As we all know, captcha is annoying things like “Enter the letters you see on pictures” on the registration or feedback pages.
The CAPTCHA is designed so that humans can understand the text without difficulty, while the machine cannot. But in reality, this usually doesn’t work, because almost every simple text captcha posted on the website is cracked after a few months. Shortly after ReCaptcha v2 came out with much more complexity, but it can still be ignored in automatic mode.
While the struggle between captcha makers and captcha solvers seems to be endless, different people are interested in automatic captcha decoding to maintain the performance of their software. That is why in this specific article, I will show how to crack captcha text using OCR method.
All examples are written in Python 2.5 using the PIL library. It will also work in Python 2.6 and it has been successfully tested in Python 2.7.3.
Python: www.python.org
PIL: www.pythonware.com/products/pil
Install them in the order above and you are ready to run the examples.
Also, in the examples I will put multiple values directly in the code. I have no goal of creating a universal captcha identifier, the main goal is to show how this is done.
CAPTCHA: What is it really?
Primarily captcha is an example of a one-way conversion. You can easily grab a character set and get a captcha from it, but not the opposite. Another subtlety – it’s easy for humans to read, but unrecognizable by machines. CAPTCHA can be considered as a simple test like “Are you a human?” Basically, they are made in the form of an image with some symbols or words.
They are used to prevent spam on many websites. For example, captcha can be found on the registration page of Windows Live ID.
You will see an image and if you are a real person, you need to enter the text in the image into a separate field. It seems a good idea to protect against thousands of automated subscriptions to spam or distribute Viagra on forums, right? The problem is that AI, and especially image recognition methods, has undergone significant changes and is becoming very effective in certain areas. OCR (Optical Character Recognition) today is quite accurate and easily recognizes printed text. So, the captcha makers decided to add a bit of color and lines to the captcha to make the computer more difficult to solve, but without causing any further inconvenience for users. This is a kind of arms race and, as usual, one group appears to have stronger weapons for all defenses built by another. Defeating such a reinforced captcha is more difficult, but still possible. In addition, the image is still quite simple so as not to cause discomfort in ordinary people.
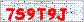
This image is an example of the actual captcha that we will decode. This is a real captcha posted on a real website.
It is a fairly simple captcha, consisting of characters of the same color and size on a white background with some noise (pixels, colors, lines). You may think that noise on this background will make it difficult to recognize, but I will show an easy way to remove it. Although this is not a very strong captcha, it is a good example for our program.
How to find and extract text from images
There are many methods to locate the text on an image and extract it. You can google and find thousands of articles explaining new methods and algorithms for locating text.
In this example I will use color extract. This is a fairly simple technique that I get pretty good results.
For our examples, I will use the multi-valued image decomposition algorithm. In essence, this means that we first draw the color chart of the image. This is done by taking all the pixels on the image grouped by color, and then counting is done for each group. If you look at our test captcha, you can see three main colors:
White (Background)
Gray (noise)
Red (text)
In Python, this would look very simple.
The following code will open the image, convert it into GIF (we are easier to work with because it has only 255 colors) and print a color chart:
1 2 3 4 5 6 7 | <span class="token keyword">from</span> PIL <span class="token keyword">import</span> Image im <span class="token operator">=</span> Image <span class="token punctuation">.</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> <span class="token string">"captcha.gif"</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> im <span class="token punctuation">.</span> histogram <span class="token punctuation">(</span> <span class="token punctuation">)</span> |
The result we get is as follows:
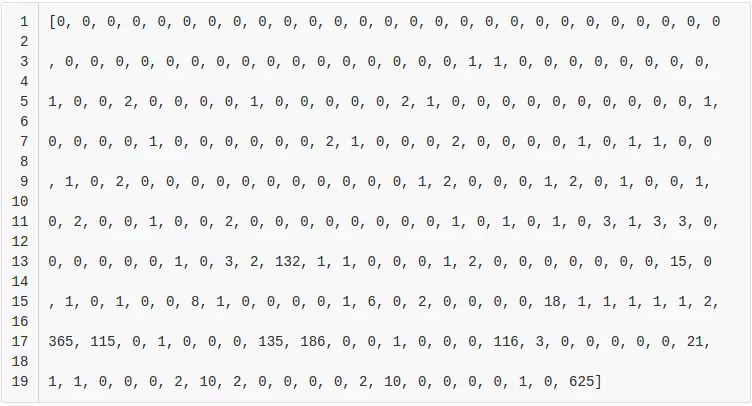
