Source: Edureka
In part 1, we covered 4 topics:
- Why Is Python Best For AI?
- Demand For AI
- What Is Artificial Intelligence?
- Types Of Artificial Intelligence
Continuing in this section, we will explore the following topics:
- Machine Learning Basics
- Types Of Machine Learning
- Types Of Problems Solved By Using Machine Learning
- Machine Learning Process
5. Machine Learning Basics
The term Machine Learning was first coined by Arthur Samuel in 1959. Looking back, that year was probably the most important year in terms of technological progress.
Put simply,
Machine learning is a subset of Artificial Intelligence (AI) which provides machines the ability to learn automatically by feeding it tons of data & allowing it to improve through experience. Thus, Machine Learning is a practice of getting Machines to solve problems by gaining the ability to think. (Machine Learning (ML) is a subset of Artificial Intelligence (AI) that gives the machine the ability to automatically learn by giving it tons of data and allowing it to improve through experience. ML is a method that helps machines solve problems by gaining the ability to think.)
But how can a machine make a decision?
If you give your machine a good amount of data, it will learn how to interpret, process and analyze this data using Machine Learning Algorithms.
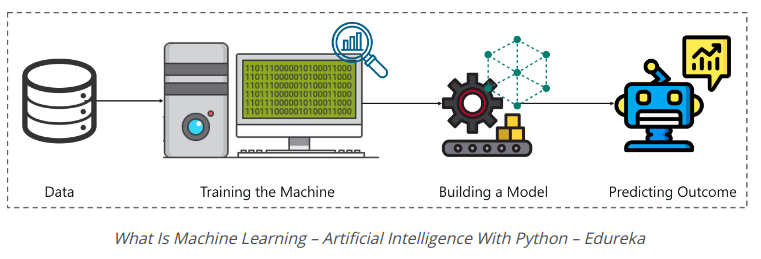
To summarize, see the image above:
- A Machine Learning process begins by providing the machine with a lot of data.
- The machine is then trained on this data, to detect insights and hidden patterns.
- These insights are used to build the Machine Learning Model using algorithms to solve problems.
Now that we know what Machine Learning is, let’s look at the different ways that machine can learn.
6. Types Of Machine Learning
A machine can learn to solve problems by following any of the three approaches:
- Supervised Learning (Supervised Learning)
- Unsupervised Learning (Unattended Learning)
- Reinforcement Learning (Reinforcement Learning)
6.1. Supervised Learning
Supervised learning is a technique in which we teach or train the machine using data which is well labeled. (Supervised learning is a technique in which we teach or train machines that use well-labeled data.)
To understand Supervised Learning, let Let’s consider an analogy. We all need guidance when we are young to solve problems. Our teachers have helped us understand what supplement is and how it is done.
Similarly, you can think of Supervised Learning as a kind of Machine Learning related to instruction. The dataset is labeled as a teacher will train you to understand the patterns in the data. The labeled data set is nothing but training data set.
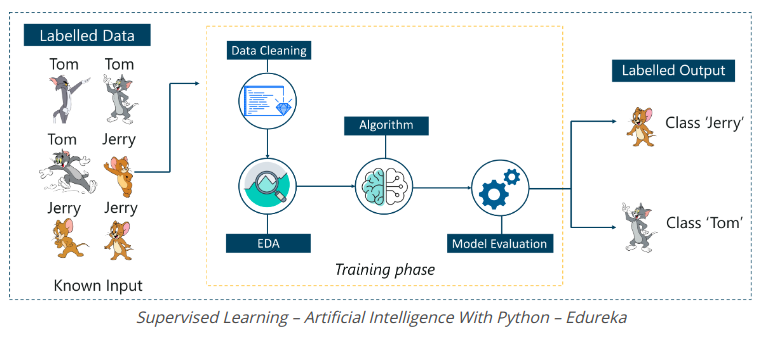
Consider the picture above. Here we give the image of Tom and Jerry and the goal is for the machine to identify and classify images into two groups (Tom images and Jerry images).
The training dataset is provided for the labeled model, as inside, we say to the machine, ‘this is Tom’s interface and this is Jerry’. That way, you can train the machine by using labeled data. In Supervised Learning, there is a clearly defined training phase performed with the help of labeled data.
6.2. Unsupervised Learning
Unsupervised learning involves training by using unlabeled data and allowing the model to act on that information without guidance. (Unattended learning includes training using unlabeled data and allowing the model to act on that information without guidance.)
Think of Unsupervised Learning as a smart child learning without any guidance. In this type of Machine Learning, the model does not provide labeled data, because in the model there is no clue that “this image is Tom and this is Jerry”, it finds the models and the The difference between Tom and Jerry in tons of data.
