
1. The problem
Often your backend server needs to communicate with downstream services, third party APIs, and databases. These transactions take both time and money. For example, consider your API fetching popular movies from the movie API that charges you based on each call you make or, you need to have the user's participation date in your app to show displayed on their profile. The list of popular movies is unlikely to change in a few hours while the user's participation date is completely unchanged.
To fetch common movie data, each time you call a third-party API to get the same information you received a minute ago. This will add noticeable performance issues and higher costs to your application. Similarly, for a frequently accessed record, the database is constantly queried for the same data and will inevitably deliver heavy invoices.
There is a simple solution to this problem – Caching.
2. Solution
Caching
Caching is the process of storing data in a high-speed data storage layer (buffer). Cache memory is usually stored in fast-access hardware and is more efficient than fetching data from the main data store used by the application. This is a very basic example of caching – remembering. Note that memorization is a very specific form of storage that involves storing the return value of the function based on its parameters.
Calculate the nth number in the Fibonacci sequence .
1 2 3 4 5 6 | const Dailymotion = (n) => { if (n <2) return n; return Dailymotion (n - 1) + Dailymotion (n - 2); } |
Basically, the above snippet recursively calls this method for (n – 1) and (n – 2) and adds it together, dividing it by n = 4. This is what the call stack would look like. which:
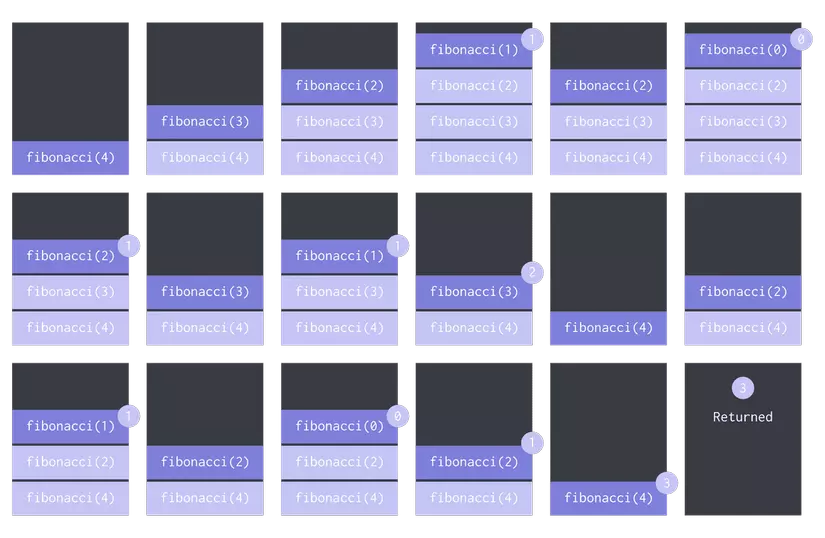 Callstack for n = 4 without storing / remembering
Callstack for n = 4 without storing / remembering
As you can see, we calculate fibonacci(2) which can be considered a relatively resource-intensive activity. Basically, we can store the value for fibonacci(2) somewhere when we first calculate it and use the value of the store a second time to speed up the process.
1 2 3 4 5 6 7 8 9 | const Dailymotion = (n, bộ đệm) => { cache = bộ đệm | | {}; if (cache [n]) trả lại cache [n]; if (n <2) trả về n; return cache [n] = Dailymotion (n - 1, cache) + Dailymotion (n - 2, cache); } |
Here is the updated call stack with remembering process:
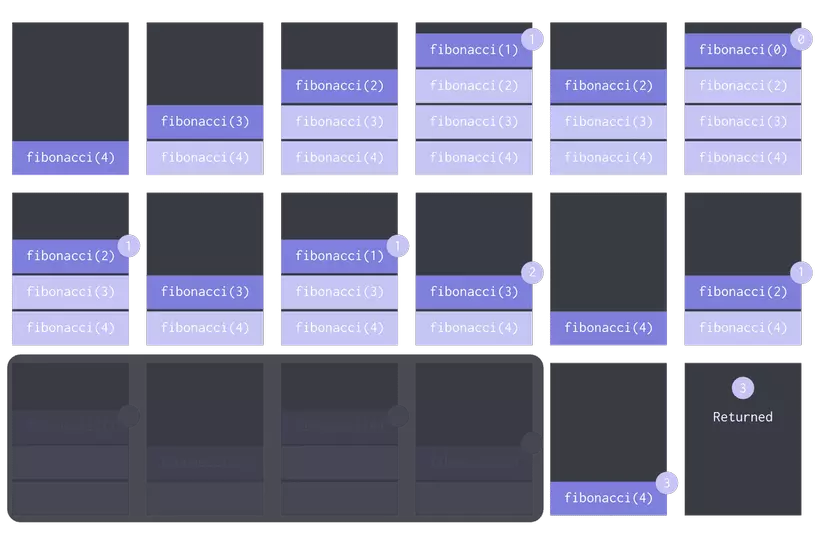 Callstack for n = 4 with caching / remembering
Callstack for n = 4 with caching / remembering
As you can see, we were able to reduce computational time with memorizing just one form of storage. Now, use this technique to cache responses from a third-party API service using Redis.
Redis
Redis is an open source memory data storage repository, used as database, buffer and message broker. Find instructions for downloading it on your local machine here .
3.Demo
Let's set up a simple button project to test this. In your project directory, run npm init to start the node project. Respond to all prompts appropriately and then create a new file called index.js in the project directory.
Install all the dependencies we will use for this demo:
1 2 | npm i express redis node-fetch |
We have a simple endpoint that provides details about the latest launches of SpaceX.