Here we see the number of pixels of each of the 255 colors on the image. You can see that white (255, last number) is found most often. It is followed by red (text). To verify this, we will write a small script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | <span class="token keyword">from</span> PIL <span class="token keyword">import</span> Image <span class="token keyword">from</span> operator <span class="token keyword">import</span> itemgetter im <span class="token operator">=</span> Image <span class="token punctuation">.</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> <span class="token string">"captcha.gif"</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> his <span class="token operator">=</span> im <span class="token punctuation">.</span> histogram <span class="token punctuation">(</span> <span class="token punctuation">)</span> values <span class="token operator">=</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> <span class="token number">256</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> values <span class="token punctuation">[</span> i <span class="token punctuation">]</span> <span class="token operator">=</span> his <span class="token punctuation">[</span> i <span class="token punctuation">]</span> <span class="token keyword">for</span> j <span class="token punctuation">,</span> k <span class="token keyword">in</span> <span class="token builtin">sorted</span> <span class="token punctuation">(</span> values <span class="token punctuation">.</span> items <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> key <span class="token operator">=</span> itemgetter <span class="token punctuation">(</span> <span class="token number">1</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> reverse <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token punctuation">[</span> <span class="token punctuation">:</span> <span class="token number">10</span> <span class="token punctuation">]</span> <span class="token punctuation">:</span> <span class="token keyword">print</span> j <span class="token punctuation">,</span> k |
And we get the following data:
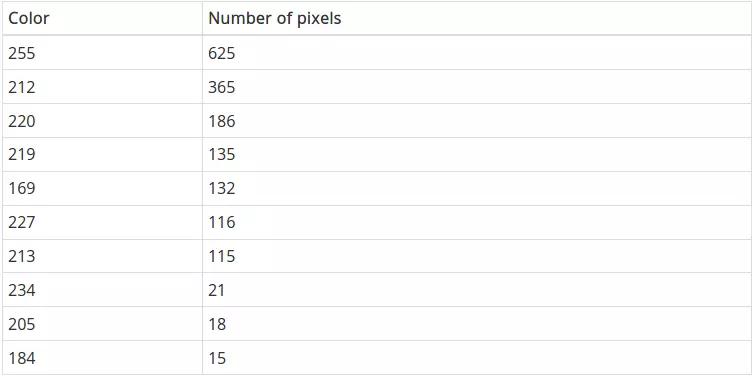
Here is a list of the 10 most common colors on photos. As expected, white repeats most often. Then comes gray and red.
When we receive this information, we create new images based on these color groups. For each of the most common colors, we create a new binary image (consisting of 2 colors), where the pixels of this color are filled with black and everything else is white.
Red has become the third of the most popular colors, meaning we want to save a group of pixels of color 220. When I experimented, I found that color 227 is quite close to 220, so we also will keep this group. The code below opens captcha, converts it into GIF, creates a new image the same size as the white background, and then goes through the original image to find the color we need. If he finds a pixel with the color we need, then he marks that pixel on the second image as black. Before turning off, the second image is saved.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <span class="token keyword">from</span> PIL <span class="token keyword">import</span> Image im <span class="token operator">=</span> Image <span class="token punctuation">.</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> <span class="token string">"captcha.gif"</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> im2 <span class="token operator">=</span> Image <span class="token punctuation">.</span> new <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">,</span> im <span class="token punctuation">.</span> size <span class="token punctuation">,</span> <span class="token number">255</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> temp <span class="token operator">=</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> y <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> pix <span class="token operator">=</span> im <span class="token punctuation">.</span> getpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> temp <span class="token punctuation">[</span> pix <span class="token punctuation">]</span> <span class="token operator">=</span> pix <span class="token keyword">if</span> pix <span class="token operator">==</span> 220or pix <span class="token operator">==</span> <span class="token number">227</span> <span class="token punctuation">:</span> _ <span class="token comment"># Đây là các màu được lấy_</span> im2 <span class="token punctuation">.</span> putpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">)</span> im2 <span class="token punctuation">.</span> save <span class="token punctuation">(</span> <span class="token string">"output.gif"</span> <span class="token punctuation">)</span> |
Running the above code gives us the following result.

On the image you can see that we can extract text from the background. To automate this process, you can combine the first and second scripts.
I heard you ask: “What if the text on the captcha is written in different colors?”. Yes, our technology can still work. Suppose the most common color is the background color and then you can find the color of the characters.
