Nowadays, surely everyone of us has at least one Facebook account. Its most basic function is to allow uploading of images. In the article we will learn how Facebook stores those huge piles of photos.
Preamble

In 2009, the number of photos users uploaded to Facebook was 15 million. At that point each photo is uploaded they will create different sizes and store the equivalent of 60 billion photos and 1.5PB of storage. This number continues to grow by 220 million per week, equivalent to about 25TB of consumption. At peak it can be up to 550,000 shots per second. These numbers pose a challenge to Facebook’s photo storage infrastructure.
NFS photo infrastructure
Their old infrastructure consisted of several layers:
- The upload tier receives the user’s uploaded image and saves it to the NFS storage tier.
- The tier serves the HTTP requests of the images and serves them from the NFS storage tier.
- The NFS storage tier is built on commercial storage devices.
Since each image is stored in its own file, a huge amount of metadata is generated on the storage tier. The amount of metadata exceeds the caching capacity of the NFS storage layer, leading to many I/O operations per request to read or upload an image. The entire infrastructure is affected due to the high metadata costs of the NFS storage tier. This is one of the reasons why Facebook has to depend on a CDN to serve photos.
Two temporary optimal solutions are offered to minimize the problem:
- Cache: The server layer caches small profile images.
- NFS file handle cache: Implemented on top of the image service layer for the purpose of eliminating some of the metadata overhead of the NFS storage layer.
Those are just temporary solutions, they need a new infrastructure to meet the huge numbers above.
Haystack Photo Infrastructure
The new image infrastructure merges the image serving layer and the storage layer into one physical layer. It implements an HTTP request-based image server that stores images in a generic object store called Haystack .
The main requirement is to eliminate any redundant metadata overhead for image read operations, so that each read I/O operation only reads the actual image data (rather than the metadata file system).
Haystack can be divided into the following classes:
- HTTP server
- Photo Store
- Haystack Object Store
- Filesystem
- Storage
Filesystem
Haystack object stores are deployed on files stored in a single file system created on a 10TB drive. Image read requests result in read() system calls at known offsets in these files, but to perform reads, the file system must first locate the data on the actual physical drive ( will be detailed below). And they choose the XFS file system.
XFS filesystem, it’s called XFS and not an abbreviation for anything, is a high performance 64-bit journaling filesystem. XFS appeared in Linux kernels in 2001, as of June 2014 it was supported by most Linux distributions, some of which use XFS as the default filesystem.
An important feature of XFS is the ability to guarantee data access rates for applications (Guaranteed Rate I/O), allowing applications to maintain data access speeds on disk, which is very important. It is important for high-resolution video service delivery systems or satellite communication applications that require constant data manipulation rates to be maintained.
Haystack Object Store
Haystack is a simple (append-only) log structure that allows only insertions. The object store will contain the needles that represent the objects to be stored.
Haystack consists of 2 files: 1 file to store needle and 1 file index . 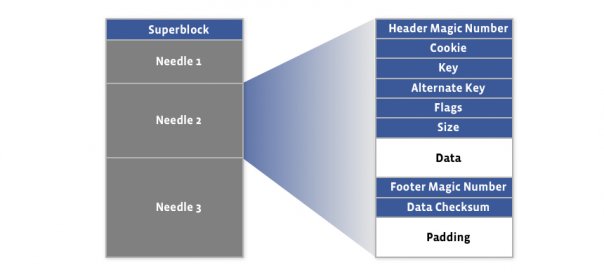
The first 8kb of haystack store will be superblock . Then there are the needles consisting of the header, data, and footer sections. 
- Header Magic Number + Footer Magic Number: Help locate the next needle during index file recovery.
- Cookie: Helps client secure against brute force attack.
- Key: Win 64-bit key storage
- Alternate key: Win 32-bit alternate key storage.
- Flags: Whether the hidden needle has been deleted or not. Because as mentioned above, haystack only inserts, so if we want to delete, we rely on this guy.
- Size: The size of the data.
- Data checksum: Check the checksum of needle.
- Padding: The total size of the needle is represented as 8 bytes.
A needle is uniquely identified by its <Offset, Key, Alternate Key, Cookie>, where offset is the needle’s position in the Haystack store. Haystack does not put any restrictions on the value of keys and there can be duplicate keys.
Components of the index file:
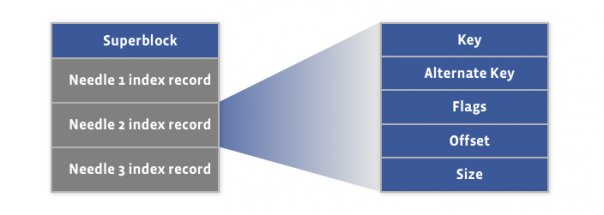

Each record in the index file corresponds to each needle in the haystack archive, and the order of index records must match the order of the associated needle in the haystack archive. The index file provides the minimal metadata to locate a needle in the haystack store.
Note that the index file is not important. As it can be rebuilt from the haystack archive if needed. Its purpose is to quickly load the needle into memory without having to iterate through the super large haystack file quickly, since the index file is usually less than 1% of the size of the other archive.
Writing to Haystack
When the file is uploaded, the system generates the corresponding needle and synchronously appends it to the haystack store file. After successfully saved it will save the necessary metadata of the needle into the index. Since the index file is not important, the records will be written asynchronously increasing performance. In the event of a failure, the recovery process will remove the faulty needles. Haystack does not allow overwriting existing needle positions. To update we will insert a new needle with the same set of <Key, Alternate Key, Cookie> as the old needle, Then when reading it will take the one with the largest position.
Reading from Haystack
Passing the <Offset, Key, Alternate Key, Cookie> parameters Haystack will then add the header and footer and read the entire needle from the file. The read operation succeeds only when the parameters, checksums all match, and flags indicate the file has not been deleted.
Delete operation in Haystack
It marks the needle in the haystack as deleted by setting the “deleted” bit in the flags field of needle. However, the associated index record is not modified in any way so the application may end up referencing a deleted needle. If the read operation sees the “deleted” flag and the operation succeeds with an appropriate error. Needle’s deleted space will not be recovered in any way.
Reference
Needle in a haystack: efficient storage of billions of photos