Working with API is definitely everyone has heard from API Rate Limiting. For example, with Github API then its Rate Limiting is as follows:
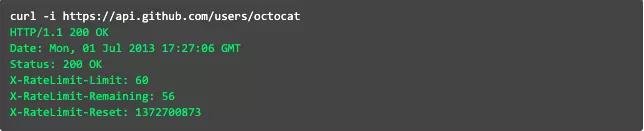
Looking at the image above can see its Rate Limiting 60 request / min. If you send more than 60 requests within 1 minute, you will not be able to send it again. You have to wait until the next minute to send it.
Currently most major systems in the world offer Rate Liming. But few people pay any attention to the technology behind it.
Today I write this article to guide people how to design Rate Limiting like.
Rate What is Limiting?
Suppose that our system receives thousands of requests, but only one of them can handle hundreds of requests / s, and the remaining requests are faulty (due to the overloaded CPU system cannot be processed). ).
To solve this problem, Rate Limiting mechanism was born. Its purpose only allows to receive a certain number of requests in 1 time unit. If too, it will return a response error.
Some common examples in Rate Limiting are:
- Each of our users only allows to send 100request / s. If exceeded, it will return a response error.
- Each user only allows the wrong credit card to be entered 3 times a day
- Each IP address can only create 2 accounts in 1 day.
Basically, rate limiter will allow to send as many requests in a certain time period. If exceeded, it will be blocked again.
Why does the API need to have Rate Limiting?
Rate Limiting will help us limit the following:
- DOS attack (Denial of Service) to the system
- Brute force password in the system (exhaust type scans)
- Brute force credit card information (scrabble type)
These attacks seem to come from real users, but they are actually created by bots. Therefore, it is very difficult to detect and easily cause our service to collapse.
In addition, Rate Limiting also gives us the following benefits:
- Security: Not allowed to enter the wrong password too many times
- Revenue: For each plan there will be different limit rates. If you want to use more, you need to buy a more expensive plan.
System requirements
Require function:
- Limit the number of requests sent in 1 time unit. Example 15 requests / s
Non-functional requirements:
- High load bearing system. Because rate limiter must always work to protect the system from external attacks.
- Rate limiting needs the lowest latency to help the user experience better.
Rate Limiting works like?
Rate Limiting has a process called Throttling used to control user API usage in a certain period of time.
When the limit is exceeded, it returns a response with HTTP Status as 429 – Too many requests.
Algorithm used in Rate Limiting
There are two types of good algorithms used to solve this problem:
Fixed Window algorithm
This algorithm will be calculated from the beginning of the unit of time to the end of the time unit.

For example, in the example above we can see, in the interval from zero to the first second, two requests are sent, that is m1 and m2.
There are 3 requests in the first second to the second second, m3, m4, m5.
If rate limiting is being set to 2 then in the example above, the m5 will be blocked.
Algorithm Sliding Window (Rolling Window)
In this algorithm, the time will be calculated from the time element that the request is made plus the length of the time window.
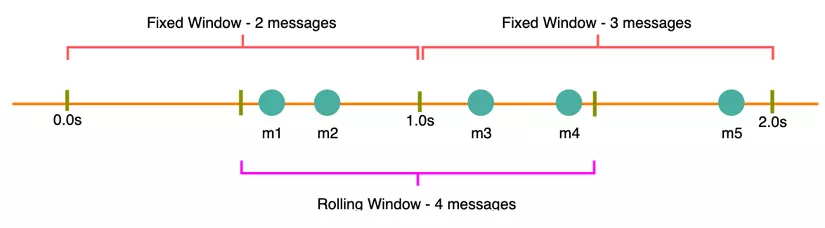
As in the example above, suppose that m1 and m2 are sent from seconds 0.3s. Then this 0.3s will start counting.
In the next 0.3s we see that the next 2 requests sent there are m3 and m4.
So in this period of 0.6s, there were 4 requests sent: m1, m2, m3, m4.
If Rate Limiting is set to 2, then m3 and m4 will be blocked again.
