Post goals
Question analysis is the first phase in the general architecture of an Q&A system, with the task of finding out necessary information as input for the processing of the following phases (document extraction, sentence extraction reply, …). Therefore, question analysis plays a very important role, directly influencing the operation of the whole system. If the analysis of the question is not good, it will not be possible to find the answer.
Today I will present about the methods of classifying the intentions of the questioners in a question and answer system based on the data set of questions of Civil Engineering University students. During the construction process, I have tested many different methods, but with this blog scope I will share a best method that I have used, other methods I will gradually share in the posts. next.
What is Intent Determination?
For question and answer systems, intent classification is the determination of the intent of the questioner when interacting with the system through the user’s question or query. For example to the question: “Where can I ask the address of facility A?”, The user’s intention is to ask about ‘ADDRESS’, for example, the question: “Opening hours What time is the store? ” then the user’s intention is to ask about ‘TIME’. Relying on the intent determination will help answer the question correctly and give the answer the user wants.
Methods of determining intent
For problems that require an intent to be determined, there are many methods to do it.
Shallow approach
The classical approach is based on the frequency of occurrence and the importance of words in known intentions or shallow approach. For example, to ask about time, in the question, words like “what time”, “what day”, “what month”, “year”, … and the intention to ask about the place, there will be words: “where”, “address”, “where”, etc. Many methods used in Q&A use keyword-based techniques to locate sentences and paragraphs that can contain Answers from selected texts about. Then keep the sentences, paragraphs containing string of characters of the same type as the desired answer type (eg questions about names of people, places, quantity …).
When determining the most common words in the intentions, depending on the probability of the occurrence of the words in the question, we will predict the likelihood of which the user’s intent will belong. However, such dictionary-based determination will be incomplete and inaccurate. Natural language is an ambiguous language, so some questions, based on such words, are unlikely to determine the intent of the question.
A deep approach
In cases where the surface approach cannot find the answer, grammatical, semantic, and contextual processes are needed to extract or generate the answer. Commonly used techniques such as named-entity recognition, relationship extraction, semantic ambiguity, etc. The system often uses knowledge resources such as Wordnet, ontology to enrich its capabilities. arguments through definitions and semantic relationships. Statistical language model-based Q&A systems are also gaining popularity.
In this article, I will approach in-depth approach.
Data used
To build a model to determine question intent, I will use ontology which are pairs of “question – intent” collected from students of the University of Civil Engineering. I will take the problem of building a classification model with classes as the intentions of the questioner. The following examples are the questions in the data set:
1 2 3 4 5 6 7 8 9 10 11 | {'content': 'thưa thầy cô, bảng điểm của em hiện tại giờ được 1 môn C+ 2 tín chỉ, 2 môn ghi F là em bảo lưu ạ, nhưng điểm hệ số 4 của em lại ghi 0.45 là như nào ạ, mong các thầy cô giải đáp hộ em', 'intent': 'DIEM'} {'content': 'với tiêu chí xét học bổng năm 2 là bắt buộc qua tacb1,2 hay phải đạt 250 toeic ạ ', 'intent': 'HOC_BONG'} {'content': 'Em chào thầy cô ạ. Em xin được có một vài lời về vấn đề học bổng của nhà trường ạ. Trước tiên em xin chân thành cảm ơn quý thầy cô và nhà trường đã tạo điều kiện cho em cũng như các anh chị, các bạn sinh viên được học tập và thêm vào đó là những suất học bổng những phần quà để động viên tinh thần học tập của sinh viên chúng em. Theo em được biết thì trong khoảng thời gian trước thời điểm hiện tại thì nhà trường đã tiến hành trao học bổng cho sinh viên trong diện được xét học bổng của kì học trước. Một vài bạn trong lớp em đã nhận được học bổng nhưng riêng về cá nhân em thì em vẫn chưa nhận được học bổng ạ. Em không rõ là do có sai sót gì không nên em rất mong nhà trường xem xét lại và cho em lời đáp ạ. Những lời em nói ở trên nếu có chỗ nào không phù hợp thì cho em xin lỗi ạ. Em rất mong nhận được hồi âm ạ. Em xin chân thành cảm ơn ạ!', 'intent': 'HOC_BONG'} {'content': 'Trong khoảng thời gian chờ bằng, em có được phép đăng ký học lại môn học để nâng điểm tích lũy hay không?', 'intent': 'DKMH'} {'content': 'Em đã bảo vệ đồ án tốt nghiệp thì có thể học lại để cải thiện điểm các môn không ạ', 'intent': 'DKMH'} {'content': 'Em muốn xin hoãn xét tốt nghiệp để học cải thiện thì có được không ạ, và làm cách nào để đăng ký môn học ạ', 'intent': 'DKMH'} {'content': 'Thưa thầy, em học khóa 62 em có thể học lại môn cơ học đất khóa 64 được không ạ. Vì em thấy mã môn học khác nhau (138802, 130211)', 'intent': 'DKMH'} {'content': 'Cho em hỏi em có thể đăng ký trả nợ môn học cùng tên nhưng khác mã được không ạ?', 'intent': 'DKMH'} {'content': 'Em chào cô. Cô cho emxa0hỏixa0lâu nữa không sẽ có đợt huỷ môn học mà mình đăng kí nhầm vậy cô. Em cảm ơn cô nhiều.', 'intent': 'DKMH'} {'content': 'Cho em hỏi nếu em đăng ký môn học mà bị nhầm thì có hủy được không ạ', 'intent': 'DKMH'} |
