Introduction of pre-trained models in the field of Computer Vision
- Tram Ho
1. Introduction
In recent years, Artificial Intelligence (AI) or artificial intelligence has been developing strongly in many fields. One of the areas where the greatest growth has been mentioned is Computer Vision. The birth of Convolution Neural Network along with the strong development of Deep Learning has helped Computer Vision achieve remarkable breakthroughs in problems: image classification, object detection, video tracking, image. restoration, etc. In this article I will introduce you to the famous CNN pre-trained model. This article is for those who have good theory about Deep Learning in general and Convolution Neural Network in particular. In the demo I will use Python and the Keras library.
2. Pre-trained CNN model in Keras VGG-16
First of all, the VGG network. VGG was launched in 2015 and introduced at ICLR 2015. The architecture of this model has many different variants: 11 layers, 13 layers, 16 layers, and 19 layers, you can see the details in the picture. after: 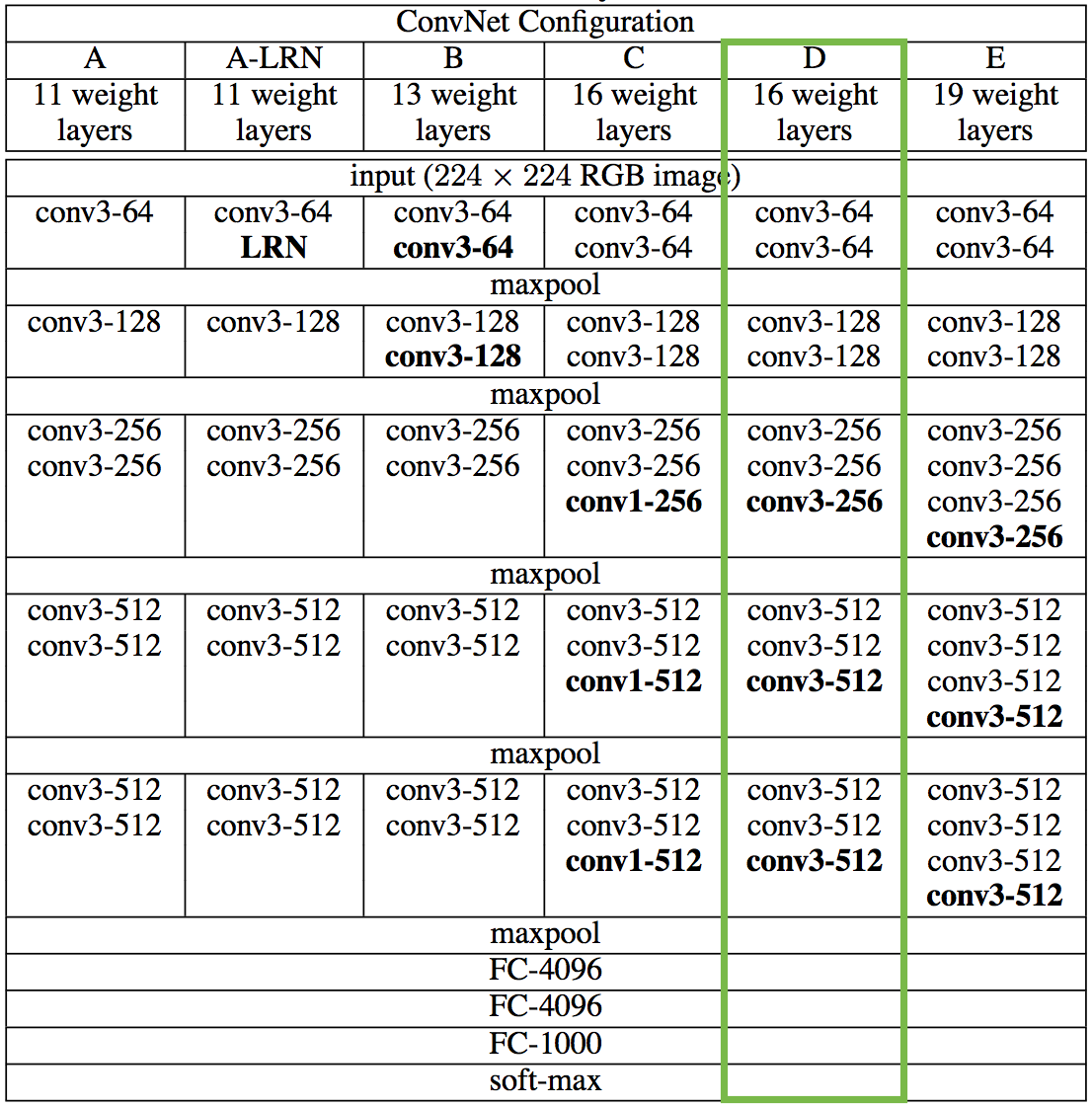 In this article I will mention VGG-16 – the network architecture has 16 layers. The design principles of VGG networks are generally very simple: 2 or 3 layers Convolution (Conv) and followed by a Max Pooling 2D layer. Immediately after the last Conv is a Flatten layer to convert the 4-dimensional matrix of the Conv layer to a 2-dimensional matrix. Following are the Fully-connected layers and 1 Softmax layer. Because VGG is trained on the ImageNet data set of 1000 classes, the final Fully-connected layer will have 1000 units.