Suppose the time of sending m5 is 1.1s, for example. Then rate limiting will reset to zero. And repeat the process, and m5 will be counted as 1 time.
Architecture Rate Limiting
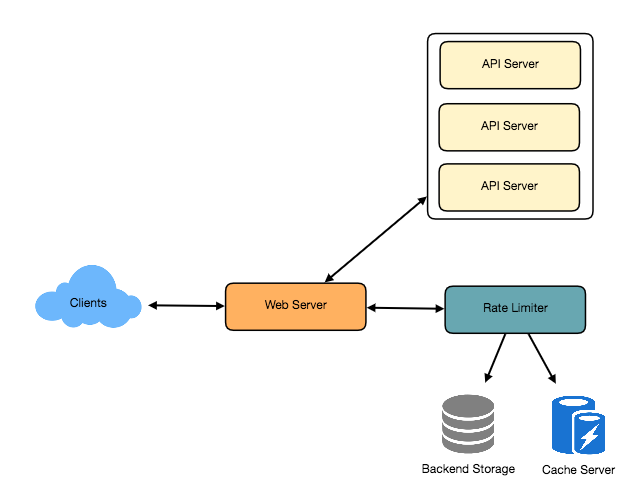
Rate Limiting will take care of deciding which requests will be sent to the API Server, which requests will be blocked.
Each time the Client sends a request to the Web Server, the Web Server will call Rate Limiter to check if this user has exceeded the Rate Limiting number. If not, then send that request to API Server. If it is already exceeded, it will block and return http status 429 (Too many requests).
Algorithm settings
1. Fixed Window algorithm
When the user sends a request to the system, we will save the number of requests sent to a count variable along with the start_time time of sending the request.
Then will save count vs timestamp into a hash table (May be Redis, memcached …). Where the key will be user_id and value will contain json including the number of requests sent, along with the timestamp.
Why should I use Redis without using mysql?
Using mysql to store data is a pretty bad idea. Because my read data in mysql will be much longer than using redis (memory).
For example, if we take 1ms to save 1 record to mysql, then 1s we will handle 1000 requests.
But with systems like Redis that don’t use disk but use memory to store, the read and write speed will be quite fast. For example, it takes 100 nanosec to save 1 record, then 1s will handle 10 million requests.
This Rate Limiting system needs to maximize the query speed to get count so Redis will be much more reasonable.
The structure of the data stored in the hash table will be as follows:
1 | user_id: {count, start_time} Ví dụ: 12: {3, 1560580210} 5: {2, 1560520442} |
Suppose as rate limiter will allow 3 request / min . Then the execution flow will be as follows:
- If user_id is not in the hash table, then insert user_id into the hash table along with the sending time (epoch time)
- If user_id is in the hash table, will it find the value corresponding to that user_id and calculate whether current_time – start_time> = 1 min?
- If it is larger then set start_time is equal to current_time and count = 1 and allow the request to be sent to API Server.
- If smaller, check if the count is greater than 3. If larger, it will block that request. If smaller, count = count + 1 and allow requests to be sent to API Server.
