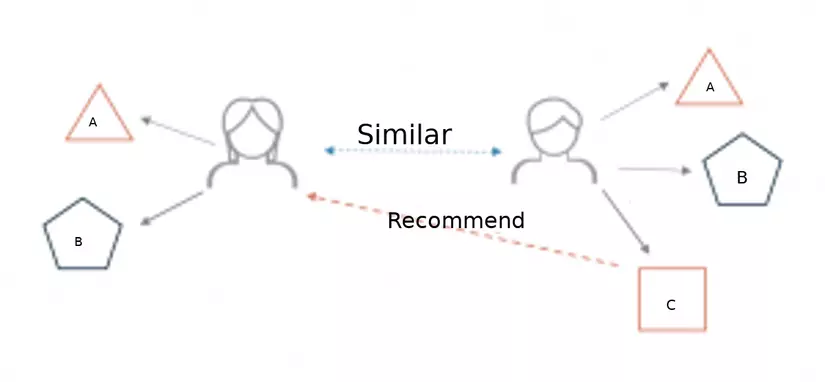
What is consulting system?
The recommender system is a type of information filtering tool that enables deduction and prediction of products, services and content that users may be interested in based on collected information. about users, about products, services, activities, interactions as well as user reviews of past products and services.
The approach
- Rule / knowledge-based approach
- Approach based on collaborative filtering (collabrative – CF)
- Content-based approach
- Approach based on a combination of CF and content-based (hybrid)
1. Collaborative filtering – CF (collaborative filtering)
- Collaborative filtering provides advice (suggestions) for products, services, content for a user based on the interests, preferences of similar users for products and services. case, that content.
- Collaborative filtering is considered to be one of the three main approaches in building advisory systems.
- There are many collaborative filtering techniques and are divided into two main types:
- Memory – based: collaborative filtering based on remembering all data.
- Model – based: Collaborative filtering based on classification and prediction models.
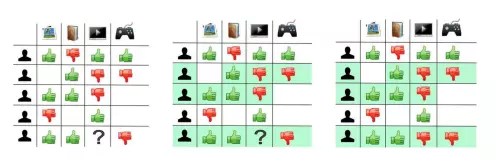
1.1 Evaluation matrix (rating matrix, user-item rating matrix)
- m user U = {u 1 , u 2 , …, u m }
- n product I = {i 1 , i 2 , …, i n }
- Evaluation matrix R = {r u, i } mxn with r u, i belong to R


- Explicit rating matrix
User reviews directly for products, services, content. The overall scale is:- Binary: Like, Dislike.
- Continuous in paragraph [0,1]
- Five discrete levels: 1, 2, 3, 4, 5 (with 5 being the best rating)
- Implicit rating matrix
The matrix is derived from information collected about user behavior such as:- Search (browsing)
- Reading
- Watch
- Sharing
- Buying
Then map user behavior into score levels.
1.2 Properties of collaborative filtering
- Data sparsity
- Evaluation matrix can be very sparse.
- Sparse data greatly affects the effectiveness of the consulting system because it is difficult to calculate the similarity between users (users) or between products (items).
- The two products may be very similar, but few review them together.
- Two users may have similar interests but have not rated the same product.
- Solution: Applying dimensionality reduction techniques
- Cold start (cold start)
- New user problem
- No product reviews
- There is no data on the behavior yet
- New product problem (new item problem)
- No user reviews yet
- No one has seen, bought, searched, …
- Solution:
- Advise popular, random products to new users; New products are appearing at the top
- Content-boosted CF: integrating new user profiles or using additional product features.
- Scalability
- When the assessment matrix is large, the number of users and products is large, the calculation time will increase, difficult to meet real-time or near real-time advice.
- Solution:
- Application of dimensional reduction techniques such as SVD, PCA.
- Item-based CF is more scalable than user-based CF.
- Synonymy problem
- Synonyms may interfere with the calculation of similarity.
- For example, children movie and children film can cause keyword-mismath, which affects the calculation of similarity.
- Solution: Apply semantic analysis techniques such as LSI (Latent Semantic Indexing), Topic Models or Deep Learning to solve this problem.
- Gray sheep and Black sheep
- Gray sheep:
- People with hobbies are not the same.
- CF is not effective in this case.
- Can combine CF and content-based
- Black sheep:
- People who have weird reviews (like, for example, use words that don’t like it) should not be able to recommend them exactly.
- Shilling attacks
- Occurs when unfair competition:
- Rate your product high, rate your product low.
- Item-based CF is less affected by shilling attacks than user-based CF.
- This phenomenon can be detected at the preprocessing step by exception detection analysis.
1.4 Memory-based CF (collaborative filtering based on memorization)
- Use the evaluation matrix to make predictions and advice.
