In the process of building applications and using database management systems such as MySQL, SQL Server … then we can not help but pay attention to the performance, query to increase application quality. We already have the techniques, the notes in the very language we use to write our applications; we also need to increase the query response level for the database management system we are using. There have been articles outlining the ways we need to speed up queries but detailed articles on how to use them are limited. Today, I will introduce to you a technique in SQL, which is Index. Index helps speed up searching for a record according to the specific mechanism that SQL has provided and we just need to use it properly and the speed will be significantly increased.
What is INDEX?
 Understand simply, Index is the table of SQL. Let’s take a look at the concept section.
Understand simply, Index is the table of SQL. Let’s take a look at the concept section.
Index (INDEX) in SQL is a special lookup table that database search engines can use to quickly increase data access time and performance.
Put simply, an index is a pointer to each value that appears in the indexed table / column. The index in the Database has the same meaning as the entries in the Table of Contents of a book.
INDEX speeds up SELECT queries that contain WHERE or ORDER clauses, but it slows down data input with UPDATE and INSERT statements. Indexes can be created or deleted without affecting the data.
So, Index is good for search. Because our data has been organized so we can search faster. So what types of index do we have?
Types of INDEX
Now that we understand the concept of Index, what kind of index will there be in SQL?
Clustered Index
Clustered Index is a type of index that organizes the rows of data in a table on their main values. In the database, there is only one Clustered Index per table.
A Clustered Index determines the order in which data is stored in tables that can be sorted in a way. Therefore, there may be only one Clustered Index for each table. Usually, in RDBMS, the primary key allows you to create a Clustered Index based on that particular column.
Clustered Index will be unique in every table, it will be created automatically when the table is created if PRIMARY is available, if there is no PRIMARY table, then UNIQUE will be used to define it.
Non-Clustered Index
A Non-Clustered Index stores data at one location and indexes at another location. Index contains the pointer to the location of that data. A single table can have multiple Non-Clustered Index because an index in Non-Clustered Index is stored in different places.
For example, one book may have more than one table of contents, one at the beginning displaying the contents of a book unit wisely while the second table of contents shows the table of contents in alphabetical order. .
A Non-Clustered Index is defined in an unordered table field. This type of indexing method helps you improve the performance of queries that use keys that are not assigned as primary keys. A Non-Clustered Index allows you to add a unique key to a table.
Non-Clustered Index is the type of index we will define ourselves.
How is INDEX saved?
Usually when we mention Index, we will think of the B-TREE algorithm, of course there will be other algorithms, but most of the numbers will use this algorithm to sort data. And here I will show only this algorithm 
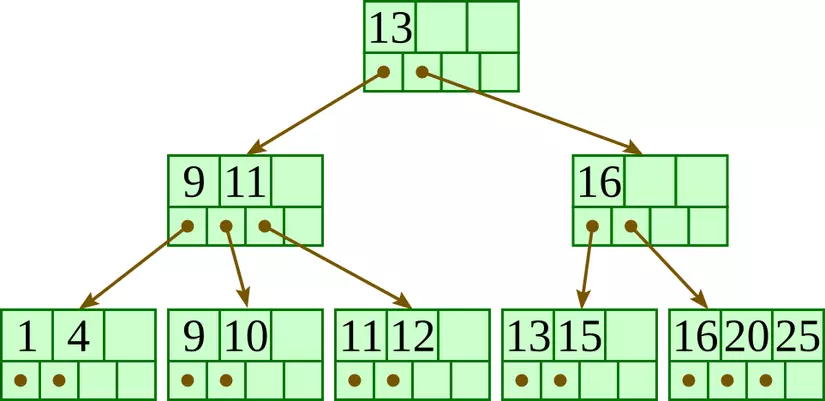 It’s too easy to understand, assuming the data we need to search is number 14, we just need to search the right part, because the data has been reorganized to organize it. So it will return results faster instead of browsing each record for comparison. Tasty.
It’s too easy to understand, assuming the data we need to search is number 14, we just need to search the right part, because the data has been reorganized to organize it. So it will return results faster instead of browsing each record for comparison. Tasty.
We have a rough idea of Index, what types it has, data organization algorithms. Here, we will go into a little deeper to understand more.
Create INDEX in MySQL
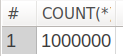
I created a table of 1 million records 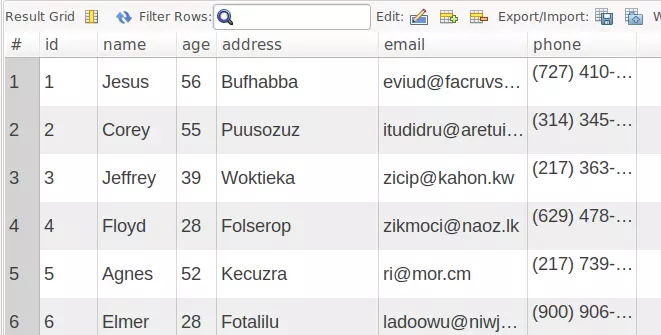 See how many records it has
See how many records it has
1 2 | SELECT COUNT(*) FROM vip_demo.user_information; |
 Here we will refer to that Non-Clustered Index that people.
Here we will refer to that Non-Clustered Index that people.