The questions were divided into 10 groups of intent: ['DIEM', 'HOC_BONG', 'DKMH', 'HOC_PHI', 'KHAC', 'LICH_HOC', 'TAI_KHOAN', 'THU_TUC_SV', 'TN', 'TOEIC'] In there
- ‘DIEM’ includes the Scoring questionnaire
- ‘HOC_BONG’ includes a scholarship questionnaire
- ‘DKMH’ includes questions about subject registration
- ‘HOC_PHI’ includes questions about tuition fees
…
- ‘KHAC’ includes questions that do not belong to one of the above 9 groups
Building a model
Resources
The data, pre-trained for the representation models, can be downloaded here .
Install the necessary packages
In this article, I use the pyvi library to conduct some pre-processing with the text. To install, run the following command:
1 2 | pip3 <span class="token function">install</span> pyvi |
Import the required libraries
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | <span class="token comment"># -*- coding: utf-8 -*-</span> <span class="token keyword">import</span> pandas <span class="token keyword">as</span> pd <span class="token keyword">import</span> string <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np <span class="token keyword">import</span> re <span class="token punctuation">,</span> os <span class="token punctuation">,</span> string <span class="token keyword">from</span> pyvi <span class="token keyword">import</span> ViTokenizer <span class="token keyword">from</span> pyvi <span class="token punctuation">.</span> ViTokenizer <span class="token keyword">import</span> tokenize <span class="token keyword">import</span> tensorflow <span class="token keyword">as</span> tf <span class="token keyword">from</span> gensim <span class="token punctuation">.</span> models <span class="token punctuation">.</span> fasttext <span class="token keyword">import</span> FastText <span class="token keyword">import</span> json <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> preprocessing <span class="token keyword">import</span> MinMaxScaler <span class="token keyword">from</span> tensorflow <span class="token punctuation">.</span> keras <span class="token keyword">import</span> <span class="token operator">*</span> <span class="token keyword">from</span> tensorflow <span class="token punctuation">.</span> keras <span class="token punctuation">.</span> layers <span class="token keyword">import</span> <span class="token operator">*</span> <span class="token keyword">from</span> tensorflow <span class="token punctuation">.</span> keras <span class="token punctuation">.</span> utils <span class="token keyword">import</span> to_categorical <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> model_selection <span class="token keyword">import</span> <span class="token operator">*</span> <span class="token keyword">import</span> matplotlib <span class="token punctuation">.</span> pyplot <span class="token keyword">as</span> plt <span class="token punctuation">;</span> plt <span class="token punctuation">.</span> rcdefaults <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">import</span> matplotlib <span class="token punctuation">.</span> pyplot <span class="token keyword">as</span> plt |
Declare preprocessor functions
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | <span class="token comment"># Loại bỏ các ký tự thừa</span> <span class="token keyword">def</span> <span class="token function">clean_text</span> <span class="token punctuation">(</span> text <span class="token punctuation">)</span> <span class="token punctuation">:</span> text <span class="token operator">=</span> re <span class="token punctuation">.</span> sub <span class="token punctuation">(</span> <span class="token string">'<.*?>'</span> <span class="token punctuation">,</span> <span class="token string">''</span> <span class="token punctuation">,</span> text <span class="token punctuation">)</span> <span class="token punctuation">.</span> strip <span class="token punctuation">(</span> <span class="token punctuation">)</span> text <span class="token operator">=</span> re <span class="token punctuation">.</span> sub <span class="token punctuation">(</span> <span class="token string">'(s)+'</span> <span class="token punctuation">,</span> <span class="token string">r'1'</span> <span class="token punctuation">,</span> text <span class="token punctuation">)</span> <span class="token keyword">return</span> text <span class="token comment">#tách câu</span> <span class="token keyword">def</span> <span class="token function">sentence_segment</span> <span class="token punctuation">(</span> text <span class="token punctuation">)</span> <span class="token punctuation">:</span> sents <span class="token operator">=</span> re <span class="token punctuation">.