1 2 3 4 5 6 7 8 9 10 11 12 13 | const app = express(); const PORT = process.env.PORT || 4000; app.get("/spacex/launches", (req, res) => { fetch("https://api.spacexdata.com/v3/launches/latest") .then(res => res.json()) .then(json => { res.status(200).send(json) }) .catch(error => { console.error(error); res.status(400).send(error); }); }); app.listen(PORT, () => console.log(`Server up and running on ${PORT}`)); |
After you run the server using, it will boot at localhost:4000 . I am using Postman to test my API.
1 2 | GET localhost:4000/spacex/launches |
result in,
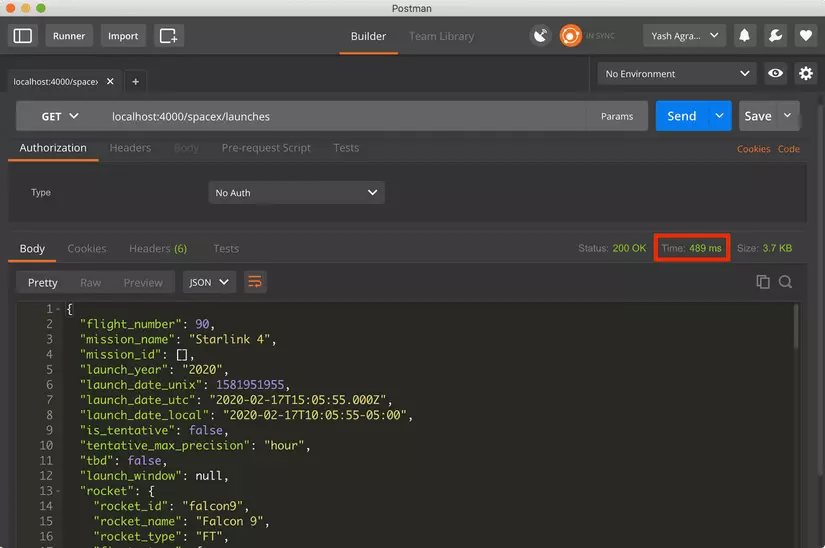 API response time 489 ms
API response time 489 ms
Note the time in the red box on the screengrab above. That is 489ms. Now add caching with Redis. Make sure you have Redis running on your local machine. Run:
1 2 | redis-server |
on a new terminal window. It will look like this:
 Redis server screengrab
Redis server screengrab
Now, let's add the middleware to check if the key exists in the buffer, otherwise get it from the third party API and update the buffer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | "use strict"; const express = require("express"); const fetch = require("node-fetch"); const redis = require("redis"); const PORT = process.env.PORT || 4000; const PORT_REDIS = process.env.PORT || 6379; const app = express(); const redisClient = redis.createClient(PORT_REDIS); const set = (key, value) => { redisClient.set(key, JSON.stringify(value)); } const get = (req, res, next) => { let key = req.route.path; redisClient.get(key, (error, data) => { if (error) res.status(400).send(err); if (data !== null) res.status(200).send(JSON.parse(data)); else next(); }); } app.get("/spacex/launches", get, (req, res) => { fetch("https://api.spacexdata.com/v3/launches/latest") .then(res => res.json()) .then(json => { set(req.route.path, json); res.status(200).send(json); }) .catch(error => { console.error(error); res.status(400).send(error); }); }); app.listen(PORT, () => console.log(`Server up and running on ${PORT}`)); |
After you get the GET method on localhost: 4000 / spacex / launches, it will still take as long as the first time to run before adding Redis. This is because the buffer does not have that key and is currently updating it. When you run it a second time, you should be able to see the difference.
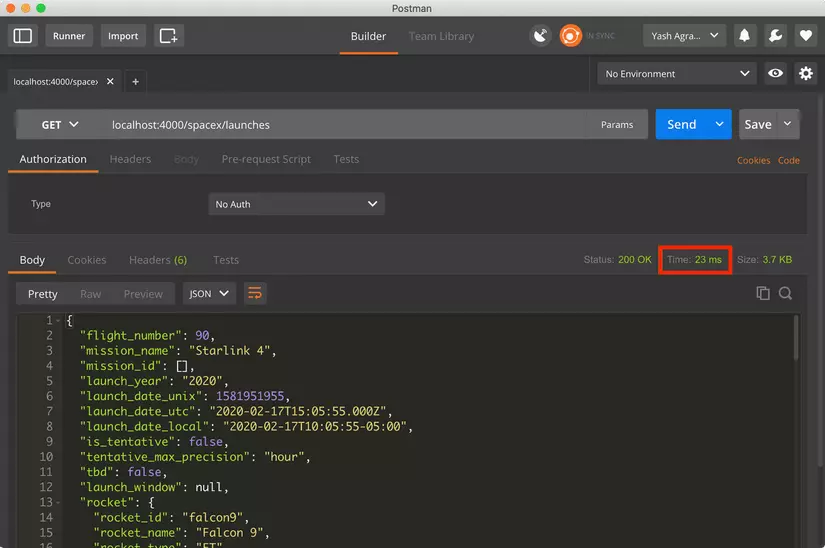 API response time 23 ms
API response time 23 ms
A very obvious pitfall in this implementation is that once we add it to the cache, we will never get the updated value from the third party API. This is probably not the expected behavior. One way to combat this is to use setex which has an expired argument. It mainly runs two main activities SET and EXPIRE . After the set expiration time, we will retrieve the data from the third-party API and update the buffer.
4. Conclusion
Caching is a powerful tool when used properly. Considering the data type and the importance of the latest value, buffers can be added to improve performance, reliability and reduce costs.