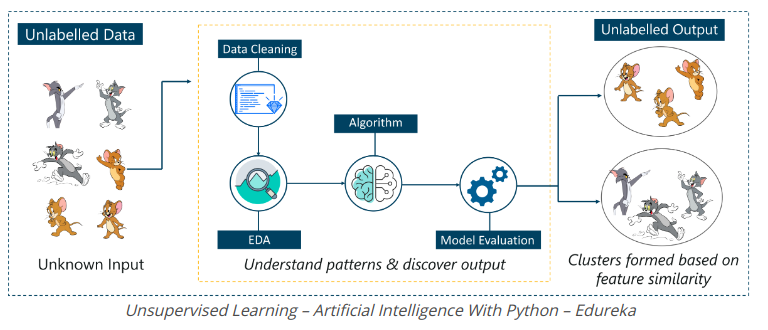
For example, it identifies Tom’s salient features like pointed ears, larger size, etc. to understand that this is a type 1 image. Similarly, it looks for such outstanding features in Jerry and Know that this image is of type 2.
Therefore, it categorizes the images into two different layers without knowing who Tom and Jerry are.
6.3. Reinforcement Learning
Reinforcement Learning is a part of Machine learning where an agent is put in an environment and he learns to behave in this environment by performing certain actions and observing the rewards which it gets from those actions. (Intensive learning is part of ML when an agent is introduced into the environment and he learns to behave in this environment by performing certain actions and observing the rewards received from actions. there.)
Imagine that you were abandoned on an isolated island!
What you will do?
Panic? Yes, of course, initially we would all be. But as time goes by, you will learn how to live on the island. You will explore the environment, understand the climatic conditions, the types of food that grow there, the dangers of the island, etc.
This is exactly how Reinforcement Learning works, it involves an Agent (you, stuck on the island) placed in an unknown environment (island), where he must learn by observing and performing. Actions that lead to rewards.
Reinforcement Learning is mainly used in advanced ML fields such as self-driving cars, AplhaGo, etc. Therefore, it includes all kinds of Machine Learning.
Now, let’s look at the kind of problem solved using Machine Learning.
7. What Problems Can Machine Learning Solve?
There are three main types of problems that can be solved by Machine Learning:
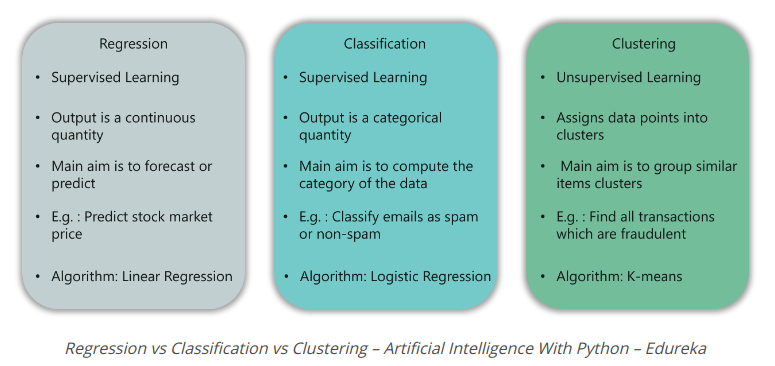
What is Regression? (What is regression?)
In this type of problem, the output is a continuous quantity. For example, if you want to predict a vehicle’s speed given distance, then that’s Regression. Regression problems can be solved using Supervised Learning algorithms such as linear regression.
What is Classification? (What is subdivision?)
In this category, the output is a taxonomic value. Classifying emails into two classes, spam and non-spam is a classification problem that can be solved using Supervised Learning classification algorithms such as Support Vector Machines, Naive Bayes, Logistic Regression, K Recent Neighbor, etc.
What is Clustering? (What is clustering?)
This type of problem involves assigning inputs into two or more clusters based on the similarity of the feature. For example, clustering viewers into similar groups based on their interests, age, geography, etc. can be done using Unsupervised Learning algorithms such as K-Means.
Now, let’s look at how Machine Learning works.
8. Machine Learning Process Steps
The Machine Learning process involves building a Predictive model that can be used to find solutions for Problem Reports.
To understand the Machine Learning process, let’s assume that you have encountered a problem that needs to be solved using Machine Learning.
The problem is to predict the appearance of rain in your local area using Machine Learning.
The steps below follow the Machine Learning process:
Step 1: Define the objective of the Problem Statement (Define the objective of the Problem Report)
At this step, we have to understand exactly what to predict. In our case, the goal is to predict the likelihood of rain by studying weather conditions.
It is also necessary to note what type of data can be used to solve this problem or what type of method you must follow to arrive at the solution.
Step 2: Data Gathering
At this stage, you have to ask questions like:
- What kind of data are needed to solve this problem?
- Is data available?
- How can i get the data?
When you know the types of data required, you must understand how you can get this data. Data collection can be done manually or by web scraping.
However, if you are a beginner and you just want to learn Machine Learning, you don’t have to worry about getting data. There are 1000 data resources on the web, you just need to download the data set and start doing.