We will try to search for the name ‘Corey’ in the database
1 2 | SELECT * FROM vip_demo.user_information WHERE name like 'Corey'; |
It will take quite a bit of time (0.071 s, last row) to query the data (see image below): 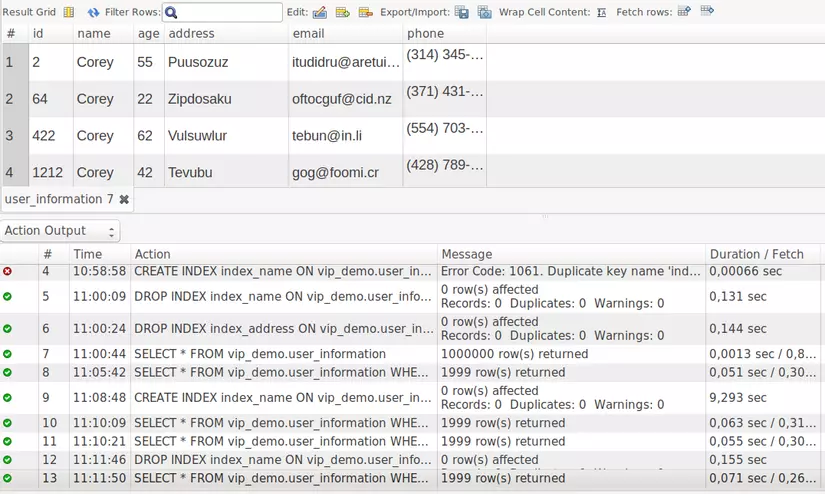 I will proceed to type index for the name column to see its effect offline
I will proceed to type index for the name column to see its effect offline
1 2 | CREATE INDEX index_name ON vip_demo.user_information (name); |
Indexing time will be a bit long, so when creating or updating data should not be used because it will take more time to fight Index -> longer than usual. After I finished querying the above question, here is the result:  Unexpected yet Faster than that people.
Unexpected yet Faster than that people.
When I don’t want to use INDEX anymore, I delete it
1 2 | DROP INDEX index_name ON vip_demo.user_information; |
EXPLAIN statement
There is an article about this query test statement, I have to link that people to read to check the status of the query.
Notes, tips using INDEX
There are no standards for me to write down what I think are tips here. It is only due to the process of researching and researching that I have drawn the following.
Isolating column (Isolating column)
The indexed column is not in an operator expression or in a function at query time.
For example:
select * from vip_demo.user_information where a = 5;
select * from vip_demo.user_information where a +1 = 5;
This way, the Index will not be able to understand the need to find a = 4, so it will use SQL to search as usual.
Prefix indexes and Index selectivity
Instead of indexing a column with very long characters, we use the Prefix Index with the first few characters to save storage space.
create index index_name on user_information (name (3)); We have used the first 3 character values of the name column to type the index.
Cons: When there is too much data with a fast prefix, this way will be counterproductive, assuming in 1M records that save name is Hoang1 -> Hoang1000000 then typing 5 characters or less has no meaning .. .
Multicolumn Indexes
The multi column index will index from the left most column of the declared columns.
Creating an index of two or more columns is a bit more optimal than a single index in thoroughly processing queries. I created the index for both the name and age columns named index_name_age
create index index_name_age on user_information (name, age);
The data will be organized by priority organization from name to age, so when assuming that your ORDER BY name is fast, if ORDER BY age will not use the data of the index to sort. It only works when searching for name and age./
Choosing a good column order
Select the data fields that require searching or sorting for indexing.
Instead of retrieving from index and searching in DB, we just need to retrieve data stored from that index itself.
That is, we do not type the index, but only the necessary fields, because if there are too many indexes, the SQL must have time to choose between the indexes (not counting), the main problem is (find) Search or insert update data) …
Covering Indexes
An index type that contains all the data needed to return a query.
Filter the required data by condition (WHERE). Instead of reading the index and mapping with the storage-engine, we only need to get the necessary data in the cover index for the query.
select name, address from user_information where name like ‘calvin’;
select name, address from user_information where name like ‘calvin’ and address like ‘xnxx’;
Search by name and address, there is a lack of address data in the index, then only use the name and then use SQL to search for adress. Conduct indexing for 2 guys.
create index index_name_address on user_information (name, address);
select name, address from user_information where name like ‘calvin’ and address like ‘xnxx’;
Now it’s delicious Well, I want to say this lest miss, that is, if we just need to search like this, we will type each index_name and index_address or index_name_adress the same.
Using Index Scan for Sorts
MySQL supports 2 ways to sort results in order:
- It can use a sorting operation (Using filesort).
- Scan the index in the order in which it is created (Using index).
select * from user_information where name like ‘c%’ order by name;
select * from user_information where name like ‘c%’ order by address;
Assuming there is only an index for the name column that adress does not have, then the ORDER BY name will use the Using index to sort, whereas the address will use the Using filesort (which should be avoided while querying data). We can both test in the above EXPLAIN statement that introduced.
Unused Indexes
create index index_name on user_information (name);
create index index_name_address on user_information (name, address);
Type index_name, index_name_address to essentially the same if querying each name.
This is when we index the columns but don’t use them. So we can remove them to ensure query speed
explain select name from user_information where name = ‘calvin’;
EXPLAIN statement to check the Index that is used for both queries above for details.
Index merge
When the expected query result exists in two separate indexes, the optimizer will use the merge of these two indexes to use.
create index index_name on user_information (name);
create index index_address on user_information (address);
explain select name, address from user_information where name = ‘calvin’ or address like ‘a%’;
This time, the SQL will automatically merge these 2 indexes together to use, so please combine smoothly to use.
total
All methods of index application are closely related. Most work with the B-tree algorithm. The tips are actually complementary to the problem, not the individual ways to use it …
Conclusion
Above is my research and refinement about Index, readers find out what is unreasonable, the feedback for us to build a better quality article for you to read later.
Thank you all. /