</span> split <span class="token punctuation">(</span> <span class="token string">"([.?!])?[n]+|[.?!] "</span> <span class="token punctuation">,</span> text <span class="token punctuation">)</span> <span class="token keyword">return</span> sents <span class="token comment">#tách từ</span> <span class="token keyword">def</span> <span class="token function">word_segment</span> <span class="token punctuation">(</span> sent <span class="token punctuation">)</span> <span class="token punctuation">:</span> sent <span class="token operator">=</span> tokenize <span class="token punctuation">(</span> sent <span class="token punctuation">)</span> <span class="token keyword">return</span> sent <span class="token comment">#Chuẩn hóa từ</span> <span class="token keyword">def</span> <span class="token function">normalize_text</span> <span class="token punctuation">(</span> text <span class="token punctuation">)</span> <span class="token punctuation">:</span> listpunctuation <span class="token operator">=</span> string <span class="token punctuation">.</span> punctuation <span class="token punctuation">.</span> replace <span class="token punctuation">(</span> <span class="token string">'_'</span> <span class="token punctuation">,</span> <span class="token string">''</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> listpunctuation <span class="token punctuation">:</span> text <span class="token operator">=</span> text <span class="token punctuation">.</span> replace <span class="token punctuation">(</span> i <span class="token punctuation">,</span> <span class="token string">' '</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> text <span class="token punctuation">.</span> lower <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
To remove the stop word, I use the stop word list, you replace stopwords.csv with the path in my file above.
1 2 3 4 5 6 7 8 9 10 11 12 | filename <span class="token operator">=</span> <span class="token string">'stopwords.csv'</span> data <span class="token operator">=</span> pd <span class="token punctuation">.</span> read_csv <span class="token punctuation">(</span> filename <span class="token punctuation">,</span> sep <span class="token operator">=</span> <span class="token string">"t"</span> <span class="token punctuation">,</span> encoding <span class="token operator">=</span> <span class="token string">'utf-8'</span> <span class="token punctuation">)</span> list_stopwords <span class="token operator">=</span> data <span class="token punctuation">[</span> <span class="token string">'stopwords'</span> <span class="token punctuation">]</span> <span class="token keyword">def</span> <span class="token function">remove_stopword</span> <span class="token punctuation">(</span> text <span class="token punctuation">)</span> <span class="token punctuation">:</span> pre_text <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> words <span class="token operator">=</span> text <span class="token punctuation">.</span> split <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> word <span class="token keyword">in</span> words <span class="token punctuation">:</span> <span class="token keyword">if</span> word <span class="token keyword">not</span> <span class="token keyword">in</span> list_stopwords <span class="token punctuation">:</span> pre_text <span class="token punctuation">.</span> append <span class="token punctuation">(</span> word <span class="token punctuation">)</span> text2 <span class="token operator">=</span> <span class="token string">' '</span> <span class="token punctuation">.</span> join <span class="token punctuation">(</span> pre_text <span class="token punctuation">)</span> <span class="token keyword">return</span> text2 |
Train the FastText model to match the problem data
In this article, I use FastText in Gensim’s library package to encode words into vector (word2vec). Your training data to the file xaa . FastText is considered to be better than word2vec in expressing new words, so I will use it in this problem. This is a file consisting of a part of articles from Wikipedia, the documents have been pre-processed with a number of techniques such as word separation, word removal, normalization …
In addition, I also need to add the sentences in the data file of the intent classification data set to train the word2vec model. This helps to add some words in the topology data domain that are not available in the wikipedia linguistic set. This makes the FastText model more expressive.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | <span class="token keyword">import</span> json wiki_data_path <span class="token operator">=</span> <span class="token string">'xaa'</span> qa_data_path <span class="token operator">=</span> <span class="token string">'intent_db_v2.json'</span> <span class="token keyword">def</span> <span class="token function">read_data</span> <span class="token punctuation">(</span> path <span class="token punctuation">)</span> <span class="token punctuation">:</span> traindata <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> sents <span class="token operator">=</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> pathdata <span class="token punctuation">,</span> <span class="token string">'r'</span> <span class="token punctuation">)</span> <span class="token punctuation">.