- Suppose each user belongs to at least a group of people with similar interests and interests.
- The person who needs counseling is called an active user.
- Users with similar interests to the active user are called neighbors.
- Approach:
- User-based: based on users to predict.
- Items-based: product based for prediction.
Steps to take
- Step 1: Similarity computation – Calculate the similarity between users (w u, v ) for user-based and between products (w i, j ) for items-based.
- Step 2: Prediction – Estimate or predict the rating of active user on a product based on the information from step 1.
Suggested top-N products
- Identify the k users most similar to the active user and call them k neighbors.
- Combining from top k neighbors the most popular products to advise the active user.
Step 1: Calculate similarity (similarity computation)
- For item-based CF: Calculates the similarity w i, j between two items i and j based on users who evaluate these two items.
- For user-based CF: computational similarity w u, v between two users u, v based on the evaluation of two users on the same items.
Distance Consine
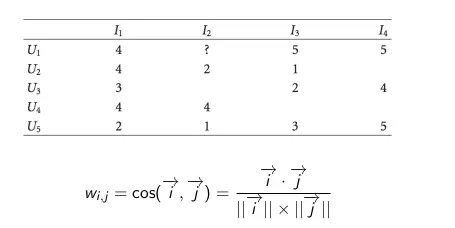
- i and j are two vectors in the rating matrix of two products i and j.
- In the above matrix: i 1 = (4,4,3,4,2) and i 2 = (?, 2,?, 4,1)
- When calculating w i, j : i 1 = (4,4,2) and i 2 = (2,4,1)
Kullback-Leiber distance
The symbols p (x) and q (x) are two probability distributions:
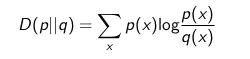
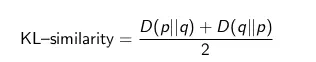
- For user-based: two distributions are two rows in R-rated matrix
- For item-based: two distributions are two columns in the evaluation matrix R
- The distributions need to be normalized before calculating D (p || q) and D (q || p).
Pearson – user-based CF correlation

- I is a set of items that both users u and v evaluate together.
- r u and r v are the average ratings of u and v on products in I.
Pearson correlation – item-based CF
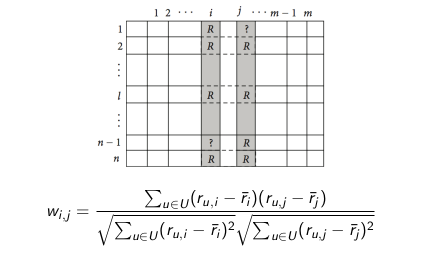
- U is the set of users who evaluate both products i and j.
- r u, i : rating u for i, same for r u, j .
- r i , r j : Average rating of users in U for i and j.
Step 2: Prediction and advice – Weight Sum of Other’s Rating
Predict the rating of active user a for a product i , with the symbol P a, i :
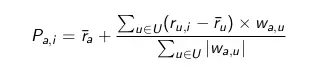
- r a and r u are the average rating of a and u on products.
- w a, u are similar levels between two users a and u.
- U is the set of all users (except a) who rated product i.

Predictions and advice – Simple Weighted Average
With product-based advice, the estimated value of a user u rating on product i, symbolized as P u, i , is calculated as follows:
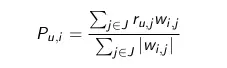
Inside:
- J is the set of all products (except i) that user u rated.
- w i, j are the degree of similarity between the two products i and j.
- r u, j is the user’s rating of product j.
Top-N recommendations
Suggest top-N products by user (user-based)
- Call a active user
- Find U a is the set of k users most similar to a.
- Use Pearson or Cosine correlation
- Call C the set of all the products that the user of the U a purchased or evaluation that a no purchase or evaluation.
- Ranking of products in C decreases with the number of users (in U a ) purchased or rated.
- Get top-N products from C in the above ranking order for advice or suggestion for a.
Suggestions of top N products by product (items-based)
- Call a active user, R is an evaluation matrix.
- Call I a set of products that you have purchased or evaluated.
- For each product i in I a , determine k products that are most similar to i.
- C is the set of all products similar to the products in I a .
- Eliminate products I a in C.
- Calculate the similarity between products in C with product set I a .
- Rank C decreases with the same level as mentioned above.
- Get the top N products from C in descending order of similarity, then advise users a.
1.5 Model-based CF collaborative filtering
- Provide advice based on machine learning models.
- Models are built based on training data.
- Methods to build collaborative filtering models often use:
- Bayesian models
- Clustering model
2. Content-based (content-based)
- Collaborative filtering methods are only based on user interaction, so content-based methods use additional information about the users and products.