So at this point, we have successfully extracted text from images. The next step is to determine if the image contains text. I will not write code here, because it will make understanding difficult, while the algorithm itself is quite simple.
1 2 3 4 5 6 7 8 | <span class="token keyword">for</span> each binary image <span class="token punctuation">:</span> <span class="token keyword">for</span> each pixel <span class="token keyword">in</span> the binary image <span class="token punctuation">:</span> <span class="token keyword">if</span> the pixel <span class="token keyword">is</span> on <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token builtin">any</span> pixel we have seen before <span class="token keyword">is</span> <span class="token builtin">next</span> to it <span class="token punctuation">:</span> add to the same <span class="token builtin">set</span> <span class="token keyword">else</span> <span class="token punctuation">:</span> add to a new <span class="token builtin">set</span> |
At the output, you will have a set of character boundaries. Then all you need to do is compare them and see if they go in order. If yes, then it is a jackpot because you have correctly identified the next character. You can also check the size of the area received or simply create a new image and display it (apply show () method for image) to ensure the correct algorithm.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | <span class="token keyword">from</span> PIL <span class="token keyword">import</span> Image im <span class="token operator">=</span> Image <span class="token punctuation">.</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> <span class="token string">"captcha.gif"</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> im2 <span class="token operator">=</span> Image <span class="token punctuation">.</span> new <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">,</span> im <span class="token punctuation">.</span> size <span class="token punctuation">,</span> <span class="token number">255</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> temp <span class="token operator">=</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> y <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> pix <span class="token operator">=</span> im <span class="token punctuation">.</span> getpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> temp <span class="token punctuation">[</span> pix <span class="token punctuation">]</span> <span class="token operator">=</span> pix <span class="token keyword">if</span> pix <span class="token operator">==</span> 220or pix <span class="token operator">==</span> <span class="token number">227</span> <span class="token punctuation">:</span> <span class="token comment"># these are the numbers to get_</span> im2 <span class="token punctuation">.</span> putpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">)</span> <span class="token comment"># new code starts here_</span> inletter <span class="token operator">=</span> <span class="token boolean">False</span> foundletter <span class="token operator">=</span> <span class="token boolean">False</span> start <span class="token operator">=</span> <span class="token number">0</span> end <span class="token operator">=</span> <span class="token number">0</span> letters <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> y <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im2 <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> _ <span class="token comment"># slice across_</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im2 <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> _ <span class="token comment"># slice down_</span> pix <span class="token operator">=</span> im2 <span class="token punctuation">.</span> getpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">if</span> pix <span class="token operator">!=</span> <span class="token number">255</span> <span class="token punctuation">:</span> inletter <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token keyword">if</span> foundletter <span class="token operator">==</span> Falseand inletter <span class="token operator">==</span> <span class="token boolean">True</span> <span class="token punctuation">:</span> foundletter <span class="token operator">=</span> <span class="token boolean">True</span> start <span class="token operator">=</span> y <span class="token keyword">if</span> foundletter <span class="token operator">==</span> Trueand inletter <span class="token operator">==</span> <span class="token boolean">False</span> <span class="token punctuation">:</span> foundletter <span class="token operator">=</span> <span class="token boolean">False</span> end <span class="token operator">=</span> y letters <span class="token punctuation">.</span> append <span class="token punctuation">(</span> <span class="token punctuation">(</span> start <span class="token punctuation">,</span> end <span class="token punctuation">)</span> <span class="token punctuation">)</span> inletter <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token keyword">print</span> letters |
The result we have received is as follows:
[(6, 14), (15, 25), (27, 35), (37, 46), (48, 56), (57, 67)]
These are the horizontal positions of the beginning and end of each character.
AI and vector for pattern recognition
Image recognition can be considered the greatest success of modern AI, allowing it to be embedded in all types of commercial applications. A great example of this is zip code. In fact, in many countries, they are automatically read, because teaching computers to recognize numbers is a fairly simple task. This may not be obvious, but pattern recognition is considered to be an AI issue, a highly specialized issue is the other.
Almost the first algorithm you encounter when encountering a pattern recognition AI is the neural network. Personally, I have never been successful with the neural network in character recognition. I usually teach it 3-4 characters, then the accuracy drops so low that it will be higher then randomly guess the characters. Luckily, I read an article about vector space search engines and found an alternative method for data classification. In the end, it turned out this was the best option, because:
- 12Nó không yêu cầu nghiên cứu sâu rộng.
