1. What is Deep Learning
Artificial intelligence is creeping into life and far-reaching impact on each of us, the words “Artificial Intelligence”, “Machine Learing”, “Deep Learning” are no longer strange. Let us look at the figure to describe the relationship between artificial intelligence, machine learning, and deep learning:
Deep learning has been an exciting topic for AI. Is a small range of machine learning, deep learning focusing on solving problems related to artificial neural networks to upgrade technologies such as voice recognition, computer vision and natural language processing. Deep learning is becoming one of the hottest areas in computer science. In just a few years, deep learning has promoted progress in a wide range of areas such as object perception, machine translation, voice recognition, and so on – problems that have been very difficult. with artificial intelligence researchers.
To better understand deep learning, take a look at some of the basic concepts of artificial intelligence.
Artificial intelligence can be understood simply as being composed of stacked layers, in which the artificial neural network is at the bottom, machine learning is located on the next floor and deep learning is located on the top floor.
2. Introducing Keras
Deep Learning has been mentioned a lot in recent years, but the basic platform has been around for a long time
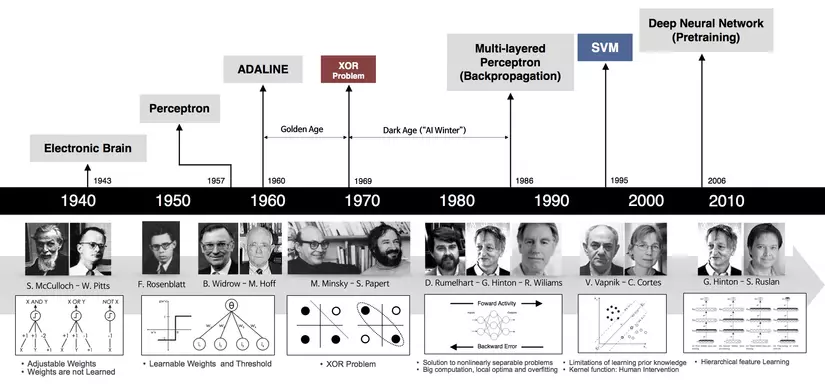
Has appeared since quite a long time but since 2012, deep learning has made big breakthroughs, a series of deep learning support libraries was born. Along with that, more and more deep learning architectures were born, causing the number of applications and articles related to deep learning to increase dramatically.
