BERT: Modern language model for natural language processing (NLP)
- Tram Ho
BERT (Two-dimensional encoder representative from Transformers) is a recent article published by researchers at Google AI Language. It has caused a tumultuous community of Machine Learning by presenting advanced results in many NLP problems, including Question Answering (SQuAD v1.1), natural language reasoning (MNLI) and other problems.
The key technical breakthrough of BERT is the training through two-dimensional context of Tranformer (a neural network architecture based on self-attention mechanism to understand language), an uncle model Popular idea, for language modeling. This contrasts with previous attempts to consider a text-style training sequence from left to right or a combination of training from left to right and right to left. The results of the paper show that a two-way trained language model may have a deeper sense of context than the pattern of training languages in one direction. In the article, the researchers describe in detail a new technique called Masked LM (MLM) that allows two-way training in models that were not previously possible.
overview
In the field of computer science, researchers have repeatedly shown the value of intercourse – training a neural network model on a known problem, for example, ImageNet, and then performing fine correction – using neural networks trained as a basis for a new specific purpose model. In recent years, researchers have shown that a similar technique can be useful in many natural language problems.
Another approach, also popular in NLP problems and illustrated in the recent ELMo article, is feature-based training. Under this approach, a trained neural network creates the embedding words which are then used as features in NLP models.
How does BERT work?
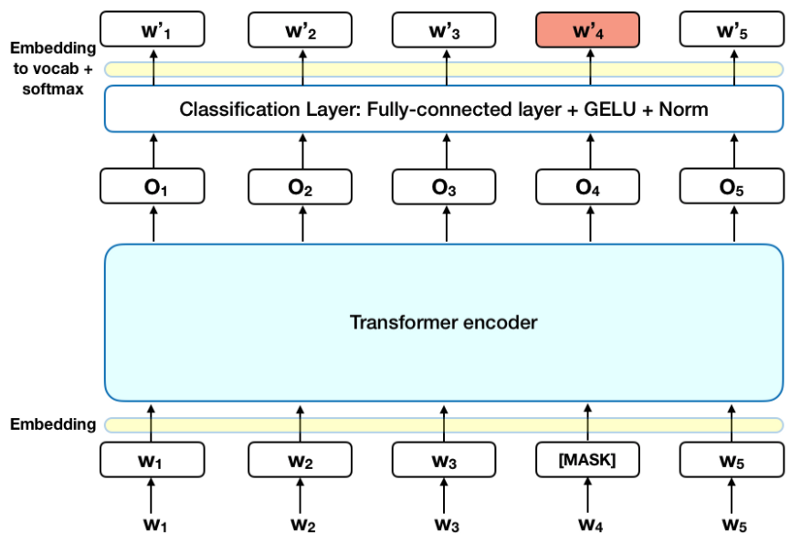
The chart below is a high-level description of the Transformer encoder. The input is a series of tokens, first embedded into the vectors and then processed in the neural network. The output is a series of vectors of size H, where each vector corresponds to an input token with the same index.
When training language models, there is a challenge in defining predictable goals. Many models predict the next word sequentially (for example: The child comes home from ___), an approach that inherently constrains contextual learning. To overcome this challenge, BERT uses two training strategies:
Masked LM (MLM)
Before giving the word string to the BERT, 15% of the words in each string are replaced by the [MASK] token. The model then attempts to predict the initial value of the masked words, based on the context provided by words that are not quite concealed in the string. Technically, the prediction of the required output words:
- Add a classifier at the output of the encoder.
- Multiply the output vectors with the embedded matrix, converting them into vocabulary dimensions.
- Calculate the probability of each word in the vocabulary with softmax function.