In this article I will mention VGG-16 – the network architecture has 16 layers. The design principles of VGG networks are generally very simple: 2 or 3 layers Convolution (Conv) and followed by a Max Pooling 2D layer. Immediately after the last Conv is a Flatten layer to convert the 4-dimensional matrix of the Conv layer to a 2-dimensional matrix. Following are the Fully-connected layers and 1 Softmax layer. Because VGG is trained on the ImageNet data set of 1000 classes, the final Fully-connected layer will have 1000 units.
In Keras currently supports 2 pre-trained models of VGG: VGG-16 and VGG 19. There are 2 main parameters you should note that include_top (True / False): whether to use Fully-connected layers or not and weights (‘imagenet’ / None): whether to use pre-trained weights of ImageNet .
1 2 3 4 5 6 7 8 9 10 | <span class="token comment"># VGG 16</span> <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> vgg16 <span class="token keyword">import</span> VGG16 <span class="token comment"># Sử dụng pre-trained weight từ ImageNet và không sử dụng các Fully-connected layer ở cuối</span> pretrained_model <span class="token operator">=</span> VGG16 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token string">'imagenet'</span> <span class="token punctuation">)</span> <span class="token comment"># VGG 19</span> <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> vgg19 <span class="token keyword">import</span> VGG19 <span class="token comment"># Không sử dụng pre-trained weight từ ImageNet và không sử dụng các Fully-connected layer ở cuối</span> pretrained_model <span class="token operator">=</span> VGG19 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token punctuation">)</span> |
InceptionNet
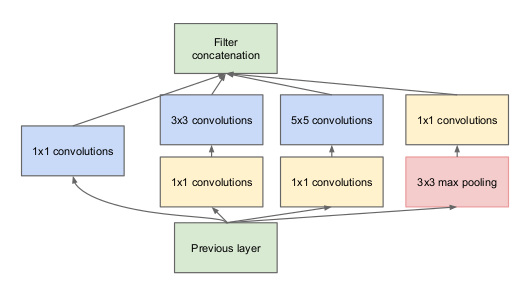
With conventional CNN networks, it is imperative to specify parameters of a Conv layer before design: kernel_size, padding, strides, etc. And often it’s hard to tell which parameter is suitable, kernel_size = (1, 1) or (3, 3) or (5, 5) would be better. The Inception network was born to solve that problem, the most important element in the Inception network is the Inception module , a complete Inception network consisting of many small Inception modules put together. You can see the illustration below to better understand. The idea of Inception module is very simple, instead of using 1 Conv layer with fixed kernel_size parameter, it is possible to use multiple Conv layers at the same time with different kernel_size parameters (1, 3, 5, 7 , etc) and then concatenate the outputs together. To avoid the dimensional error when concatenate, all Conv layers have the same strides = (1, 1) and padding = ‘same’. At present, there are 3 versions of Inception network, the following versions usually have some improvements compared to the previous version to improve accuracy. Keras currently supports pre-trained model Inception version 3.
1 2 3 4 5 | <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> inception_v3 <span class="token keyword">import</span> InceptionV3 <span class="token comment"># các tham số include_top và weights các bạn có thể tùy chỉnh</span> <span class="token comment"># theo ý muốn để phù hợp với bài toán của riêng mình.</span> pretrained_model <span class="token operator">=</span> InceptionV3 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token string">'imagenet'</span> <span class="token punctuation">)</span> |
ResNet
The next CNN model I would recommend to you is ResNet or Residual Network. When training Deep CNN models (large number of layers, large number of params, etc.) we often encounter problems with vanishing gradients or exploding gradients. In fact, when the number of layers in the CNN model increases, the accuracy of the model also increases, but when the number of layers is too large (> 50 layers), the accuracy is reduced. 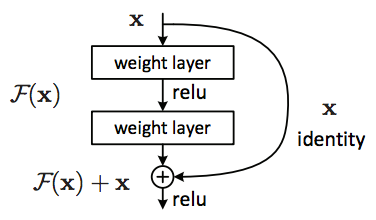
The Residual block was born to solve the above problem, with the Residual block, it is possible to train CNN models with bigger size and complexity without worrying about exploding / vanishing gradients. The key of the Residual block is that after every 2 layers, we add input to the output: F (x) + x. Resnet is a CNN network composed of many small Residual blocks formed. Currently in Keras there is a pre-trained model of ResNet50 with weight trained on ImageNet with 1000 clas.