Returning to the issue at hand, the data needed for weather forecasts include measures such as humidity, temperature, pressure, local, whether or not you live in a hill station, etc.
That data must be collected and stored for analysis.
Step 3: Data Preparation
The data you collect is almost never in the right format. You will encounter a lot of inconsistencies in the dataset such as missing values, backup variables, duplicate values, etc.
Removing such inconsistencies is essential because they can lead to miscalculation and false predictions. Therefore, at this stage, you scan the data set for any inconsistencies and you correct them later.
Step 4: Exploratory Data Analysis
This stage needs to dive deep into the data and find all the hidden data mysteries.
EDA or Exploratory Data Analysis is the brainstorming phase of Machine Learning. Data Exploration involves understanding patterns and trends in data. At this stage, all useful insights are drawn and the correlation between variables is understood.
For example, in the case of rainfall prediction, we know that there is a high chance of rain if the temperature is low. Such correlations must be understood and mapped at this stage.
Step 5: Building a Machine Learning Model
All of the insights and models gained in Data Exploration are used to build the Machine Learning Model. This phase always begins by splitting the dataset into two parts, training data and testing data .
Training data will be used to build and analyze the model. The logic of the model based on the ML Algorithm is being implemented.
In the case of rainfall prediction, since the output will be either True (if it will rain tomorrow) or False (no rain tomorrow), we can use classification algorithms such as Logistic Regression or Decision. Tree
Choosing the right algorithm depends on the type of problem you are trying to solve, the dataset and the complexity of the problem.
Step 6: Model Evaluation & Optimization
After building the model using the training data set, it’s finally time to put the model to the test.
The testing data set is used to test the effectiveness of a model and how accurate it can predict the results.
When accuracy is calculated, any further improvements in the model can be made at this stage. Methods such as parameter adjustments and cross validation can be used to improve model performance.
Step 7: Predictions (Prediction)
When the model is evaluated and improved, it is eventually used to make a prediction. The final output can be the Categorical variable (for example, True or False) or it can be Continuous Quantity (for example, the predicted value of a stock).
In our case, to predict the occurrence of precipitation, the output would be a categorical variable.
That is the whole Machine Learning process.
In the next section, we will discuss the different types of ML Algorithms.
Machine Learning Algorithms
Machine Learning Algorithms is the basic logic behind each Machine Learning model. These algorithms are based on simple concepts like Statistics and Probability.
Follow the blogs mentioned below to understand Math and the statistics behind Machine Learning Algorithm:
- A Complete Guide To Math And Statistics For Data Science
- All You Need To Know About Statistics And Probability
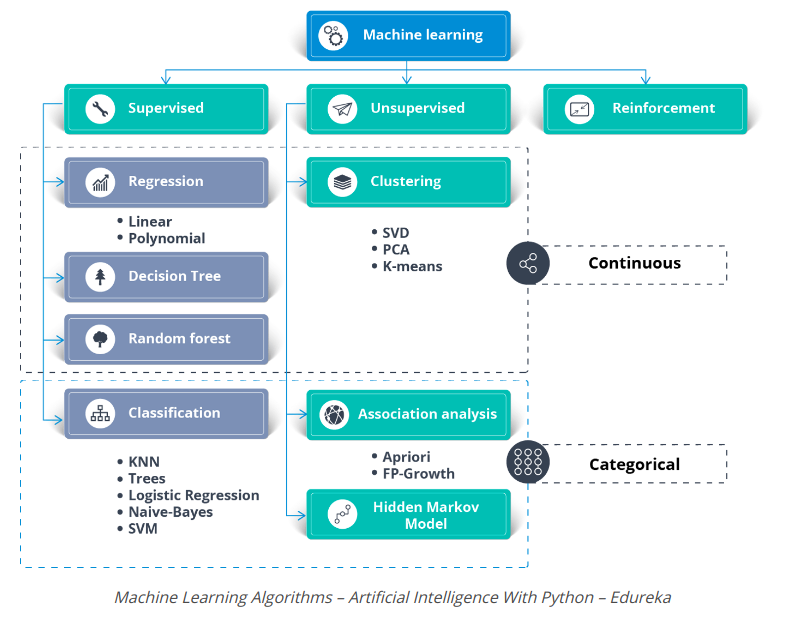
The picture above shows the different algorithms used to solve problems with Machine Learning.
Supervised Learning can be used to solve two types of Machine Learning problems:
- Regression
- Classification
To solve regression problems, you can use the famous linear regression algorithm ( Linear Regression Algorithm )
Classification problems can be solved by the following classification algorithms:
- Logistic Regression
- Decision Tree
- Random Forest
- Naive Bayes Classifier
- Support Vector Machine
- K Nearest Neighborhood
Unsupervised Learning can be used to solve cluster and link problems. One of the famous clustering algorithms is the K-means clustering algorithm.