ChatGPT is an evolution of InstructGPT, offering a new way to integrate human feedback into the training process to achieve results that match user intent. Reinforcement Learning from Human Feedback (RLHF) is detailed in the 2022 OpenAI paper on Training Language Models to Follow Instructions with Human Feedback and Simplified below.
Step 1: Supervised Fine Tuning (SFT) Model
The first development involved refining the GPT-3 model by hiring 40 employees to generate a supervised training dataset, where the input has a known output from which the model can learn. from that. Inputs, or messages, are gathered from actual user information into the Open API. The tickers then wrote a response that matched the message, producing a known output for each input. The GPT-3 model is then refined using this new monitoring dataset, to produce the GPT-3.5, also known as the SFT model.
To maximize diversity in the message dataset, there can be only 200 messages from any user ID, and all messages that share a long common prefix are discarded. Finally, all messages containing personally identifiable information (PII) were removed.
After aggregating messages from the OpenAI API, bookmarkers were also asked to create sample messages to fill out categories with little actual sample data. Categories of interest include
- Plain prompts – Simple questions: These are arbitrary requests that are not limited by any type.
- Few-shot prompts – sample questions and answers: Instructions containing multiple query/response pairs that can be used to learn from concrete examples.
- User-based prompts: Instructions corresponding to a specific use case have been requested for the OpenAI API.
When generating responses, labelers were asked to try to deduce what the instructions from the user were. The article describes three main ways that guidelines request information.
- Direct – Direct: “Tell me about …”
- Few-shot: Given two examples of a story, write another story on the same topic.
- Continuation – Continuation: Given the beginning of a story, finish it.
Compiling instructions from the OpenAI API and written by staff resulted in 13,000 input/output samples to use for the supervised model.
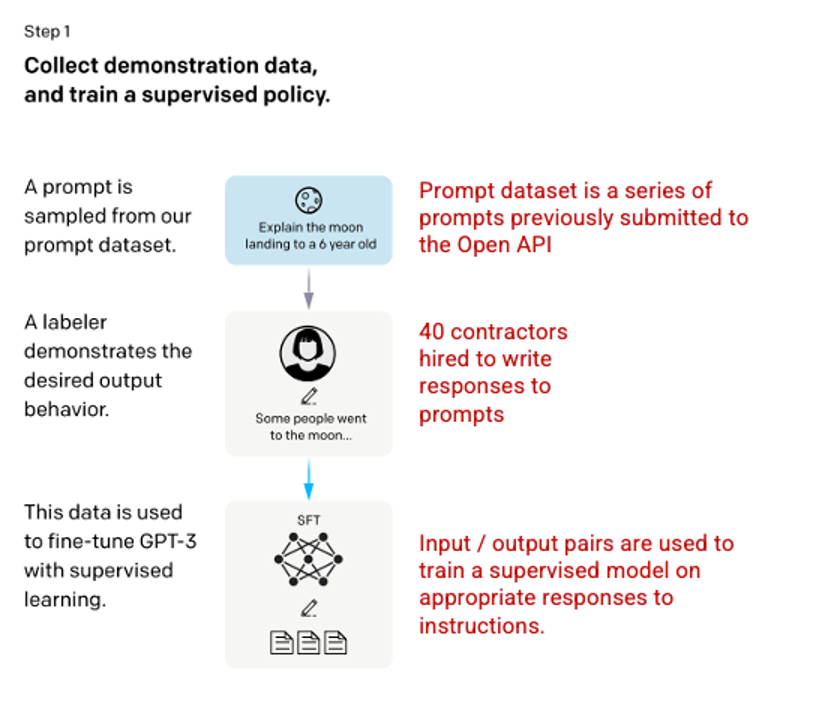
Picture 3.1.11.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf . Additional context added in red (right) by the author.
Step 2: Reward Model
After the SFT model is trained in step 1, the model will generate responses that are more compatible with the user’s request. The next improvement step is to train a reward model where the input to the model is a sequence of requests and responses, and the output is a scaler value called the reward. . A reward model is required to leverage Reinforcement Learning where a model learns to produce outputs to maximize its reward (see step 3).
