, the second component is regularization term and λ is a positive parameter. Note that regularization is usually not applied to users. In practice, the arithmetic mean of the commonly used error, and loss, Ln is rewritten as:
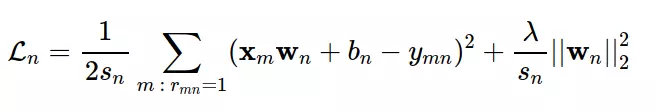
Where sn is the number of items that user n has rated. In other words, sn is the sum of the elements on the nth column of the matrix rated or not R:
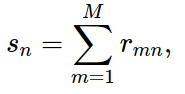
Since the target function depends only on items that have been rated, we can shorten it by setting ^ yn as the sub vector of y built by extracting the other elements? in the nth column, which has been rated by the nth user in the Y matrix. At the same time, placing X ^ n is the sub matrix of the feature X matrix, created by extracting the rows corresponding to the items that have been rated by user n. Then, the expression of the model’s loss function for the nth user is abbreviated to the formula (*) :
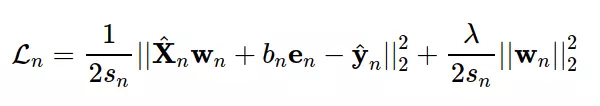
where, en is the column vector containing element 1.
This is the Ridge Regression problem, available in the sklearn.linear_model.Ridge library of klearn. In the next lesson, we will use this library to find w (n) and b (n) for each user. Now we will consider an example of how to build a model for each user.
For example:
Consider the problem: We have 5 items, the characteristic vector of each item is represented by a row:
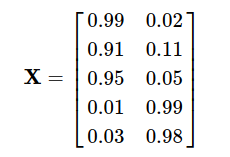
At the same time, we have information about user 5, which evaluated items 1 and 4:
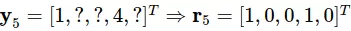
First, the preprocessor to obtain the vector sub:
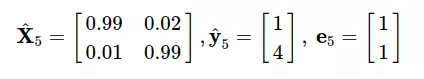
Then apply the formula (*) , we will get the loss function:
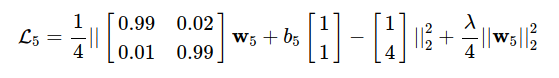
Finally, we can use Stochastic Gradient Descent (SGD), or Mini-batch GD to find w (5) and b (5).
In the next section, I will present a concrete example of how to build a content-based suggestion model. See you guys in the next post.
To find out more, you can refer to the materials and souce code in the following links:
Content-based Recommendation Systems – Vu Huu Tiep
Hướng dẫn làm việc để biết About Content Based Recommender Engines