Do you know what is common in the implementation of Bitcoin, Git, IPFS, Ethereum, BitTorrent, and Cassandra technologies?
Perhaps the title that has suggested for you is the “Merkle tree”, a technique for storing data that is useful in systems with decentralized architecture. But what and how does the Merkle tree solve problems? I will explain that in this article!

I. Authentication in distributed networks
Distributed architecture (peer-to-peer) from birth is increasingly used widely, but it also encountered a lot of problems and one of them is how to “Authenticate” effectively. A trusted system needs to be authenticated to ensure that the participants are not
- Do data changes accidentally or
- Intentionally altering data
One of the common ways to prevent this problem is to use cryptographic hash functions. So find out how they are used.
Is cryptographic hash function the solution?
Hash entire data
If we want to store a large data file in a scattered manner, the hash function can help us calculate the hash code of the entire file (before distributed storage) and save it to a server (highly reliable) to determine carried as needed.  All “File 1” (divided into 4 parts W, X, Y, Z) are hashed and the results stored in 1 server
All “File 1” (divided into 4 parts W, X, Y, Z) are hashed and the results stored in 1 server
After being hashed, we distributed the file across multiple peers in the network. Whenever a peer needs the content of an entire file, they must download it from the peer who is hosting the file’s components. This peer will need to calculate the hash code of the entire file (after having all the components) and verify it by comparing it with the server hash code.
* P / s: If you think 2 files can have the same hash code, that’s absolutely right. But in practice, 256-bit hash codes are often used and can give up to 2 ^ 256 results. So duplication is almost impossible!
This approach works, but it has not worked because:
- Authentication can only be done after collecting all the files : If the data is distributed over thousands of peers, there will be a problem with some parts being sent soon, and some coming later. It is a waste of time just waiting for the whole thing to arrive.
- It is not possible to identify any components that are biased (due to checks only when all the components have been combined).
- Synchronization is too high : Only 1 character changes will also lead to recalculating the entire hash code of the file and store at the server.
- Server hosting hash codes is a weakness in this decentralized network.
Hash partial data
Storing the part hash code on the server can be a solution to the “1” and “2” problems by partially and partly validating the “3” problem because it may only update the data instead. change. However, there are still disadvantages:
- The server stores a small amount of information.
- Increase the possibility of duplicate hash code.
- The whole network still needs to rely on one server. What if this server is not trusted?
Hash string
So if we do this then? We include the hash codes of each component and then hash out, the result (called root hash) is stored at the server. Root hash will have an authentication role. So this will be:
- Initially, the peer collects pieces of data.
- After that, we will hash each part and combine the hash codes, continue to calculate the root hash. This root hash will be compared to the one on the server.
- And when, and if our root hash exists on the server, we can save it for future authentication without having to rely on the server.
It looks like everything is fine except what if the server is not trustworthy and returns a false root hash.
There is actually a way that the server can prove it’s trusted. Continue reading ….
Store more information on the server
So what if we store both partial and root hashes on the server? Of course storage costs will increase a bit, but it is possible to solve the “4” problem as follows:
- Instead of replying whether the root hash exists or not, the server will have to send all the hash codes to calculate the root hash.
- With the hash code sent, along with the hash of the data to be authenticated, the client can calculate the root hash itself and compare it with the sent root hash.
We are about to reach the whole solution on Merkle trees!
II. So, what are Merkle Trees?
Architecture
Go to the solution, if the storage model like this is effective? 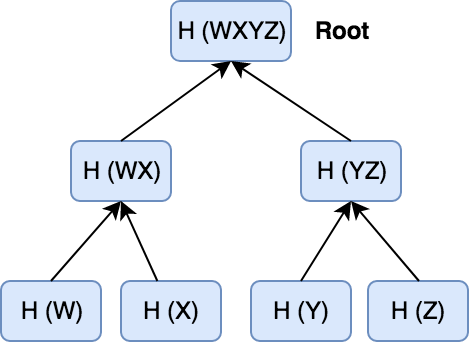
Leaf nodes in the tree correspond to the hash code of each piece of data, and the two hash codes combine and continue to hash will generate hash code at the parent node. This is the architecture of Merkle trees.
Why is this model effective?
You may be wondering how this model is better than the previous models and what benefits it has. It is really effective in storing and calculating the following:
Data validation
The data will be verified in Merkle Trees as follows:
- As before, we download the data to the node.
- We send the required max hashes to the server.
- The server returns the result.
- With the existing hash code, we can calculate the root hash and compare it with the one on the server.
For example, if a node needs to validate data Y, when we send a request, the server returns H (Z) and H (WX), called an audit trail or merkle path.

We can calculate:
- H (YZ) is calculated from H (Y) together with H (Z) sent by the server.
- H (WXYZ) is calculated from H (YZ) along with H (WX) sent by the server.
Finally, we compare H (WXYZ) with the root hash in the server. If the match, can confirm reliable data. If not, we should check the peer that sent Y to us and request Y from another peer.
So where is it good:
- Only very little information is required for authentication. Even if the number of leaf nodes (the data section) doubles, we only need to add 1 hash code and conduct hashing once more to verify.
- And with less data needed, this reduces the bandwidth load.

This is a big improvement over the previous approach where we need to send the entire hash code from the server.
Verify consistency
Distributed systems only allow data to be added that cannot be deleted. So Merkle Trees is very useful in validating any new version of the data that contains the old data.
Data synchronization
Merkle trees can be an alternative to comparing entire data to identify changes. We only need to compare the hash codes in the tree and once the leaf node changes, only that data needs to be synchronized with other nodes in the network.
III. Conclude
In this article, we step by step learn how Merkle trees work and compare it with other solutions and how it solves problems in distributed networks. Despite its high efficiency in use, installing it is extremely simple.
In the next article, I will guide you to install Merkle trees .
References
- https://www.codementor.io/blog/merkle-trees-5h9arzd3n8
- https://en.wikipedia.org/wiki/Merkle_tree
- Mastering Bitcoin: Unlocking Digital Cryptocurrencies – Andreas Antonopoulos