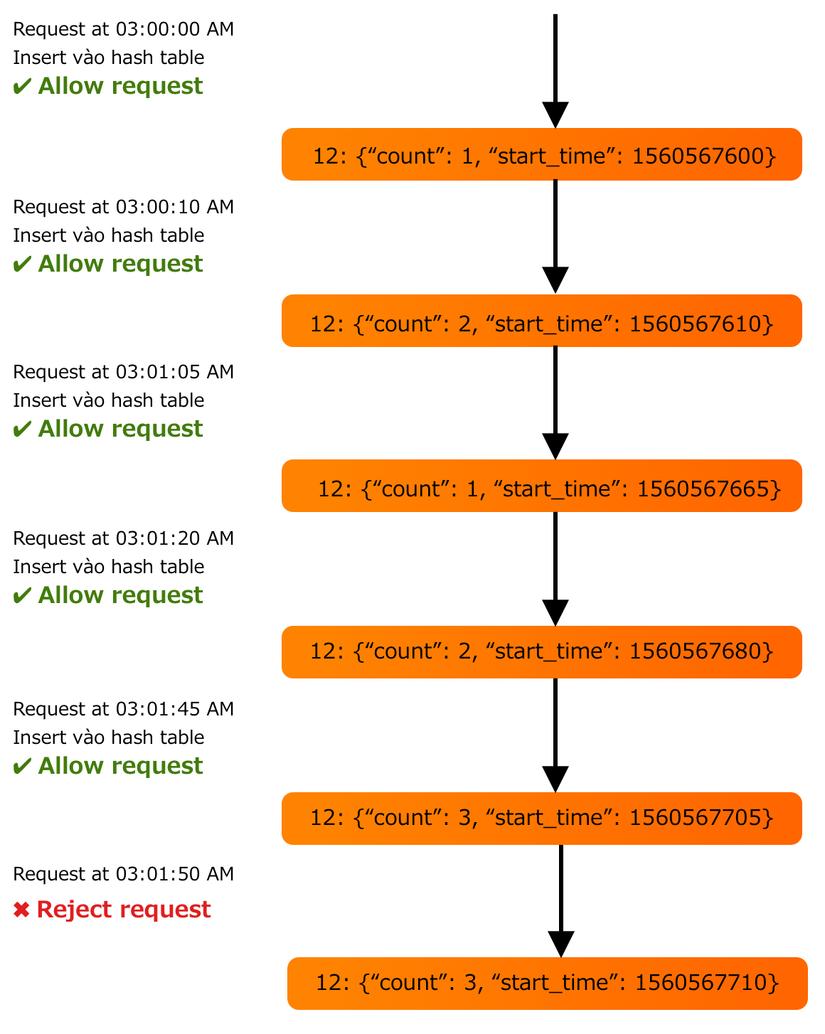
What is the problem with this algorithm?
Because count will be reset at the last moment of every minute. Therefore will lead to the status can send more than 3 request / min.
For example, at the second time 59.01 users send 3 requests. At this time count in the hash table is 0. While preparing the count count to the hash table, the user continues to send 10 more requests. At that time count can still be equal to 0 but not 3, so it bypasses this limiter rate easily.
Saying so, but it is very difficult to do it. Very fast operation and delay in milliseconds or nanoseconds only. Otherwise it will still be blocked.
To solve this problem, we can use Redis lock to lock count again before updating (ie, we have to update the new selection).
However, this may cause our logic to be slow when multiple requests are sent simultaneously from one user . Because when the select will lock the count of that user again. After the update count is finished, free the lock for the next request to use.
Note that this lock only locks the record of that user. Do not lock the record of another user. Or in other words just lock row, not lock the whole table.
How much memory is required to store all user data?
Because our hash table will be saved (user_id, count, start_time), we will need:
- 8 bytes for user_id
- 2 bytes for count (so the max value of count will be 2 ^ 16 = 65,536)
- 4 bytes for start_time (save as epoch time)
This will use a total of 8 + 2 + 4 = 14 bytes to store user data.
Suppose we need 20 bytes for the hash table overhead. Then with 1 million users will need:
(14 + 20) bytes * 1 million = 32.42 MB
Assuming we need 4 bytes to lock each user’s record to solve the above problem, we will need in total:
(14 + 20 + 4) bytes * 1 million = 36 MB
With rate limiting as 3 requests / min, it is possible to set redis on 1 server. However, if we increase the rate of limiting to 10 requests / s, then redis will suffer about 10 million requests / s. Then a redis will not be able to withstand the heat.
To solve this problem, we will use multiple distributed redis. When the update count goes into redis, the rate limiter will need to update all of those Redis.