Deep learning libraries are often ‘backed up’ by large technology firms: Google (Keras, TensorFlow), Facebook (Caffe2, Pytorch), Microsoft (CNTK), Amazon (Mxnet), Microsoft and Amazon are also working on it. Build Gluon (version similar to Keras). (These companies all have cloud computing services and want to attract users).
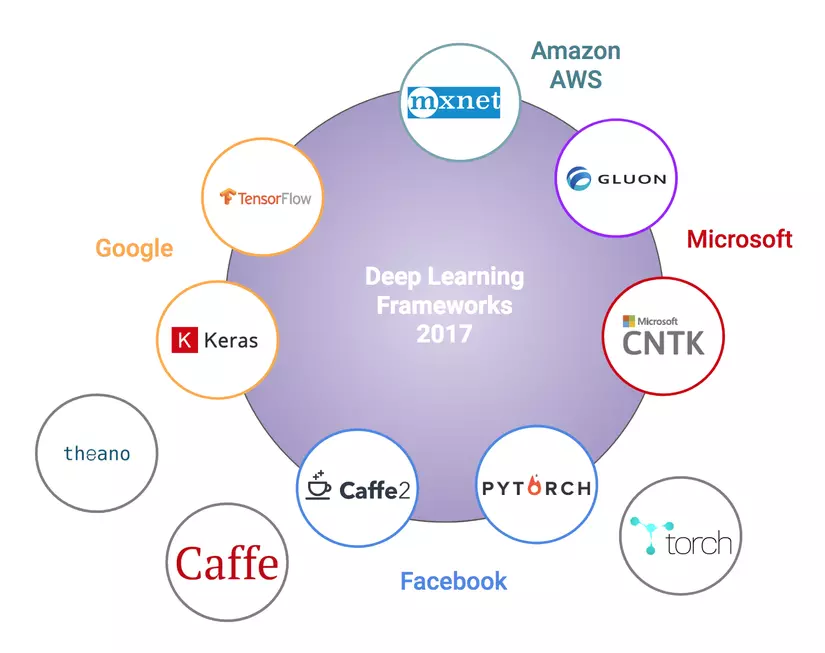
Here are a few statistics so people have an overview of the most used libraries
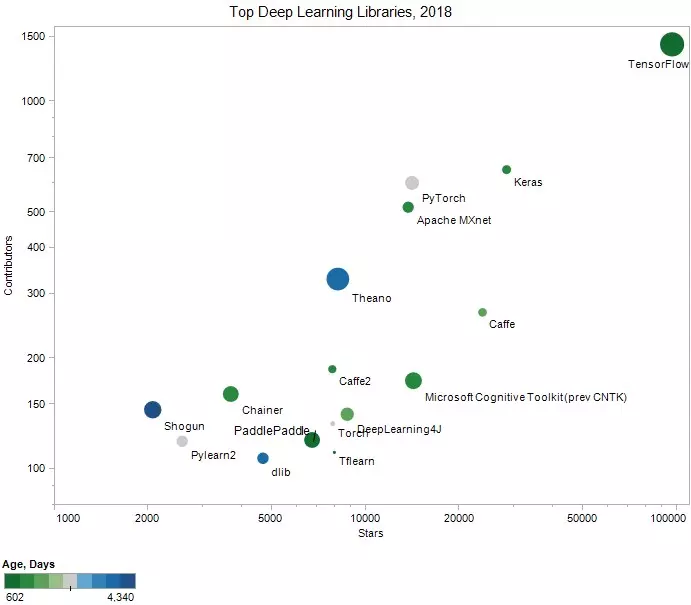
The number of “stars” on Github Repo, the number of “Contributors” of libraries
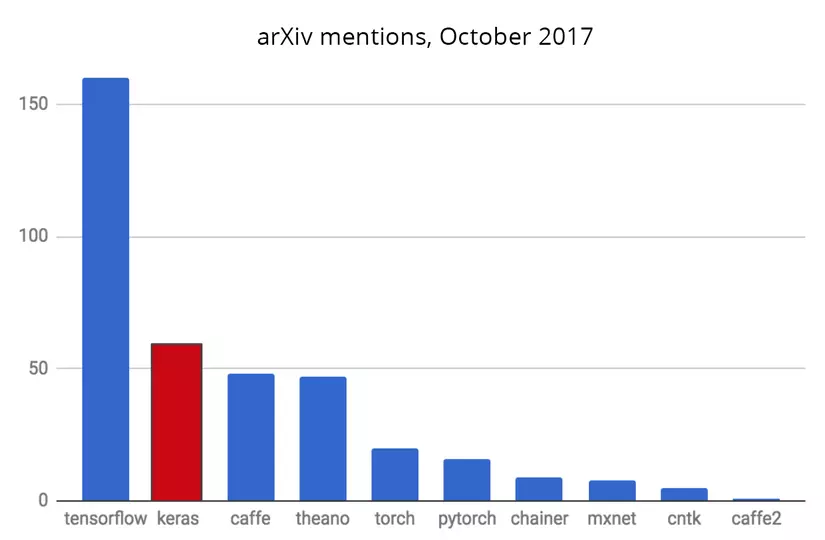
The number of articles on arXiv refers to each library
The above comparisons show that TensorFlow, Keras and Caffe are the most used libraries (more recently PyTorch is easy to use and is attracting more users).
Keras is considered a ‘high-level’ library with a ‘low-level’ (also called a backend) that can be TensorFlow, CNTK, or Theano. Keras has a much simpler syntax than TensorFlow. For the purpose of introducing more models than using deep learning libraries, I will choose Keras with TensorFlow as ‘backend’.
The reasons to use Keras to get started:
- Keras prioritizes the programmer’s experience
- Keras has been widely used in businesses and research communities
- Keras makes it easy to turn designs into products
- Keras supports training on multiple distributed GPUs
- Keras supports multi-backend engines and does not limit you to an ecosystem
3. Linear regression with Keras
Training a deep learning model or neural network in general involves the following steps:
- Prepare data
- Build the network
- Select experimental update algorithm, build loss and model evaluation method
- Training model.
- Review model
Let’s see Keras follow these steps through the example below.
Let’s do a simple example. Input X data has a dimension of 2, output y = 2 X [0] + 3 X [1] + 4 + e with e being a noise that follows an expected normal distribution of 0, a variance of 0.2 .
