1. Distributed tracing
In the process of developing and operating a system, to solve the problems that arise, we often have to monitor the flow of requests in the system. Flow of a request is started since the system receives the request and ends when the system no longer processes the request. This technique is known as tracing .
Unlike monolithic systems, microservice system requests are spread over many services. Tracking the flow of a request on a distributed system is not an easy task and takes quite a bit of time. At this point, we can apply the distributed tracing technique:
- The service that receives the first request assigns the request a correlation ID – the identifier that identifies the request.
- Downstream requests continue to propagate this correlation ID:
- If the communication between services is via an HTTP request, the correlation ID will be appended to the request header.
- If the communication between services is through messaging systems, the correlation ID will be included in the message.
- Logs related to the request will contain the correlation ID .
- Tracing data will be collected and analyzed by systems like Zipkin or Jaeger .
Through distributed tracing, we can track the flow of a request more easily: determine the total time it takes for the system to process that request, or know which problem the request has experienced.
2. Spring Cloud Sleuth
Spring Cloud Sleuth is a library that helps us perform distributed tracing for Spring Cloud applications. Spring Cloud Sleuth tracks requests on servlet filters, REST templates, scheduled actions, message channels, Zuul filters, and Feign clients.
Spring Cloud Sleuth uses two terms span and trace taken from Google Dapper :
Span : This is the most basic unit for tracing, corresponding to an operation in the system. For example, sending an HTTP request and receiving an HTTP request response are the same span. Spans are identified by a unique 64-bit ID. Span also contains other data such as descriptions, timestamped events, key-value annotations (tags), ID of the preceding span, and process ID (usually IP addresses).
When a span is started, the span will be assigned a name and the start time will be saved.
When a span is closed, the close time is saved. If the span is sample , the data of the span will be sent to systems like Zipkin. Determining whether a span is sample or not will be based on a ratio. This mechanism is called sampling . The reason Spring Cloud Sleuth applies this mechanism is because in large systems, sending span data continuously costs a lot.
Trace : is a collection of spans organized as a tree. The first span of trace is called the root span . The ID of the trace is the ID of the root span.
The Trace ID and span ID will be added to the log by Spring Cloud Sleuth via Sl4J MDC, with the default format: [appname,traceId,spanId,exportable]
Inside:
appname: the name of the application that contains the log.traceId: The ID of trace contains spanspanId: ID of the span.exportable: determines whether the log has been sent to Zipkin or not.
For example:
1 2 | 2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ... |
3. Zipkin
Zipkin is a distributed tracing open source system. Zipkin is built on the Google Dapper . Zipkin is used to fix latency related issues in microservice systems.
Zipkin has a fairly straightforward operating architecture:
- Reporter sends tracing data from the application to Zipkin via HTTP or message system (Kafka, RabbitMQ).
- At Zipkin, the collector is responsible for collecting and validating data.
- The data is then stored inside the default storage as Cassandra. We can choose other storage like Elasticsearch or MySQL.
- Zipkin provides UI so that users can easily search and track data. The UI will retrieve data from the API .

4. Grab all
Step 1: Start Zipkin
1 2 | $ docker run --name <span class="token operator">=</span> zipkin -d -p 9411:9411 openzipkin/zipkin |
After Docker container run, we can access Zipkin UI at http: // localhost: 9411 / zipkin /

Step 2: Configure Spring Cloud Sleuth
To use Spring Cloud Sleuth with Zipkin, we need the following 2 dependencies:
pom.xml
1 2 3 4 5 6 7 8 9 | <span class="token tag"><span class="token tag"><span class="token punctuation"><</span> dependency</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span> groupId</span> <span class="token punctuation">></span></span> org.springframework.cloud <span class="token tag"><span class="token tag"><span class="token punctuation"></</span> groupId</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span> artifactId</span> <span class="token punctuation">></span></span> spring-cloud-starter-sleuth <span class="token tag"><span class="token tag"><span class="token punctuation"></</span> artifactId</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"></</span> dependency</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span> dependency</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span> groupId</span> <span class="token punctuation">></span></span> org.springframework.cloud <span class="token tag"><span class="token tag"><span class="token punctuation"></</span> groupId</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"><</span> artifactId</span> <span class="token punctuation">></span></span> spring-cloud-starter-zipkin <span class="token tag"><span class="token tag"><span class="token punctuation"></</span> artifactId</span> <span class="token punctuation">></span></span> <span class="token tag"><span class="token tag"><span class="token punctuation"></</span> dependency</span> <span class="token punctuation">></span></span> |
By default when we add the dependency spring-cloud-starter-zipkin , the span data will be sent to Zipkin via HTTP ( http: // localhost: 9411 ). To change this URL, we configure it via the spring.zipkin.base-url .
Besides, to change the sampling rate, we will configure it through the spring.sleuth.sampler.probability property. The value of this attribute is a decimal. For example, spring.sleuth.sampler.probability=1.0 => sends data of all spans to Zipkin.
…
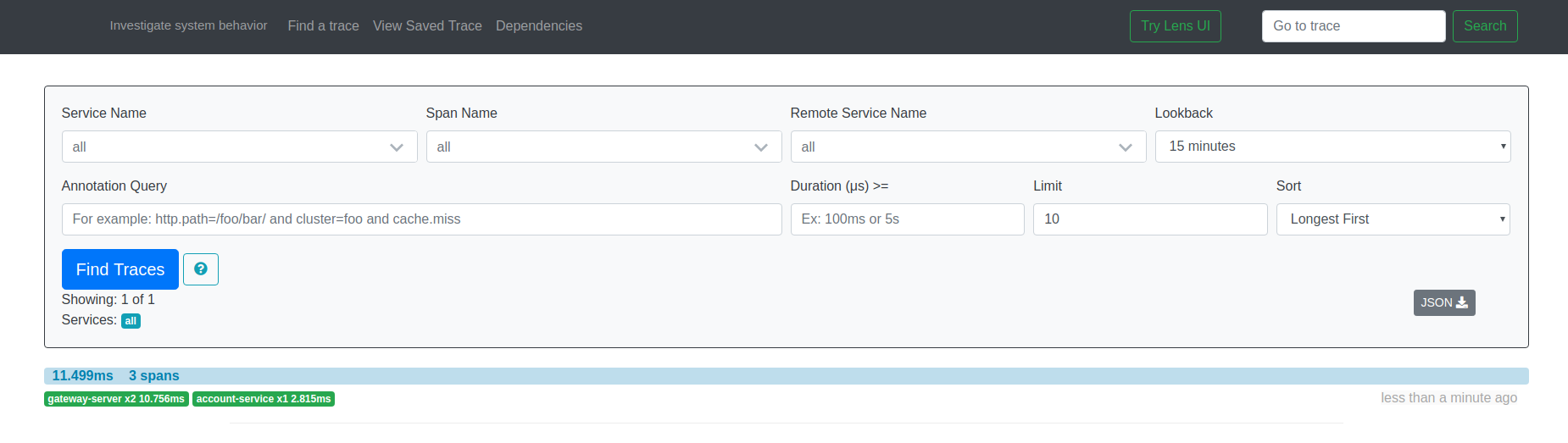
I will apply Spring Cloud Sleuth to 2 services in a microservice demo application, gateway-server and account-service .
Try calling API http://localhost:8080/account-service/details/123 . Upon receiving the request, the gateway-server will call the account-service .



References