Currently in deep learning, the issue of data is very important. Therefore, there are areas where there is little data for train model, it is difficult to produce good results in the prediction. So people need a technique called data augmentation to serve if you have less data, you can still create more data based on the data you have. have. For example, the image below, which is the image created from an original image.
For example : 
The theory of data enhancement
Because I have read some of the articles online, and find this article to be quite good, I also do not need to re-present the theory of what to do. I would like to quote ngcthuong ‘s post here :
Basic data aumentation for machine vision:
- Original: Of course, I always have the original image
- Flip: Flip vertically, horizontally as long as the meaning of the photo (label) is kept or deduced. For example, identify a round ball, then we turn it into a ball. As for handwriting recognition, flip 8 is still 8, but 6 will be 9 (horizontal) and nothing will be vertical. As for medical imaging, the flip-down is never happening in the actual image -> what should not be flipped
- Random crop: random part of the photo. Note that when cutting to keep the main components of the image we care about. As with object recognition, if the image is cropped without an object, then the label value is incorrect.

- Color shift: Convert the color of an image by adding values to 3 RGB color channels. This is related to photos that sometimes have noise -> colors are affected.
- Noise addition: Add noise to the image. There are many types of noise such as random noise, sample noise, add noise, noise noise, noise caused by image compression, blur noise caused by non-focus shooting, motion noise, etc., including the whole day.
- Information loss: A part of a picture is lost. Can illustrate the obscure case.
- Constrast change: change the contrast of the picture, the saturation

- Geometry based: All types of rotation, flip, scale, padding, squeezing, deformation,
- Color based: same as above, more detailed is divided into (i) increased sharpness, (ii) increased brightness, (iii) increased contrast or (iv) changed to negative – negative image.
- Noise / occlusion: More detailed noise, as I mentioned above a lot. including tooth loss.
- Whether: add weather effects like rain, snow, fog, …
Some other examples
- Transitional: the ball moves left and right:

- Scale: convert the picture size
- Scale in
- Use GAN to change day to night, spring to summer
- Use GAN to change the style of the picture