Here is the example code for training model linear regression by Keras:
1 | <span class="token keyword">import</span> numpy <span class="token keyword">as</span> np <span class="token keyword">from</span> keras <span class="token punctuation">.</span> models <span class="token keyword">import</span> Sequential <span class="token keyword">from</span> keras <span class="token punctuation">.</span> layers <span class="token punctuation">.</span> core <span class="token keyword">import</span> Dense <span class="token punctuation">,</span> Activation <span class="token keyword">from</span> keras <span class="token keyword">import</span> optimizers <span class="token comment"># 1. create pseudo data y = 2*x0 + 3*x1 + 4</span> X <span class="token operator">=</span> np <span class="token punctuation">.</span> random <span class="token punctuation">.</span> rand <span class="token punctuation">(</span> <span class="token number">100</span> <span class="token punctuation">,</span> <span class="token number">2</span> <span class="token punctuation">)</span> y <span class="token operator">=</span> <span class="token number">2</span> <span class="token operator">*</span> X <span class="token punctuation">[</span> <span class="token punctuation">:</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">3</span> <span class="token operator">*</span> X <span class="token punctuation">[</span> <span class="token punctuation">:</span> <span class="token punctuation">,</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token operator">+</span> <span class="token number">4</span> <span class="token operator">+</span> <span class="token number">.2</span> <span class="token operator">*</span> np <span class="token punctuation">.</span> random <span class="token punctuation">.</span> randn <span class="token punctuation">(</span> <span class="token number">100</span> <span class="token punctuation">)</span> <span class="token comment"># noise added</span> <span class="token comment"># 2. Build model</span> model <span class="token operator">=</span> Sequential <span class="token punctuation">(</span> <span class="token punctuation">[</span> Dense <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token punctuation">,</span> input_shape <span class="token operator">=</span> <span class="token punctuation">(</span> <span class="token number">2</span> <span class="token punctuation">,</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> activation <span class="token operator">=</span> <span class="token string">'linear'</span> <span class="token punctuation">)</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token comment"># 3. gradient descent optimizer and loss function</span> sgd <span class="token operator">=</span> optimizers <span class="token punctuation">.</span> SGD <span class="token punctuation">(</span> lr <span class="token operator">=</span> <span class="token number">0.1</span> <span class="token punctuation">)</span> model <span class="token punctuation">.</span> <span class="token builtin">compile</span> <span class="token punctuation">(</span> loss <span class="token operator">=</span> <span class="token string">'mse'</span> <span class="token punctuation">,</span> optimizer <span class="token operator">=</span> sgd <span class="token punctuation">)</span> <span class="token comment"># 4. Train the model</span> model <span class="token punctuation">.</span> fit <span class="token punctuation">(</span> X <span class="token punctuation">,</span> y <span class="token punctuation">,</span> epochs <span class="token operator">=</span> <span class="token number">100</span> <span class="token punctuation">,</span> batch_size <span class="token operator">=</span> <span class="token number">2</span> <span class="token punctuation">)</span> |
Result
1 | Epoch 1/100 100/100 [==============================] - 0s 5ms/step - loss: 1.7199 Epoch 2/100 100/100 [==============================] - 0s 709us/step - loss: 0.0388 Epoch 3/100 100/100 [==============================] - 0s 675us/step - loss: 0.0415 Epoch 4/100 100/100 [==============================] - 0s 774us/step - loss: 0.0392 Epoch 5/100 ..... Epoch 100/100 100/100 [==============================] - 0s 823us/step - loss: 0.0393 |
We see that the algorithm converges quite quickly and MSE loss is quite small after finishing training.
Explain some code:
# 2 create pseudo data
- Sequantial ([<a list>]) is a representation of how layers are built in the correct order in [<a list>]. The first element of the list shows the connection between the input layer and the next layer, the next elements of the list represent the connection of the next layer.
- Dense can show a fully connected layer, ie all previous layer units are connected to all units of the current layer. The first value in Dense equals 1 indicates that there is only 1 unit in this layer (output of linear regression in this case is 1). input_shape = (2,) is the size of the input data. This size is a tuple so we need to write in the form (2,). Later, when working with multidimensional data, we will have multidimensional tuples. For example, if the input is an RGB image with 224x224x3 pixels, input_shape = (224, 224, 3).
# 3 gradient descent optimizer and loss function
- Demonstrating the choice of experimental method, where we use Stochastic Gradient Descent (SGD) with learning rate lr = 0.1. Other update methods can be found at Keras-Usage of optimizers. loss = ‘mse’ is the mean squared error, which is the loss function of linear regression.
After building the model and showing the update method as well as the loss function, we train the model by: # 4
(Keras is quite similar to scikit-learn in that it trains models by the method of .fit ()). Here, epochs are epoch quantities and batch_size is the size of a mini-batch.
To see the coefficient of linear regression, we use:
1 | model <span class="token punctuation">.</span> get_weights <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
Result
1 | [array([[1.996118 ], [3.0239758]], dtype=float32), array([3.963116], dtype=float32)] |
where, the first element of this list is the find factor, the second element is the bias. This result is close to the expected solution of the problem (y = 2 X [0] + 3 X [1] + 4).
4. Conclusion
- Keras is a relatively easy-to-use library for beginners. It provides the necessary functions with simple syntax.
- When going deeper into deep learning in the following lessons, we will gradually become familiar with programming techniques with Keras. Invite you to read.