Foreword
Hello friends! Today, I would like to share some questions when participating in the technical interview of a Ruby Dev that I have met. This article helps me to check the background knowledge and hope that you are going to interview. Can refer to more confidence. The answers in this article are due to my research during the time of preparing Div’s interview, you should google more to have the best and most accurate answer when participating in the interview.
Let’s start!
In an interview on Ruby on Rails, I found the questions can be divided into the following knowledge areas:
- OOP knowledge, algorithms
- Knowledge of databases and SQL
- Understanding Ruby
- Understanding Rails
- Related insights like REST, Javascript
1. OOP knowledge, algorithms
1 2 | Cấu trúc dữ liệu |
- Stack, Queue
- Link-list, Hash
- Graph, Binary Tree, …
1 2 | Các thuật toán sắp xếp (Sort) |
- The selection sort finds the smallest element to the top, finds the smallest among the rest to the end
- bubble sort (swapping 2 elements -> simplest)
- The insertion sort compares two pairs of numbers close together, a <b giving a first. Next compare b and c, …
- merge sort division to divide and divide the array into the smallest (1 element) -> combine the elements by comparing them -> combine into sorted array
- quick sort select latch element -> divide into 2 bigger and smaller elements latch table comparison method -> recursively sort those 2 parts -> result
1 2 | Độ phức tạp của các thuật toán sắp xếp (Sort) |
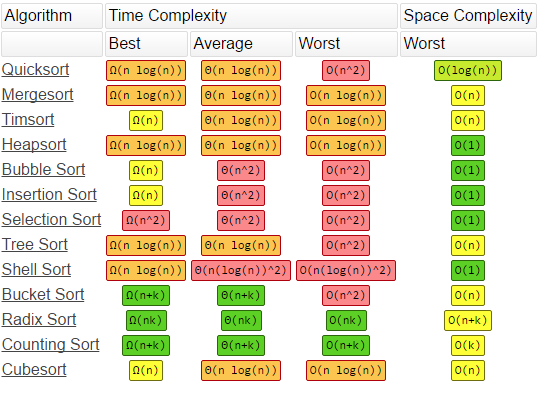
1 2 | Các thuật toán tìm kiếm (Search) |
No experience
- Linear search (browse from beginning to end)
- Search binary
- DFS Search by depth
- BFS Search by width
Empiric
- Best-first search = BFS + experience function
- Hill-climbing search = DFS + experience function
- Search A *
1 2 | Lập trình hướng đối tượng là gì ? Nêu 4 tính chất của hướng đối tượng, cho ví dụ? |
Object-oriented is a programming method in which all operations are performed on Objects.
Calculated packing
Ie the state of the object is protected from access from external code such as changes in state or direct view. It is up to the coder to allow the external environment to influence the internal data of an object.
This is the nature of ensuring the integrity and security of objects. In Java, encapsulation is expressed through access modifier.
3 keywords private, protected, public
Abstraction
Abstraction is a process of hiding deployment details and showing the feature only to users.
Abstraction allows you to eliminate the complexity of an object by only exposing the properties and methods needed of the object in programming.
Abstraction helps you focus on the essentials of the object rather than being interested in how it works.
In Java, they are using abstract classes and abstract interfaces to be abstract.
Inheritance
This object has properties common to other objects -> A inherits BA that has public and protected properties and methods of B and A’s own
Polymorphism
Objects of different classes can understand the same message in different ways.
For example: In Shape there are many different drawings such as Circle, … Calculate their area differently, run the same calArea () method. In each subclass override the calArea () method in a different way.
Type up and down type (downcasting and upcasting)
1 2 | 3 cơ chế của OOP. Phân biệt, ví dụ |
- Public: The instance and child it can access
- Protected: Only his son can access
- Private: Not for anyone to access Of course, only inheriting and outside the class, children in the class then access all: v
1 2 | Hàm dựng, hàm hủy nó hoạt động như thế nào? |
Initialization function
The constructor is also a normal function, but it has a special feature that is always called when we initialize an object. The constructor may have arguments with or without parameters, and may have return values or not. In another normal function you can also call the constructor and the constructor can call another normal function.
Destroy function
The destructor is a function that automatically calls after the object is destroyed, which is often used to free program memory. In object cancellation function may or may not.