</span> readlines <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> sent <span class="token keyword">in</span> sents <span class="token punctuation">:</span> traindata <span class="token punctuation">.</span> append <span class="token punctuation">(</span> sent <span class="token punctuation">.</span> split <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">with</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> qa_data_path <span class="token punctuation">)</span> <span class="token keyword">as</span> json_file <span class="token punctuation">:</span> qa_data <span class="token operator">=</span> json <span class="token punctuation">.</span> load <span class="token punctuation">(</span> json_file <span class="token punctuation">)</span> <span class="token keyword">for</span> question <span class="token keyword">in</span> qa_data <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'content'</span> <span class="token keyword">in</span> question <span class="token punctuation">:</span> content <span class="token operator">=</span> clean_text <span class="token punctuation">(</span> question <span class="token punctuation">[</span> <span class="token string">'content'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> content <span class="token operator">=</span> word_segment <span class="token punctuation">(</span> content <span class="token punctuation">)</span> content <span class="token operator">=</span> remove_stopword <span class="token punctuation">(</span> normalize_text <span class="token punctuation">(</span> content <span class="token punctuation">)</span> <span class="token punctuation">)</span> traindata <span class="token punctuation">.</span> append <span class="token punctuation">(</span> content <span class="token punctuation">.</span> split <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">"Corpus loaded"</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> traindata <span class="token punctuation">,</span> qa_data train_data <span class="token punctuation">,</span> qa_data <span class="token operator">=</span> read_data <span class="token punctuation">(</span> wiki_data_path <span class="token punctuation">)</span> |
Train the FastText model as follows:
1 2 3 4 | model_fasttext <span class="token operator">=</span> FastText <span class="token punctuation">(</span> size <span class="token operator">=</span> <span class="token number">150</span> <span class="token punctuation">,</span> window <span class="token operator">=</span> <span class="token number">10</span> <span class="token punctuation">,</span> min_count <span class="token operator">=</span> <span class="token number">2</span> <span class="token punctuation">,</span> workers <span class="token operator">=</span> <span class="token number">4</span> <span class="token punctuation">,</span> sg <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">)</span> model_fasttext <span class="token punctuation">.</span> build_vocab <span class="token punctuation">(</span> train_data <span class="token punctuation">)</span> model_fasttext <span class="token punctuation">.</span> train <span class="token punctuation">(</span> train_data <span class="token punctuation">,</span> total_examples <span class="token operator">=</span> model_fasttext <span class="token punctuation">.</span> corpus_count <span class="token punctuation">,</span> epochs <span class="token operator">=</span> model_fasttext <span class="token punctuation">.</span> <span class="token builtin">iter</span> <span class="token punctuation">)</span> |
After the training is complete, you need to save the model to use for the next time with the following code:
1 2 | model_fasttext <span class="token punctuation">.</span> wv <span class="token punctuation">.</span> save <span class="token punctuation">(</span> <span class="token string">"fasttext_gensim.model"</span> <span class="token punctuation">)</span> |
To re-type the model we do the following:
1 2 | fast_text_model <span class="token operator">=</span> KeyedVectors <span class="token punctuation">.</span> load <span class="token punctuation">(</span> <span class="token string">'/content/drive/MyDrive/NUCE/NLP/QA/model/fasttext_gensim.model'</span> <span class="token punctuation">)</span> |
Test print one word size:
1 2 3 | input_text <span class="token operator">=</span> fast_text_model <span class="token punctuation">.</span> wv <span class="token punctuation">.</span> get_vector <span class="token punctuation">(</span> <span class="token string">"hôm_nay"</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> input_text <span class="token punctuation">.</span> shape <span class="token punctuation">)</span> |
1 2 | (150,) |
Word representation and sentence representation
After training the FastText model, we will encode sentences into vectors by encoding each word in the sentence and putting the vector representing these words into a vector the size of the longest sentence. (to make sure the sentences are fully represented). Sentences shorter than the longest sentence will be padding with zeros to bring sentences to the same size without affecting the meaning of the sentence. The padding I use the function tf.keras.preprocessing.sequence.pad_sequences