1 2 3 | <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> resnet50 <span class="token keyword">import</span> ResNet50 pretrained_model <span class="token operator">=</span> ResNet50 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token string">'imagenet'</span> <span class="token punctuation">)</span> |
InceptionResNet
Hearing the model name, you will probably guess the configuration of the network. InceptionResNet is a model built on the advantages of Inception and Residual block. With this combination, InceptionResNet achieves amazing accuracy. On the ImageNet data set, InceptionResNet reached 80.3% of the top 1 accuray while this figure of Inception V3 and ResNet50 were 77.9% and 74.9%, respectively. To use pre-trained InceptionResNet in Keras we do the same as other pre-trained models.
1 2 3 | <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> inception_resnet_v2 <span class="token keyword">import</span> InceptionResNetV2 pretrained_model <span class="token operator">=</span> InceptionResNetV2 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token string">'imgaenet'</span> <span class="token punctuation">)</span> |
MobileNet
The newly introduced CNN models, while having a high level of accuracy, all have a common weakness that is not suitable for mobile applications or embedded systems with low computing power. If you want to deploy the models above for real-time applications, you need to have extremely powerful configuration (GPU / TPU) and also for embedded systems (Raspberry Pi, Nano pc, etc) or applications running On smart phones, we need a “lighter” model. Below benchmarking the models on the same ImageNet data set, we can see that MobileNetV2 has an accuracy that is not inferior to other models such as VGG16, VGG19 while the number of parameters is only 3.5M (about 1/40 of the parameter number of VGG16). 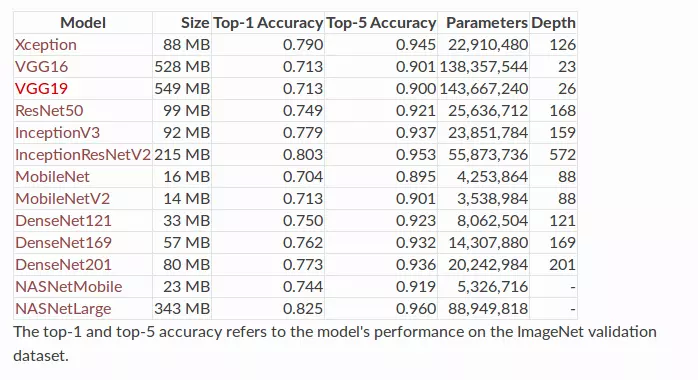
The main factor that helps MobileNet to have high accuracy while the low calculation time lies in the normal Conv layer improvement. In MobileNet, there are 2 Covn layers used: SeparableConv and DepthwiseConv. Instead of performing the convolution operation as usual, SeparableConv will conduct the depthwise spatial convolution operation (I don’t know how to translate ntn as well) followed by the pointwise convolution operation (I don’t know how to translate ? as well). And DepthwiseConv will only perform the depthwise spatial convolution operation (excluding pointwise convolution). Such convolution division greatly reduces the computational mass and the number of network parameters. With this change, MobileNet can work smoothly even on low-profile hardware. And still like the previous pre-trained ccas, Keras also has dental support for you:
1 2 3 | <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> mobilenet_v2 <span class="token keyword">import</span> MobileNetV2 pretrained_model <span class="token operator">=</span> MobileNetV2 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token string">'imagenet'</span> <span class="token punctuation">)</span> |
3. Build your own CNN model with a pre-trained model
In the previous section I introduced you to the famous pre-trained models, but maybe you are still quite confused about how to use these pre-trained models in your own practical problems. So, in this section, I will have a small demo so that everyone can have a more specific view on transfer learning.