1 2 | Phân biệt class và object |
Class is a template for creating Object object, which is a named instance of the class
1 2 | Interface và Abstract class khác nhau như thế nào? |
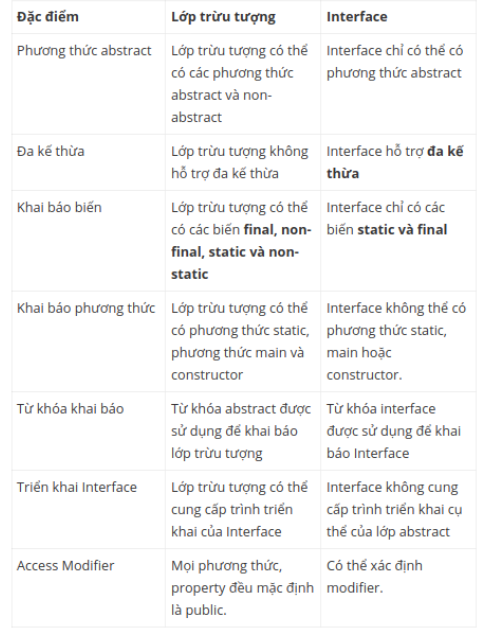
2. Knowledge of databases and SQL
1 2 | Viết một số câu SQL theo yêu cầu |
1 2 | Cách xây dựng cơ sở dữ liệu cho bài toán cụ thể |
1 2 | Phân biệt các loại join |
- INNER JOIN – returns the row when there is a match in all joined tables.
- LEFT JOIN returns all the left table records, even if there is no match in the right table, and which of the right table records match the left table, that record data is used to combine with the left table record, otherwise there will be NULL data.
- RIGHT JOIN – returns all the rows from the right table, even if there is no match in the left table.
- FULL JOIN – returns the row when there is a match in one of the tables.
- SELF JOIN – used to join a table to itself as if it were two tables, temporarily renaming at least one table in the SQL statement.
If you want to read to understand better, you can read through the series of articles about join sql:
https://www.w3schools.com/sql/sql_join.asp
https://hainh2k3.com/phan-biet-va-cach-su-dung-cac-loai-join-trong-mssql-server/
1 2 | Phân biệt delete và truncate |
| TRUNCATE | DELETE |
|---|---|
| Clear data but not structure | Clear data but not structure |
| Delete all data rows in the table | Delete the data rows in the table |
| Cannot use WHERE | Use WHERE |
| DO NOT record the delete lines in the transaction log | YES records the delete lines in the transaction log |
1 2 | Phân biệt WHERE và HAVING |
Where: Conditional statement that returns results compared to each row.
Having: A conditional statement returns a collation result to a group (Sum, AVG, COUNT, …)
So after GROUP BY, it will only be Having, while Where can NOT be used after GROUP BY
1 2 | Phân biệt UNION và UNION ALL |
UNION and UNION ALL are both used to combine two sets of records of the same structure, but there is a subtle difference between the two clauses:
UNION removes duplicate records before returning results
UNION ALL retains all records from the original two volumes.
It is important to note that the performance of UNION ALL is usually better than UNION, because UNION requires the server to perform additional work to remove duplicate records.
1 2 | Các loại index trong sql |
Index is a special data structure in the form of lookup tables that Database Search Engine can use to help query data in the database more effectively.
Put simply, an index is a pointer to data in a table, like a table of contents in a book to look up book pages.
How many index types are there in MySQL?
There are two main types of indexes in MySQL, Clustered Index and Non-clustered Index
Expanding from 2 categories on the Unique Index Primary Index Secondary Index
If you want to read to understand better, you can read the following articles:
http://dinhhoanglong91.github.io/post/2017/03/02/mysql-indexing.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
1 2 | Các đánh index trong sql |
MySQL provides the following types of indexing: B-Tree, Hash, R-Tree and bitmap index
B-Tree index
- The index data is organized and stored in a tree format, ie with roots, branches and leaves. The value of organized nodes increases from left to right.
- When querying data, searching in B-Tree is a recursive process, starting from the root node and searching to branches and leaves, until all the data that is satisfied with the query condition is found. reuse.
- B-Tree index is used in comparison expressions of the form: =,>,> =, <, <=, BETWEEN and LIKE. B-Tree indexes are often used for columns in tables when looking for values within a range.
Hash index
- Index data is organized in the form of key – value linked together.
- When the hash index works, it will automatically generate a hash value of the column and then build B-Tree according to that hash value. This value can overlap, and then the B-Tree node will store a linked list of pointers to the table row.
- The hash index used only in the = and <> operator expressions, without an approximate search, searching within a range or sort, cannot optimize the ORDER BY operator using Hash index because it cannot find the next part of the Order.
R-Tree index
MyISAM supports spatial indexes, which you can use with partial types like GEOMETRY. Unlike B-Tree indexes, spatial indexes do not require your WHERE clauses to operate on the leftmost prefix of the index.
1 2 | Lợi, hại của việc đánh index |
Although the use of indexes is intended to improve Database performance, sometimes you should avoid using them. A general rule of thumb is to create indexes for everything referenced in the WHERE, HAVING and ORDER BY sections of SQL queries.
- Index for finding unique values
- Index for foreign keys to optimize search
- Indexes for sorted values occur frequently
The following points should be considered to decide whether an index should be used:
- Indexes should not be used in small tables.
- Table that frequently has update and insert operations.
- Indexes should not be used on columns that contain large amounts of NULL values.
- Indexes should not be used on columns that are frequently modified.