The code does the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | max_length_inp <span class="token operator">=</span> <span class="token number">30</span> <span class="token keyword">def</span> <span class="token function">sentence_embedding</span> <span class="token punctuation">(</span> sent <span class="token punctuation">)</span> <span class="token punctuation">:</span> content <span class="token operator">=</span> clean_text <span class="token punctuation">(</span> sent <span class="token punctuation">)</span> content <span class="token operator">=</span> word_segment <span class="token punctuation">(</span> content <span class="token punctuation">)</span> content <span class="token operator">=</span> remove_stopword <span class="token punctuation">(</span> normalize_text <span class="token punctuation">(</span> content <span class="token punctuation">)</span> <span class="token punctuation">)</span> inputs <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> word <span class="token keyword">in</span> content <span class="token punctuation">.</span> split <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> word <span class="token keyword">in</span> fast_text_model <span class="token punctuation">.</span> wv <span class="token punctuation">.</span> vocab <span class="token punctuation">:</span> inputs <span class="token punctuation">.</span> append <span class="token punctuation">(</span> fast_text_model <span class="token punctuation">.</span> wv <span class="token punctuation">.</span> get_vector <span class="token punctuation">(</span> word <span class="token punctuation">)</span> <span class="token punctuation">)</span> inputs <span class="token operator">=</span> tf <span class="token punctuation">.</span> keras <span class="token punctuation">.</span> preprocessing <span class="token punctuation">.</span> sequence <span class="token punctuation">.</span> pad_sequences <span class="token punctuation">(</span> <span class="token punctuation">[</span> inputs <span class="token punctuation">]</span> <span class="token punctuation">,</span> maxlen <span class="token operator">=</span> max_length_inp <span class="token punctuation">,</span> dtype <span class="token operator">=</span> <span class="token string">'float32'</span> <span class="token punctuation">,</span> padding <span class="token operator">=</span> <span class="token string">'post'</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> inputs |
Read the data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <span class="token keyword">import</span> json <span class="token keyword">def</span> <span class="token function">read_data</span> <span class="token punctuation">(</span> qa_data_input <span class="token punctuation">)</span> <span class="token punctuation">:</span> sentences <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> labels <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> intents <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> question <span class="token keyword">in</span> qa_data <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token string">'intent'</span> <span class="token keyword">in</span> question <span class="token punctuation">:</span> <span class="token keyword">if</span> question <span class="token punctuation">[</span> <span class="token string">'intent'</span> <span class="token punctuation">]</span> <span class="token keyword">not</span> <span class="token keyword">in</span> intents <span class="token punctuation">:</span> intents <span class="token punctuation">.</span> append <span class="token punctuation">(</span> question <span class="token punctuation">[</span> <span class="token string">'intent'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> sentences <span class="token punctuation">.</span> append <span class="token punctuation">(</span> sentence_embedding <span class="token punctuation">(</span> question <span class="token punctuation">[</span> <span class="token string">'content'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> labels <span class="token punctuation">.</span> append <span class="token punctuation">(</span> intents <span class="token punctuation">.</span> index <span class="token punctuation">(</span> question <span class="token punctuation">[</span> <span class="token string">'intent'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">"Corpus loaded"</span> <span class="token punctuation">)</span> <span class="token keyword">return</span> sentences <span class="token punctuation">,</span> labels <span class="token punctuation">,</span> intents sentences <span class="token punctuation">,</span> labels <span class="token punctuation">,</span> intents <span class="token operator">=</span> read_data <span class="token punctuation">(</span> qa_data <span class="token punctuation">)</span> |
Data division
Because the data in the classes is not equal, so to correctly evaluate the model we need to divide the rating data so that the number of samples in the classes is equal.