To train the reward model, evaluators are presented with 4 to 9 SFT model outputs for a single input request. They were asked to rank these outputs from best to worst, generating the following output-rating combinations.
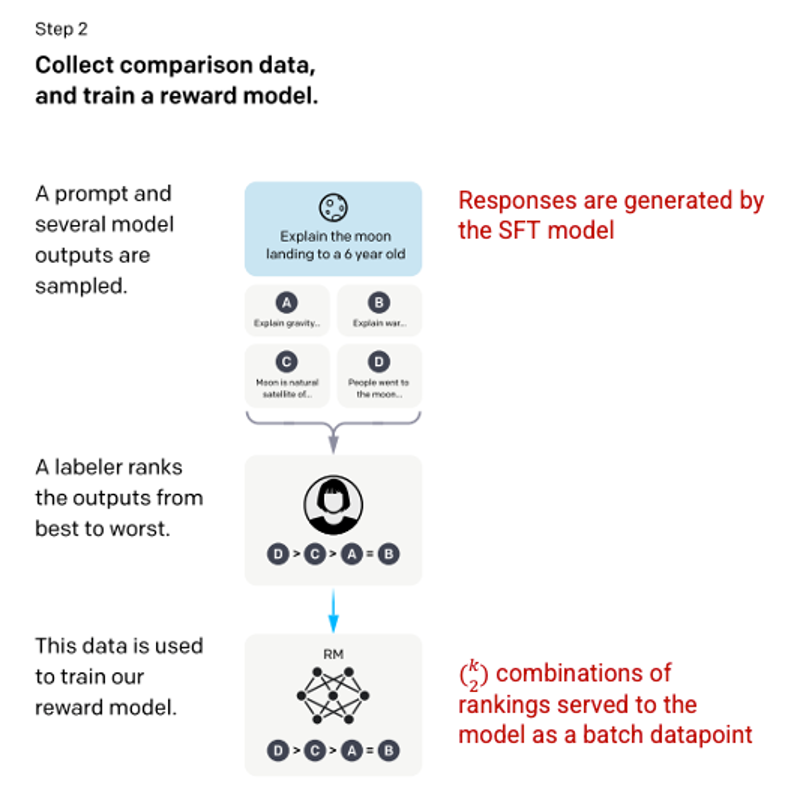 Picture 3.1.12.en Example of response ranking combinations
Picture 3.1.12.en Example of response ranking combinations
Including each combination in the model as a separate data point results in overfitting (not applicable on new data). To solve this problem, the model is built based on each ranking group as a single data point.
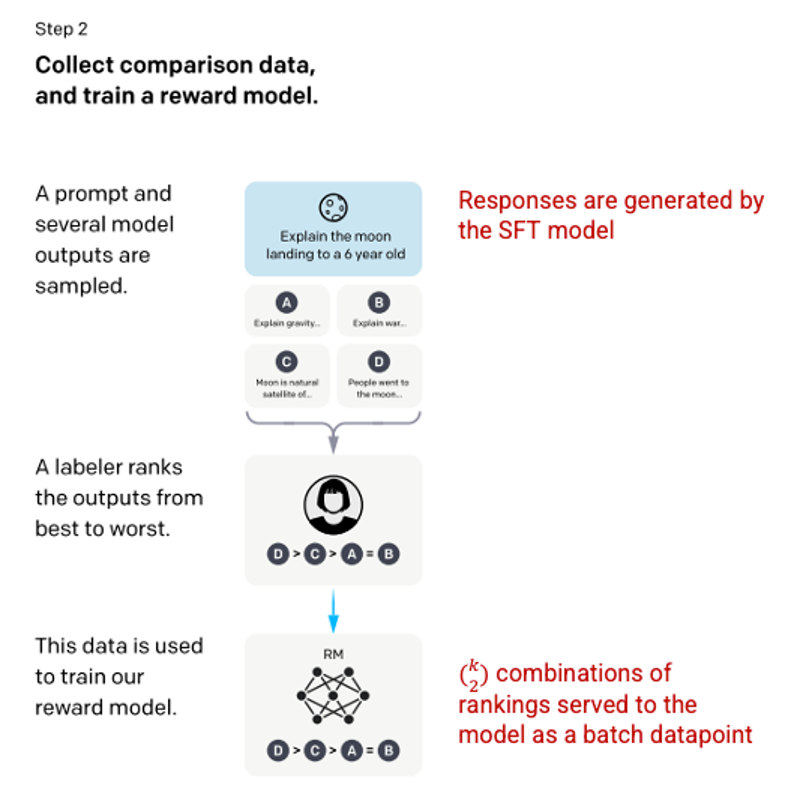 Picture 3.1.13.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf . Additional context added in red (right) by the author.