Note that [4] the use of data aumgentation should be done randomly during training. And the use of GAN is to create unpredictable data, which can have side effects.
The problem of data augmentation!
Data and application dependent properties
The problem is that “every duck has fat and feather”, so many augmentation methods, which way to choose the best quality? The answer is – depending on the data (the number of samples, the balance / imbalance of the sample, the test data, etc.) and the corresponding application, that is, each data set will have its own way of augmentation. best fruit.
Typically, MNIST data is considered good with elastic distortion, scale, translation, and rotation. While natural image data such as CIFAR10 and ImageNet are good with random-cropping algorithms, iamge miroring, color shiffting / whitenting [8]. Not only that but some augmentation methods are not good for some data sets. For example, hroizontal flipping is good for CIFAR10 but not for MNIST (because flip is a different number already).
The variety of augmentation
With the list of augmentation mentioned above, there are many ways I have not listed them all. Each augmenation itself has its own Control Elements. I can categorize it
- Augmentation methods: flip, rotation, random crop, etc.
- Augmentation control elements: Each augmenation will have its own control elements. For example, how many rotations, scaling, scaling up and down how many times, random crop, how much random in the range …
- Frequency of using each augmentation method?
- The best way of augmentation is a set of augmentation methods
- The augmenation method for each training / epoch stage may be different. The first epoch at large leanring rate may be different from the last epoch at small learning rate
- The way of augmenation for each class, the frequency of using augmenation may vary
- The augmenation may also be affected by the network structure. That is, augmentation gives different levels of gain to each network. And not all of the above factors have the same effect on the level of quality improvement of augmentation.
How best augmentation?
The reliance on data and applications, network architecture, above means that you need to try quite a lot, and it will certainly take a lot of time but not sure how to augment the best.
Learn about Data Agumentation in keras
In keras support class ImageDataGenerator allows creating more data. Today I would like to present it.
The ImageDataGenerator class has 3 methods of flow (), flow_from_directory () and flow_from_dataframe () to read images from a large numpy array and image directory (from a big numpy array and folder containing images)
We will discuss flow_from_directory () in this article.
Suppose you have downloaded a dataset and you have 2 training and test directories, in each directory you have subfolders, each of which contains images belonging to that sub-directory. (See the picture below to understand what you are saying)
Create a validation set, usually you have to manually create a validation data by sampling images from the train folder (you can take them randomly, or get the order you want) and move them into a letter called “valid”. “. If you already have validation sets, you can use them instead of creating them manually. 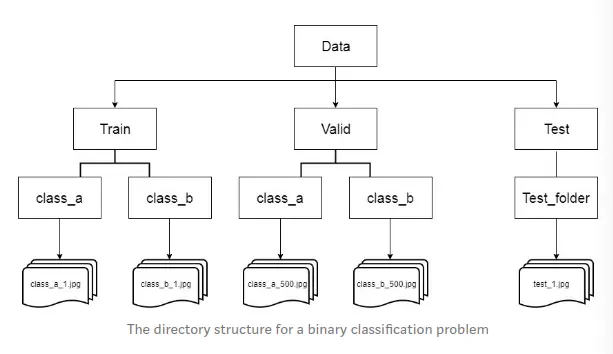
As you can see in the image above, the Test folder contains only one test_folder folder and inside there are all images for testing.
The name of the folder for the class is very important, naming (or changing the teen) them with the corresponding label name can be easy for you later. After setting the images into the above structure, you should be ready to code!
With class ImageDataGenerator
Has the following properties:
- zoom_range : perform random zoom in a certain range
- width_shift_range : Translate horizontally randomly in a range
- height_shift_range : Translate photos vertically within a certain range
- brightness_range : Enhance the brightness of the image in a certain range.
- vertical_flip : Flip random pictures vertically
- rotation_range : Rotate the image angle up to 45 degrees
- shear_range : Distort the image
With flow_from_directory
Here are the commonly used attributes with flow_from_directory ():
1 2 3 4 5 6 7 8 9 10 | train_generator <span class="token operator">=</span> train_datagen <span class="token punctuation">.</span> flow_from_directory <span class="token punctuation">(</span> directory <span class="token operator">=</span> r <span class="token string">"./train/"</span> <span class="token punctuation">,</span> target_size <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">224</span> <span class="token punctuation">,</span> <span class="token number">224</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> color_mode <span class="token operator">=</span> <span class="token string">"rgb"</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> <span class="token number">32</span> <span class="token punctuation">,</span> class_mode <span class="token operator">=</span> <span class="token string">"categorical"</span> <span class="token punctuation">,</span> shuffle <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> seed <span class="token operator">=</span> <span class="token number">42</span> <span class="token punctuation">)</span> |
- directory : must include the path with the classes of the folder.
- target_size : is the size of the input image, each image will be resized according to this size.
- color_mode : If the image is black and white or grayscale then set “grayscale” or if it consists of 3 channels then set “rgb”
- batch_size : Number of images to be yielded from the generator for each batch of batch.
- class_mode : set “binary” if you have 2 classes to predict, otherwise you set “categorical”. in case if you are programming an Autoencoder, both the input and output are images, in this case you set the input.
- shuffle : set True if you want to change the image order, otherwise set False.
- seed : Random seed to apply an incremental random image and shuffle the order of the images
1 2 3 4 5 6 7 8 9 10 | valid_generator <span class="token operator">=</span> valid_datagen <span class="token punctuation">.</span> flow_from_directory <span class="token punctuation">(</span> directory <span class="token operator">=</span> r <span class="token string">"./valid/"</span> <span class="token punctuation">,</span> target_size <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">224</span> <span class="token punctuation">,</span> <span class="token number">224</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> color_mode <span class="token operator">=</span> <span class="token string">"rgb"</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> <span class="token number">32</span> <span class="token punctuation">,</span> class_mode <span class="token operator">=</span> <span class="token string">"categorical"</span> <span class="token punctuation">,</span> shuffle <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">,</span> seed <span class="token operator">=</span> <span class="token number">42</span> <span class="token punctuation">)</span> |
- Same as train generator except for obvious changes such as directory path.
1 2 3 4 5 6 7 8 9 10 | test_generator <span class="token operator">=</span> test_datagen <span class="token punctuation">.</span> flow_from_directory <span class="token punctuation">(</span> directory <span class="token operator">=</span> r <span class="token string">"./test/"</span> <span class="token punctuation">,</span> target_size <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">224</span> <span class="token punctuation">,</span> <span class="token number">224</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> color_mode <span class="token operator">=</span> <span class="token string">"rgb"</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">,</span> class_mode <span class="token operator">=</span> <span class="token boolean">None</span> <span class="token punctuation">,</span> shuffle <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">,</span> seed <span class="token operator">=</span> <span class="token number">42</span> <span class="token punctuation">)</span> |
- directory : the path contains a folder, including images for testing. For example, in the case of the directory structure above, the images will be found at / test / test_images / Other parameters are the same as above.
Thank you for reading the presentation. Hope you will have more knowledge about data augumentation