Here is an image of the number of questions in the respective classes:
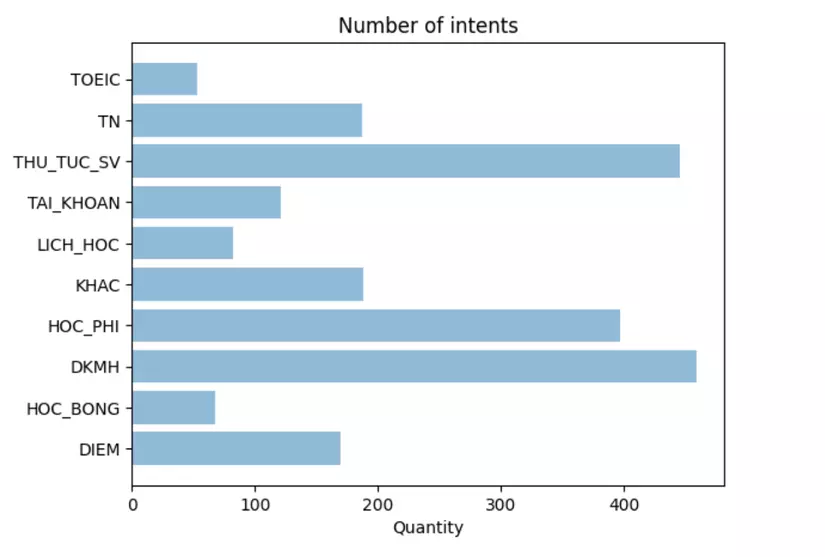
To divide the questions in the same validate set classes, we do the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | <span class="token keyword">def</span> <span class="token function">split_balanced</span> <span class="token punctuation">(</span> data <span class="token punctuation">,</span> target <span class="token punctuation">,</span> test_size <span class="token operator">=</span> <span class="token number">0.2</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> classes <span class="token operator">=</span> np <span class="token punctuation">.</span> unique <span class="token punctuation">(</span> target <span class="token punctuation">)</span> <span class="token comment"># can give test_size as fraction of input data size of number of samples</span> <span class="token keyword">if</span> test_size <span class="token operator"><</span> <span class="token number">1</span> <span class="token punctuation">:</span> n_test <span class="token operator">=</span> np <span class="token punctuation">.</span> <span class="token builtin">round</span> <span class="token punctuation">(</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> target <span class="token punctuation">)</span> <span class="token operator">*</span> test_size <span class="token punctuation">)</span> <span class="token keyword">else</span> <span class="token punctuation">:</span> n_test <span class="token operator">=</span> test_size n_train <span class="token operator">=</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> <span class="token number">0</span> <span class="token punctuation">,</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> target <span class="token punctuation">)</span> <span class="token operator">-</span> n_test <span class="token punctuation">)</span> n_train_per_class <span class="token operator">=</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token builtin">int</span> <span class="token punctuation">(</span> np <span class="token punctuation">.</span> floor <span class="token punctuation">(</span> n_train <span class="token operator">/</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> classes <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> n_test_per_class <span class="token operator">=</span> <span class="token builtin">max</span> <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token punctuation">,</span> <span class="token builtin">int</span> <span class="token punctuation">(</span> np <span class="token punctuation">.</span> floor <span class="token punctuation">(</span> n_test <span class="token operator">/</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> classes <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> ixs <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> cl <span class="token keyword">in</span> classes <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token punctuation">(</span> n_train_per_class <span class="token operator">+</span> n_test_per_class <span class="token punctuation">)</span> <span class="token operator">></span> np <span class="token punctuation">.</span> <span class="token builtin">sum</span> <span class="token punctuation">(</span> target <span class="token operator">==</span> cl <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token comment"># if data has too few samples for this class, do upsampling</span> <span class="token comment"># split the data to training and testing before sampling so data points won't be</span> <span class="token comment"># shared among training and test data</span> splitix <span class="token operator">=</span> <span class="token builtin">int</span> <span class="token punctuation">(</span> np <span class="token punctuation">.</span> ceil <span class="token punctuation">(</span> n_train_per_class <span class="token operator">/</span> <span class="token punctuation">(</span> n_train_per_class <span class="token operator">+</span> n_test_per_class <span class="token punctuation">)</span> <span class="token operator">*</span> np <span class="token punctuation">.</span> <span class="token builtin">sum</span> <span class="token punctuation">(</span> target <span class="token operator">==</span> cl <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> ixs <span class="token punctuation">.</span> append <span class="token punctuation">(</span> np <span class="token punctuation">.</span> r_ <span class="token punctuation">[</span> np <span class="token punctuation">.</span> random <span class="token punctuation">.</span> choice <span class="token punctuation">(</span> np <span class="token punctuation">.</span> nonzero <span class="token punctuation">(</span> target <span class="token operator">==</span> cl <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">[</span> <span class="token punctuation">:</span> splitix <span class="token punctuation">]</span> <span class="token punctuation">,</span> n_train_per_class <span class="token punctuation">)</span> <span class="token punctuation">,</span> np <span class="token punctuation">.</span> random <span class="token punctuation">.</span> choice <span class="token punctuation">(</span> np <span class="token punctuation">.</span> nonzero <span class="token punctuation">(</span> target <span class="token operator">==</span> cl <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">[</span> splitix <span class="token punctuation">:</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> n_test_per_class <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token keyword">else</span> <span class="token punctuation">:</span> ixs <span class="token punctuation">.</span> append <span class="token punctuation">(</span> np <span class="token punctuation">.</span> random <span class="token punctuation">.