Picture 3.1.13.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf . Additional context added in red (right) by the author.
Step 3: Reinforcement Learning Model – Reinforcement Learning Model
In the final stage, the model is given a random question and returns an answer. The answer is generated using the ‘policy’ that the model learned in step 2. A policy represents a strategy that machine learning has learned to achieve its goal; in this case, maximize its reward. Based on the reward model developed in step 2, a reward value is determined for the question and answer pair. The reward is then fed back into the model for policy evolution.
In 2017, Schulman et al. introduced Proximal Policy Optimization (PPO), the method used to update the model’s policy as each response was generated. The PPO integrates a Kullback–Leibler (KL) per-token penalty from the SFT model. KL divergence measures the similarity of two distribution functions and penalizes the maximum distance. In this case, using a KL penalty reduces the distance that the answers can differ from the output of the SFT model trained in step 1 to avoid over-optimizing the reward model and deviating too much from human intent dataset.
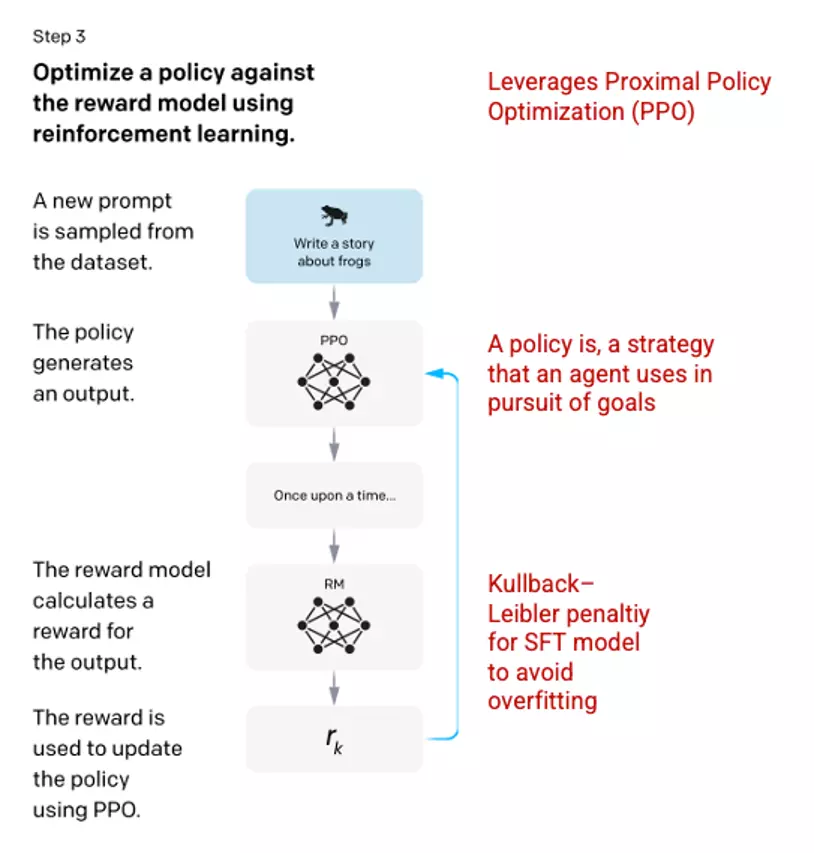 Picture 3.1.14.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf . Additional context added in red (right) by the author.
Picture 3.1.14.en Image (left) inserted from Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf . Additional context added in red (right) by the author.
Steps 2 and 3 of the process can be repeated many times in practice, but this has not been done much.