- 12Bạn có thể thêm / xóa dữ liệu không chính xác và thấy ngay kết quả
- 12Nó dễ hiểu và dễ lập trình hơn.
- 12Nó cung cấp kết quả được phân loại để bạn có thể xem các kết quả chính xác hàng đầu.
- 12Không thể nhận ra một cái gì đó? Thêm cái này và bạn sẽ có thể nhận ra nó ngay lập tức, ngay cả khi nó hoàn toàn khác với thứ được nhìn thấy trước đó.
Of course, there is no free cheese. The main drawback about speed. They can be much slower than the neural network. But I think their advantages still outweigh this drawback.
If you want to understand how vector space works, then I recommend reading Vector Space Search Engine Theory. This is the best thing I find for beginners and I have built my image identity based on this document. Now we have to program our vector space. Fortunately, this is not difficult. Start.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <span class="token keyword">import</span> math <span class="token keyword">class</span> <span class="token class-name">VectorCompare</span> <span class="token punctuation">:</span> <span class="token keyword">def</span> <span class="token function">magnitude</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> concordance <span class="token punctuation">)</span> <span class="token punctuation">:</span> total <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> word <span class="token punctuation">,</span> count <span class="token keyword">in</span> concordance <span class="token punctuation">.</span> iteritems <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> total <span class="token operator">+=</span> count <span class="token operator">*</span> <span class="token operator">*</span> <span class="token number">2</span> <span class="token keyword">return</span> math <span class="token punctuation">.</span> sqrt <span class="token punctuation">(</span> total <span class="token punctuation">)</span> <span class="token keyword">def</span> <span class="token function">relation</span> <span class="token punctuation">(</span> self <span class="token punctuation">,</span> concordance1 <span class="token punctuation">,</span> concordance2 <span class="token punctuation">)</span> <span class="token punctuation">:</span> relevance <span class="token operator">=</span> <span class="token number">0</span> topvalue <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> word <span class="token punctuation">,</span> count <span class="token keyword">in</span> concordance1 <span class="token punctuation">.</span> iteritems <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> concordance2 <span class="token punctuation">.</span> has_key <span class="token punctuation">(</span> word <span class="token punctuation">)</span> <span class="token punctuation">:</span> topvalue <span class="token operator">+=</span> count <span class="token operator">*</span> concordance2 <span class="token punctuation">[</span> word <span class="token punctuation">]</span> <span class="token keyword">return</span> topvalue <span class="token operator">/</span> <span class="token punctuation">(</span> self <span class="token punctuation">.</span> magnitude <span class="token punctuation">(</span> concordance1 <span class="token punctuation">)</span> <span class="token operator">*</span> self <span class="token punctuation">.</span> magnitude <span class="token punctuation">(</span> concordance2 <span class="token punctuation">)</span> <span class="token punctuation">)</span> |
This is a vector space implementation of Python in 15 lines. Basically, it only uses 2 dictionaries and returns a number between 0 and 1, indicating how they are connected. 0 means they are not connected and 1 means they are identical.
Educate
The next thing we need is a set of images that we will compare our characters. We need a learning kit. This set can be used to train any type of AI we will use (neural networks, etc.).
The data used can be critical for the success of an accreditation. The better the data, the greater the chance of success. Since we intended to recognize a specific captcha and were able to extract symbols from it, why not use them as training?