</span> choice <span class="token punctuation">(</span> np <span class="token punctuation">.</span> nonzero <span class="token punctuation">(</span> target <span class="token operator">==</span> cl <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> n_train_per_class <span class="token operator">+</span> n_test_per_class <span class="token punctuation">,</span> replace <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token comment"># take same num of samples from all classes</span> ix_train <span class="token operator">=</span> np <span class="token punctuation">.</span> concatenate <span class="token punctuation">(</span> <span class="token punctuation">[</span> x <span class="token punctuation">[</span> <span class="token punctuation">:</span> n_train_per_class <span class="token punctuation">]</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> ixs <span class="token punctuation">]</span> <span class="token punctuation">)</span> ix_test <span class="token operator">=</span> np <span class="token punctuation">.</span> concatenate <span class="token punctuation">(</span> <span class="token punctuation">[</span> x <span class="token punctuation">[</span> n_train_per_class <span class="token punctuation">:</span> <span class="token punctuation">(</span> n_train_per_class <span class="token operator">+</span> n_test_per_class <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> ixs <span class="token punctuation">]</span> <span class="token punctuation">)</span> X_train <span class="token operator">=</span> data <span class="token punctuation">[</span> ix_train <span class="token punctuation">,</span> <span class="token punctuation">:</span> <span class="token punctuation">]</span> X_test <span class="token operator">=</span> data <span class="token punctuation">[</span> ix_test <span class="token punctuation">,</span> <span class="token punctuation">:</span> <span class="token punctuation">]</span> y_train <span class="token operator">=</span> target <span class="token punctuation">[</span> ix_train <span class="token punctuation">]</span> y_test <span class="token operator">=</span> target <span class="token punctuation">[</span> ix_test <span class="token punctuation">]</span> <span class="token keyword">return</span> X_train <span class="token punctuation">,</span> X_test <span class="token punctuation">,</span> y_train <span class="token punctuation">,</span> y_test |
Proceed to divide training and test data:
1 2 3 4 | trainX <span class="token operator">=</span> np <span class="token punctuation">.</span> array <span class="token punctuation">(</span> sentences <span class="token punctuation">)</span> trainy <span class="token operator">=</span> to_categorical <span class="token punctuation">(</span> np <span class="token punctuation">.</span> array <span class="token punctuation">(</span> labels <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> intents <span class="token punctuation">)</span> <span class="token punctuation">)</span> X_train <span class="token punctuation">,</span> X_test <span class="token punctuation">,</span> y_train <span class="token punctuation">,</span> y_test <span class="token operator">=</span> split_balanced <span class="token punctuation">(</span> trainX <span class="token punctuation">,</span> trainy <span class="token punctuation">,</span> test_size <span class="token operator">=</span> <span class="token number">0.2</span> <span class="token punctuation">)</span> |
Model definition
In this article, I use LSTM to conduct classification. LSTM network is used with keras in a quite simple way as follows
1 2 3 4 5 6 7 8 | <span class="token comment">#model A</span> model <span class="token operator">=</span> Sequential <span class="token punctuation">(</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> add <span class="token punctuation">(</span> LSTM <span class="token punctuation">(</span> <span class="token number">128</span> <span class="token punctuation">,</span> input_shape <span class="token operator">=</span> <span class="token punctuation">(</span> max_length_inp <span class="token punctuation">,</span> fast_text_model <span class="token punctuation">.</span> vector_size <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> add <span class="token punctuation">(</span> Dropout <span class="token punctuation">(</span> <span class="token number">0.2</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> add <span class="token punctuation">(</span> Dense <span class="token punctuation">(</span> <span class="token number">64</span> <span class="token punctuation">,</span> activation <span class="token operator">=</span> <span class="token string">'relu'</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> add <span class="token punctuation">(</span> Dense <span class="token punctuation">(</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> intents <span class="token punctuation">)</span> <span class="token punctuation">,</span> activation <span class="token operator">=</span> <span class="token string">'softmax'</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> <span class="token builtin">compile</span> <span class="token punctuation">(</span> loss <span class="token operator">=</span> <span class="token string">'categorical_crossentropy'</span> <span class="token punctuation">,</span> optimizer <span class="token operator">=</span> <span class="token string">'adam'</span> <span class="token punctuation">,</span> metrics <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token string">'accuracy'</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> |