Examples of movie suggestion systems: Features may include: age, gender, user job, genre, main cast, length of movie. - Then, the idea of a content-based method is to try to build a model based on additional information. For example, we build a realistic model that shows that women tend to appreciate some movies well, young men tend to appreciate other movies, etc.
- If such a model is built, it is very easy to make predictions for new users: we only need to look at the user’s profile (age, gender, etc.) and rely on this information to determine movie production.
The general architecture of the content-based consulting system
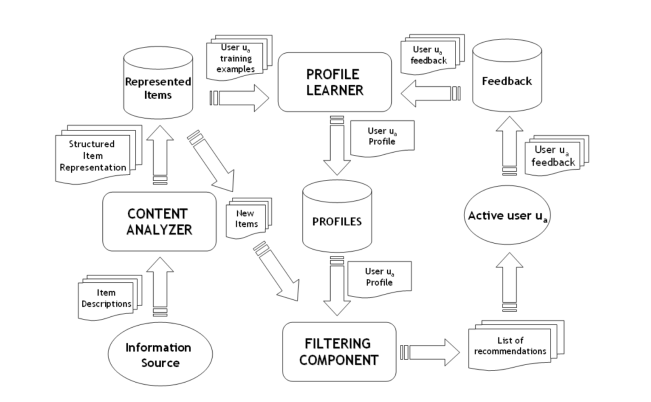
The main components
- Content Analyzer
- Analyze and extract information and content from products
- Display the extracted information according to a certain structure
- User profiles
- Database contains information, user preferences (demographics, interests, intent, …)
- Profile Learner
- Update user profiles based on their behavior
- Acts as a form of feedback from users
- Behavior such as: Reading, watching, liking, rating, sharing, buying, searching, …
- Filter Component
- Filter done advice
- Match product content with user profile.
- Rate products by level of similarity with users.
Content-based method classification
In content-based methods, the problem is included in the classification (predicting whether a user likes or dislikes an item) or the regression problem (predicting the level of evaluation that a user presents for one side). line). In both cases, we will set up a model that will be based on user or product specifications at our disposal.
- Item-centred
- If the classification (or clustering) is based on users’ features, modeling, optimization and calculation are performed on the product.
- Building and learning an item-based model on users features that try to answer the question, “What is the probability of each user liking this item?” (Or What is the per-user rating of the product?). The model built by this method is less personalized than the user-centered approach.
- User centred
- If we are working with product characteristics, modeling, optimization and calculation training can be done based on the user.
- The model is based on user based on items features that try to answer questions. “What is the probability that this user likes each item?” (Or what is this user rating for each item?).
- We can then attach a model to each user trained on their data, so the model is more personalized than the item-centric approach because it only takes into account human interactions. User is considered. However, users interact with relatively few products and therefore, the model we get will be less powerful than the product-focused model.
Item-centred Bayesian classifier
For each product we want to train a Bayesian subclass based on user characteristics that are input and output as “like” or “dislike”. So we need to calculate:
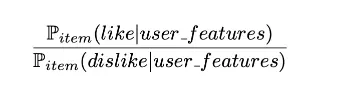
The probability that users with certain characteristics like the product over the probability that people do not like it. The Bayes formula can be calculated as follows:

User-centered linear regression
For each user, we need to train a simple linear regression model, taking the characteristics of the product as input and output as the user rating for this product. We still represent the item-user interaction matrix M, then stack into the matrix a row X vector vertex representing the coefficients the user will learn and overlay a matrix vector Y representing the Characteristics of the given product. Then, for the user i gave, we learn the coefficients in X_i by solving the following problem:
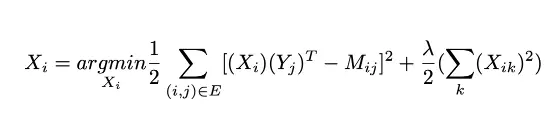
Where i is fixed, therefore, the first sum is only the pairs (user, item) related to user i. We can see that if we solve this problem for all users at once, the optimization problem is exactly the same as the “alternated matrix factorization” problem when items are fixed.
Advantages
- Ensure independence between users
- Easy to understand
- Address most cold-start issues (new users, new products)
Defect
- Must analyze and extract the product content
- May create over-specification (serendipity)
- Consulting familiar products
- It is difficult to advise on new or unusual products
- Still difficult while advising new users.
3. Hybrid approach (hybrid methods)
These methods are a combination of content-based approaches and collaborative filtering, which work well in many cases and are therefore used in many large-scale proposal systems today. The combination made in hybrid methods can mainly come in two forms:
- Train two models independently (one collaborative filtering model and one content-based model) and combining their recommendations
- Build a model directly to unify both approaches using as pre-input information (about users and / or items) as well as interactive information of online collaboration.
Reference paper from syllabus Phan Xuan Hieu – lecturer of University of Technology and article Introduction to recomment systems by Baptiste Rocca