This is what I did. I have downloaded a lot of captcha created and my program has divided them into letters. Then I collect the pictures received in a gallery (group). After many attempts, I had at least one example of each character created by the captcha. Adding more examples will increase identification accuracy, but this is enough for me to confirm my theory.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | <span class="token keyword">from</span> PIL <span class="token keyword">import</span> Image <span class="token keyword">import</span> hashlib <span class="token keyword">import</span> time im <span class="token operator">=</span> Image <span class="token punctuation">.</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> <span class="token string">"captcha.gif"</span> <span class="token punctuation">)</span> im2 <span class="token operator">=</span> Image <span class="token punctuation">.</span> new <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">,</span> im <span class="token punctuation">.</span> size <span class="token punctuation">,</span> <span class="token number">255</span> <span class="token punctuation">)</span> im <span class="token operator">=</span> im <span class="token punctuation">.</span> convert <span class="token punctuation">(</span> <span class="token string">"P"</span> <span class="token punctuation">)</span> temp <span class="token operator">=</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> <span class="token keyword">print</span> im <span class="token punctuation">.</span> histogram <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">for</span> y <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> pix <span class="token operator">=</span> im <span class="token punctuation">.</span> getpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> temp <span class="token punctuation">[</span> pix <span class="token punctuation">]</span> <span class="token operator">=</span> pix <span class="token keyword">if</span> pix <span class="token operator">==</span> 220or pix <span class="token operator">==</span> <span class="token number">227</span> <span class="token punctuation">:</span> <span class="token comment"># these are the numbers to get</span> im2 <span class="token punctuation">.</span> putpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">)</span> inletter <span class="token operator">=</span> <span class="token boolean">False</span> foundletter <span class="token operator">=</span> <span class="token boolean">False</span> start <span class="token operator">=</span> <span class="token number">0</span> end <span class="token operator">=</span> <span class="token number">0</span> letters <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> y <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im2 <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> _ <span class="token comment"># slice across_</span> <span class="token keyword">for</span> x <span class="token keyword">in</span> <span class="token builtin">range</span> <span class="token punctuation">(</span> im2 <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> _ <span class="token comment"># slice down_</span> pix <span class="token operator">=</span> im2 <span class="token punctuation">.</span> getpixel <span class="token punctuation">(</span> <span class="token punctuation">(</span> y <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token keyword">if</span> pix <span class="token operator">!=</span> <span class="token number">255</span> <span class="token punctuation">:</span> inletter <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token keyword">if</span> foundletter <span class="token operator">==</span> Falseand inletter <span class="token operator">==</span> <span class="token boolean">True</span> <span class="token punctuation">:</span> foundletter <span class="token operator">=</span> <span class="token boolean">True</span> start <span class="token operator">=</span> y <span class="token keyword">if</span> foundletter <span class="token operator">==</span> Trueand inletter <span class="token operator">==</span> <span class="token boolean">False</span> <span class="token punctuation">:</span> foundletter <span class="token operator">=</span> <span class="token boolean">False</span> end <span class="token operator">=</span> y letters <span class="token punctuation">.</span> append <span class="token punctuation">(</span> <span class="token punctuation">(</span> start <span class="token punctuation">,</span> end <span class="token punctuation">)</span> <span class="token punctuation">)</span> inletter <span class="token operator">=</span> <span class="token boolean">False</span> <span class="token comment"># New code is here. We just extract each image and save it to disk with</span> <span class="token comment"># what is hopefully a unique name</span> count <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> letter <span class="token keyword">in</span> letters <span class="token punctuation">:</span> m <span class="token operator">=</span> hashlib <span class="token punctuation">.</span> md5 <span class="token punctuation">(</span> <span class="token punctuation">)</span> im3 <span class="token operator">=</span> im2 <span class="token punctuation">.</span> crop <span class="token punctuation">(</span> <span class="token punctuation">(</span> letter <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> letter <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> im2 <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> m <span class="token punctuation">.</span> update <span class="token punctuation">(</span> <span class="token string">"%s%s"</span> <span class="token operator">%</span> <span class="token punctuation">(</span> time <span class="token punctuation">.</span> time <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> count <span class="token punctuation">)</span> <span class="token punctuation">)</span> im3 <span class="token punctuation">.</span> save <span class="token punctuation">(</span> <span class="token string">"./%s.gif"</span> <span class="token operator">%</span> <span class="token punctuation">(</span> m <span class="token punctuation">.</span> hexdigest <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> count <span class="token operator">+=</span> <span class="token number">1</span> |
At the output, we get a set of images in the same folder. Each of them is assigned a unique hash function in case you process some captcha.
Here is the result of this code for our test captcha:

You decide how to store these images, but I just put them in a folder with the same name on the images (symbols or numbers).
Putting them all together
Last step. We have text extraction, character extraction, identification techniques and training.
We get an image of the captcha, select the text, accept the characters and then compare them with our training data. You can download the final program with a training kit and a small number of captcha at this link .