See detailed number of model parameters:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= lstm_1 (LSTM) (None, 128) 142848 _________________________________________________________________ dropout (Dropout) (None, 128) 0 _________________________________________________________________ dense (Dense) (None, 64) 8256 _________________________________________________________________ dense_1 (Dense) (None, 10) 650 ================================================================= Total params: 151,754 Trainable params: 151,754 Non-trainable params: 0 |
Model training
To train the model we will fit the training and test data like this:
1 2 | model <span class="token punctuation">.</span> fit <span class="token punctuation">(</span> X_train <span class="token punctuation">,</span> y_train <span class="token punctuation">,</span> epochs <span class="token operator">=</span> <span class="token number">300</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> <span class="token number">20</span> <span class="token punctuation">,</span> verbose <span class="token operator">=</span> <span class="token number">1</span> <span class="token punctuation">,</span> validation_data <span class="token operator">=</span> <span class="token punctuation">(</span> X_test <span class="token punctuation">,</span> y_test <span class="token punctuation">)</span> <span class="token punctuation">,</span> callbacks <span class="token operator">=</span> <span class="token punctuation">[</span> tensorboard_callback <span class="token punctuation">]</span> <span class="token punctuation">)</span> |
The parameter verbose=1 specifies printing evaluation results after each epoch has been executed
The results after running some epochs are as follows:
1 2 3 4 5 6 7 8 9 10 11 12 | ..... Epoch 246/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0073 - accuracy: 0.9941 - val_loss: 1.7335 - val_accuracy: 0.8364 Epoch 247/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0119 - accuracy: 0.9915 - val_loss: 1.7414 - val_accuracy: 0.8295 Epoch 248/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0074 - accuracy: 0.9929 - val_loss: 1.7672 - val_accuracy: 0.8295 Epoch 249/300 87/87 [==============================] - 1s 13ms/step - loss: 0.0098 - accuracy: 0.9915 - val_loss: 1.7550 - val_accuracy: 0.8295 Epoch 250/300 87/87 [==============================] - 1s 14ms/step - loss: 0.0050 - accuracy: 0.9966 - val_loss: 1.7392 - val_accuracy: 0.8364 |
Model evaluation
Import the required libraries for evaluation:
1 2 3 4 5 6 7 8 9 | <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> accuracy_score <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> precision_score <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> recall_score <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> f1_score <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> cohen_kappa_score <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> roc_auc_score <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> confusion_matrix <span class="token keyword">from</span> sklearn <span class="token punctuation">.</span> metrics <span class="token keyword">import</span> multilabel_confusion_matrix |
We will evaluate the model based on metrics like f1_score, accuracy as follows:
The classification methods you can see here
- f1-score
1 2 3 4 5 | yhat_classes <span class="token operator">=</span> model <span class="token punctuation">.</span> predict_classes <span class="token punctuation">(</span> X_test <span class="token punctuation">,</span> verbose <span class="token operator">=</span> <span class="token number">0</span> <span class="token punctuation">)</span> y_test_true <span class="token operator">=</span> np <span class="token punctuation">.</span> array <span class="token punctuation">(</span> <span class="token punctuation">[</span> np <span class="token punctuation">.</span> where <span class="token punctuation">(</span> label <span class="token operator">==</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> label <span class="token keyword">in</span> y_test <span class="token punctuation">]</span> <span class="token punctuation">)</span> f1 <span class="token operator">=</span> f1_score <span class="token punctuation">(</span> yhat_classes <span class="token punctuation">,</span> y_test_true <span class="token punctuation">,</span> average <span class="token operator">=</span> <span class="token string">'weighted'</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> f1 <span class="token punctuation">)</span> |
The output will be:
1 2 | 0.8303684789128464 |
- Accuracy
1 2 3 4 | <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">"Evaluate on test data"</span> <span class="token punctuation">)</span> results <span class="token operator">=</span> model <span class="token punctuation">.</span> evaluate <span class="token punctuation">(</span> X_test <span class="token punctuation">,</span> y_test <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> <span class="token number">10</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token punctuation">(</span> <span class="token string">"test loss, test acc:"</span> <span class="token punctuation">,</span> results <span class="token punctuation">)</span> |
Result:
1 2 3 4 | Evaluate on test data 44/44 [==============================] - 0s 5ms/step - loss: 1.2874 - accuracy: 0.8272 test loss, test acc: [1.2874339818954468, 0.8271889686584473] |
Thus, the predicted results of the model on the test set reached 82.7%. The results are not very high, but acceptable.
Fine-tune model
To improve the accuracy of the model, readers can test the changes using better word representation model or use another model like BERT, GRU, RNN … Also we have can test change the parameters to and compare the changes to come up with the best model.
summary
In this article, I have just presented a technique to determine the intent of a question using deeplearning. Any questions and suggestions you can exchange under this article.
Link google colab of the article
Thank you for reading the article.