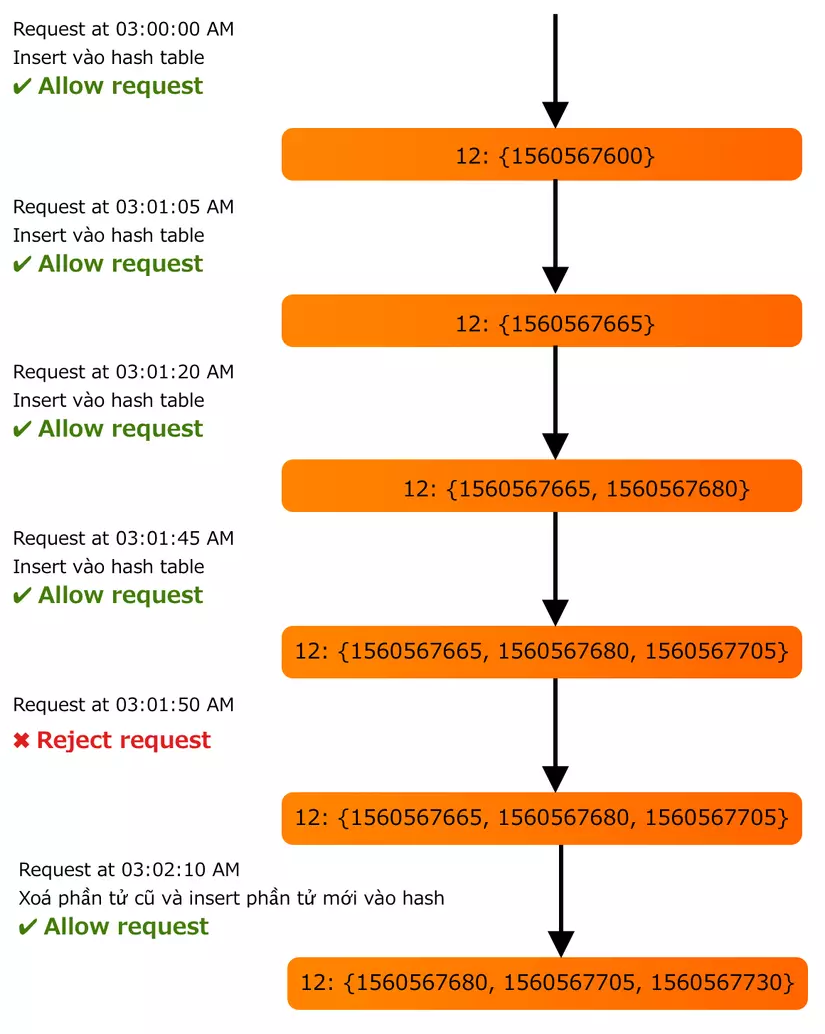
2. Algorithm Sliding Window
To do this algorithm, we need to save the time to send each request, instead of just storing the last sent value. And use Redis Sorted Set .
1 | user_id: {count, Sorted Set <start_time>} Ví dụ: 12: {1560580210, 1560580212, 1560580213} 5: {1560520442} |
Suppose like rate limiter allows to send 3 requests / min . Then flow will be as follows:
- Delete all start_time in Sorted Set with current_time – 1 min <0
- Calculate the total number of elements in Sorted Set. If this sum is> 3, it will block that request.
- Insert start_time into the Sorted Set and allow the request to be sent to API Server.
With this algorithm, how much memory is required to store data?
Our data structure will look like this:
1 | user_id: {start_time_1, start_time_2 ...., start_time_n} |
We will need 8 bytes to store user_id, 4 bytes to store epoch time.
Assuming the overhead of Sorted Set is 20 bytes, the overhead of the hash table is 20 bytes. Rate Limiting is 500 request / hour. Then we will need:
8 + (4 + 20 bytes Sorted Set overhead) * 500 + 20 bytes hash table overhead = 12KB
If we have 1 million users, when closing the total amount of memory required, it will be:
12 KB * 1 million = 12GB
Compared with Fixed Window algorithm, Sliding Window algorithm uses quite a lot of memory to store.
Conclude
Do you see the design of Rate Limiting for API? It is not too difficult, is it?
Hopefully, through this lesson, you will know how to design Rate Limiting, making your API more professional.
Source: https://nghethuatcoding.com/2019/06/15/thiet-ke-api-rate-limiting/
==============
To receive notifications when you have the latest posts, you can like my fanpage below:
→ xác nhận Facebook Fanpage Coding Art
I wish you a happy week.