Here we just need to download the training file to be able to compare our captcha with it:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | <span class="token keyword">def</span> <span class="token function">buildvector</span> <span class="token punctuation">(</span> im <span class="token punctuation">)</span> <span class="token punctuation">:</span> d1 <span class="token operator">=</span> <span class="token punctuation">{</span> <span class="token punctuation">}</span> count <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> i <span class="token keyword">in</span> im <span class="token punctuation">.</span> getdata <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> d1 <span class="token punctuation">[</span> count <span class="token punctuation">]</span> <span class="token operator">=</span> i count <span class="token operator">+=</span> <span class="token number">1</span> <span class="token keyword">return</span> d1 v <span class="token operator">=</span> VectorCompare <span class="token punctuation">(</span> <span class="token punctuation">)</span> iconset <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token string">'0'</span> <span class="token punctuation">,</span> <span class="token string">'1'</span> <span class="token punctuation">,</span> <span class="token string">'2'</span> <span class="token punctuation">,</span> <span class="token string">'3'</span> <span class="token punctuation">,</span> <span class="token string">'4'</span> <span class="token punctuation">,</span> <span class="token string">'5'</span> <span class="token punctuation">,</span> <span class="token string">'6'</span> <span class="token punctuation">,</span> <span class="token string">'7'</span> <span class="token punctuation">,</span> <span class="token string">'8'</span> <span class="token punctuation">,</span> <span class="token string">'9'</span> <span class="token punctuation">,</span> <span class="token string">'0'</span> <span class="token punctuation">,</span> <span class="token string">'a'</span> <span class="token punctuation">,</span> <span class="token string">'b'</span> <span class="token punctuation">,</span> <span class="token string">'c'</span> <span class="token punctuation">,</span> <span class="token string">'d'</span> <span class="token punctuation">,</span> <span class="token string">'e'</span> <span class="token punctuation">,</span> <span class="token string">'f'</span> <span class="token punctuation">,</span> <span class="token string">'g'</span> <span class="token punctuation">,</span> <span class="token string">'h'</span> <span class="token punctuation">,</span> <span class="token string">'i'</span> <span class="token punctuation">,</span> <span class="token string">'j'</span> <span class="token punctuation">,</span> <span class="token string">'k'</span> <span class="token punctuation">,</span> <span class="token string">'l'</span> <span class="token punctuation">,</span> <span class="token string">'m'</span> <span class="token punctuation">,</span> <span class="token string">'n'</span> <span class="token punctuation">,</span> <span class="token string">'o'</span> <span class="token punctuation">,</span> <span class="token string">'p'</span> <span class="token punctuation">,</span> <span class="token string">'q'</span> <span class="token punctuation">,</span> <span class="token string">'r'</span> <span class="token punctuation">,</span> <span class="token string">'s'</span> <span class="token punctuation">,</span> <span class="token string">'t'</span> <span class="token punctuation">,</span> <span class="token string">'u'</span> <span class="token punctuation">,</span> <span class="token string">'v'</span> <span class="token punctuation">,</span> <span class="token string">'w'</span> <span class="token punctuation">,</span> <span class="token string">'x'</span> <span class="token punctuation">,</span> <span class="token string">'y'</span> <span class="token punctuation">,</span> <span class="token string">'z'</span> <span class="token punctuation">]</span> imageset <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> letter <span class="token keyword">in</span> iconset <span class="token punctuation">:</span> <span class="token keyword">for</span> img <span class="token keyword">in</span> os <span class="token punctuation">.</span> listdir <span class="token punctuation">(</span> <span class="token string">'./iconset/%s/'</span> <span class="token operator">%</span> <span class="token punctuation">(</span> letter <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> temp <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">if</span> img <span class="token operator">!=</span> <span class="token string">"Thumbs.db"</span> <span class="token punctuation">:</span> temp <span class="token punctuation">.</span> append <span class="token punctuation">(</span> buildvector <span class="token punctuation">(</span> Image <span class="token punctuation">.</span> <span class="token builtin">open</span> <span class="token punctuation">(</span> <span class="token string">"./iconset/%s/%s"</span> <span class="token operator">%</span> <span class="token punctuation">(</span> letter <span class="token punctuation">,</span> img <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> imageset <span class="token punctuation">.</span> append <span class="token punctuation">(</span> <span class="token punctuation">{</span> letter <span class="token punctuation">:</span> temp <span class="token punctuation">}</span> <span class="token punctuation">)</span> |