Assuming the problem is image classificatoin, recognize alphabetic characters from az, AZ, and numbers 0-9 (62 labels in total). The input image is 96x96x3 (rgb image). My pre-trained user is MobileNetV2.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | <span class="token comment"># import các module cần thiết</span> <span class="token keyword">from</span> keras <span class="token punctuation">.</span> applications <span class="token punctuation">.</span> mobilenet_v2 <span class="token keyword">import</span> MobileNetV2 <span class="token keyword">from</span> keras <span class="token punctuation">.</span> layers <span class="token keyword">import</span> Input <span class="token punctuation">,</span> BatchNormalization <span class="token keyword">from</span> keras <span class="token punctuation">.</span> layers <span class="token keyword">import</span> GlobalAveragePooling2D <span class="token keyword">from</span> keras <span class="token punctuation">.</span> layers <span class="token keyword">import</span> Activation <span class="token keyword">from</span> keras <span class="token punctuation">.</span> models <span class="token keyword">import</span> Model <span class="token comment"># 62 class: a-z, A-Z, 0-9</span> NUMBER_CLASSES <span class="token operator">=</span> <span class="token number">62</span> <span class="token comment"># build model</span> <span class="token keyword">def</span> <span class="token function">create_model</span> <span class="token punctuation">(</span> input_shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">96</span> <span class="token punctuation">,</span> <span class="token number">96</span> <span class="token punctuation">,</span> <span class="token number">3</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token comment"># khai bao input layer</span> input_layer <span class="token operator">=</span> Input <span class="token punctuation">(</span> shape <span class="token operator">=</span> input_shape <span class="token punctuation">,</span> name <span class="token operator">=</span> <span class="token string">'input'</span> <span class="token punctuation">)</span> <span class="token comment"># su dung pre-trained model</span> pretrained_model <span class="token operator">=</span> MobileNetV2 <span class="token punctuation">(</span> include_top <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> weights <span class="token operator">=</span> <span class="token string">'imagenet'</span> <span class="token punctuation">)</span> pretrained_model_output <span class="token operator">=</span> pretrained_model <span class="token punctuation">(</span> input_layer <span class="token punctuation">)</span> global_avg <span class="token operator">=</span> GlobalAveragePooling2D <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> pretrained_model_output <span class="token punctuation">)</span> <span class="token comment"># fully-connected layer 1</span> dense <span class="token operator">=</span> Dense <span class="token punctuation">(</span> units <span class="token operator">=</span> <span class="token number">512</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> global_avg <span class="token punctuation">)</span> dense <span class="token operator">=</span> BatchNormalization <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> dense <span class="token punctuation">)</span> dense <span class="token operator">=</span> ReLU <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> dense <span class="token punctuation">)</span> output <span class="token operator">=</span> Dense <span class="token punctuation">(</span> units <span class="token operator">=</span> NUMBER_CLASSES <span class="token punctuation">)</span> <span class="token punctuation">(</span> dense <span class="token punctuation">)</span> output <span class="token operator">=</span> Activation <span class="token punctuation">(</span> <span class="token string">'softmax'</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> output <span class="token punctuation">)</span> model <span class="token operator">=</span> Model <span class="token punctuation">(</span> input_layer <span class="token punctuation">,</span> output <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> model <span class="token punctuation">.</span> summary <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> model model <span class="token operator">=</span> create_model <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
The model we just defined has the following architecture:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | Layer (type) Output Shape Param # ================================================================= input (InputLayer) (None, 96, 96, 3) 0 _________________________________________________________________ mobilenetv2_1.00_224 (Model) multiple 2257984 _________________________________________________________________ global_average_pooling2d_1 ( (None, 1280) 0 _________________________________________________________________ dense_1 (Dense) (None, 512) 655872 _________________________________________________________________ batch_normalization_1 (Batch (None, 512) 2048 _________________________________________________________________ re_lu_1 (ReLU) (None, 512) 0 _________________________________________________________________ dense_2 (Dense) (None, 62) 31806 _________________________________________________________________ activation_1 (Activation) (None, 62) 0 ================================================================= Total params: 2,947,710 Trainable params: 2,912,574 Non-trainable params: 35,136 |
So you have a CNN model with pre-trained MobileNetV2. Just compile and fit the data to training is done, so easy.
1 2 3 | model.compile(...) modle.fit(...) |
4. Conclusions
So lfa in this article I have introduced you to some of the famous pre-trained models in the field of Computer Vision. When building a CNN model for a problem, you can completely use transfer learning instead of building a model from scratch. To be able to better understand the ideas as well as the design principles of the above models, you can completely go to google scholar to search and read more to understand more deeply. Hopefully this article can help you build a CNN model faster, save training time than how to build a model from scratch. See you in the following articles.
Source : Viblo