And then all the magic happens. We determine the position of each character and test it with our vector space. We then sort the results and print them.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | count <span class="token operator">=</span> <span class="token number">0</span> <span class="token keyword">for</span> letter <span class="token keyword">in</span> letters <span class="token punctuation">:</span> m <span class="token operator">=</span> hashlib <span class="token punctuation">.</span> md5 <span class="token punctuation">(</span> <span class="token punctuation">)</span> im3 <span class="token operator">=</span> im2 <span class="token punctuation">.</span> crop <span class="token punctuation">(</span> <span class="token punctuation">(</span> letter <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> <span class="token number">0</span> <span class="token punctuation">,</span> letter <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> im2 <span class="token punctuation">.</span> size <span class="token punctuation">[</span> <span class="token number">1</span> <span class="token punctuation">]</span> <span class="token punctuation">)</span> <span class="token punctuation">)</span> guess <span class="token operator">=</span> <span class="token punctuation">[</span> <span class="token punctuation">]</span> <span class="token keyword">for</span> image <span class="token keyword">in</span> imageset <span class="token punctuation">:</span> <span class="token keyword">for</span> x <span class="token punctuation">,</span> y <span class="token keyword">in</span> image <span class="token punctuation">.</span> iteritems <span class="token punctuation">(</span> <span class="token punctuation">)</span> <span class="token punctuation">:</span> <span class="token keyword">if</span> <span class="token builtin">len</span> <span class="token punctuation">(</span> y <span class="token punctuation">)</span> <span class="token operator">!=</span> <span class="token number">0</span> <span class="token punctuation">:</span> guess <span class="token punctuation">.</span> append <span class="token punctuation">(</span> <span class="token punctuation">(</span> v <span class="token punctuation">.</span> relation <span class="token punctuation">(</span> y <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> <span class="token punctuation">,</span> buildvector <span class="token punctuation">(</span> im3 <span class="token punctuation">)</span> <span class="token punctuation">)</span> <span class="token punctuation">,</span> x <span class="token punctuation">)</span> <span class="token punctuation">)</span> guess <span class="token punctuation">.</span> sort <span class="token punctuation">(</span> reverse <span class="token operator">=</span> <span class="token boolean">True</span> <span class="token punctuation">)</span> <span class="token keyword">print</span> <span class="token string">""</span> <span class="token punctuation">,</span> guess <span class="token punctuation">[</span> <span class="token number">0</span> <span class="token punctuation">]</span> count <span class="token operator">+=</span> <span class="token number">1</span> |
Conclusion on the simple captcha solution
Now we have everything we need and we can try booting up our machine.
The input file is captcha.gif. Expected result: 7s9t9j
1 2 3 4 5 6 7 8 | python crack <span class="token punctuation">.</span> py <span class="token punctuation">(</span> <span class="token number">0.96376811594202894</span> <span class="token punctuation">,</span> <span class="token string">'7'</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> <span class="token number">0.96234028545977002</span> <span class="token punctuation">,</span> <span class="token string">'s'</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> <span class="token number">0.9286884286888929</span> <span class="token punctuation">,</span> <span class="token string">'9'</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> <span class="token number">0.98350370609844473</span> <span class="token punctuation">,</span> <span class="token string">'t'</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> <span class="token number">0.96751165072506273</span> <span class="token punctuation">,</span> <span class="token string">'9'</span> <span class="token punctuation">)</span> <span class="token punctuation">(</span> <span class="token number">0.96989711688772628</span> <span class="token punctuation">,</span> <span class="token string">'j'</span> <span class="token punctuation">)</span> |
Here we can see the exact symbol and its reliability (from 0 to 1).
So it looks like we really succeeded!
In fact, in captchas testing, this scenario will produce successful results in only about 22% of cases.
1 2 3 4 5 6 | python crack_test <span class="token punctuation">.</span> py Correct Guesses <span class="token operator">-</span> <span class="token number">11.0</span> Wrong Guesses <span class="token operator">-</span> <span class="token number">37.0</span> Percentage Correct <span class="token operator">-</span> <span class="token number">22.9166666667</span> Percentage Wrong <span class="token operator">-</span> <span class="token number">77.0833333333</span> |
Most inaccurate results are related to incorrect identification of the digits “0” and the letter “O”, which is not really surprising, since even people often confuse them. Also, we still have a problem with separating captcha into characters, but this can be solved simply by checking the result of the break and finding a middle point.
However, even with such an imperfect algorithm, we can correctly solve every fifth captcha and it will be faster than one can actually solve one.
Running this code on Core 2 Duo E6550 produces the following result:
- real 0m5.750s
- user 0m0.015s
- sys 0m0.000s
With a success rate of 22%, we are able to solve around 432,000 captcha every day and get 95,040 accurate results. Imagine how we use multithreading.