 Loss function BERT only considers predicting the masked values and ignoring the predictions of non-masked words. As a result, the model converges slower than orientation models but is offset by its increased contextual awareness. * Note: In fact, the BERT deployment is a bit more complicated and does not replace all 15% concealed words. See Appendix A for more information. *
Loss function BERT only considers predicting the masked values and ignoring the predictions of non-masked words. As a result, the model converges slower than orientation models but is offset by its increased contextual awareness. * Note: In fact, the BERT deployment is a bit more complicated and does not replace all 15% concealed words. See Appendix A for more information. *
 Loss function BERT only considers predicting the masked values and ignoring the predictions of non-masked words. As a result, the model converges slower than orientation models but is offset by its increased contextual awareness. * Note: In fact, the BERT deployment is a bit more complicated and does not replace all 15% concealed words. See Appendix A for more information. *
Loss function BERT only considers predicting the masked values and ignoring the predictions of non-masked words. As a result, the model converges slower than orientation models but is offset by its increased contextual awareness. * Note: In fact, the BERT deployment is a bit more complicated and does not replace all 15% concealed words. See Appendix A for more information. *Predict the next sentence (Next Sentence Prediction (NSP))
In the BERT training process, the model receives the pairs of sentences as input and learns how to predict if the second sentence in the pair is the next sentence in the original document. During the training, 50% of the input is a pair in which the second sentence is the next sentence in the original, while the remaining 50%, a random sentence from the corpus is chosen as the second sentence. Assume that random sentences will be disconnected from the first sentence.
To help the model distinguish between two sentences in training, the input is processed in the following way before entering the model: 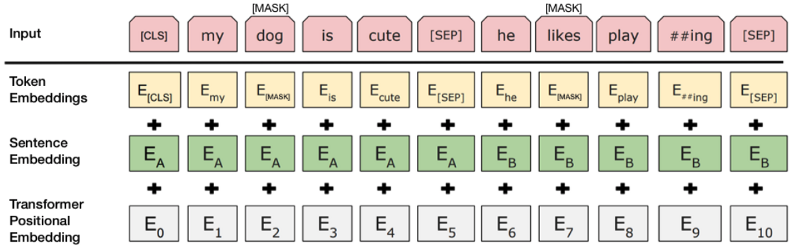 Source: BERT [Devlin et al., 2018], with modification
Source: BERT [Devlin et al., 2018], with modification
To predict if the second sentence is actually connected to the first sentence, the following steps are taken:
1 2 3 | 1. The entire input chain goes through the Transformer model. 2. The token output [CLS] is converted to a 2 × 1 vector, using a simple classification class (the matrix has learned about weights and deviations). 3. Calculate the probability of the next sentence with softmax. |
When implementing BERT model training, Masked LM and the next Sentence Prediction (NSP) are trained together, with the goal of minimizing the combination of loss functions of the two strategies.
How to use BERT (Refine)
Using BERT for a specific problem is relatively simple:
BERT can be used for many language problems, while only adding a small class to the core model:
- The classification problems such as emotional analysis are carried out similarly to the classification of the next sentence, by adding a classification class on the Transfomer output for the [CLS] token.
- In the Question Answering Problem (Question Answering) (eg SQuAD v1.1), the software receives a question regarding the text string and is asked to mark the answer in the string. Using BERT, a Q&A model can be trained by learning two more vectors that mark the beginning and end of the answer.
- In Named Entity Recognition (NER), the software receives a text string and is asked to mark different types of entities (Person, Organization, Date, etc.) that appear in document. Using BERT, a NER model can be trained by providing the output vectors of each token into a classifier that predicts NER labels.
In fine-tuning training, most of the super parameters remain the same as in BERT training and the article provides specific instructions (Section 3.5) about the super parameters that need adjusting. The BERT team used this technique to achieve good results on many challenging natural language problems, detailed in Part 4 of the paper.
Things need to notice
- On model size issues, even on a large scale. BERT_large, with 345 million parameters, is the largest model of its kind. It is extremely superior to small-scale problems compared to BERT_base, using the same architecture with only 110 million parameters.
- With enough training data, more training steps correspond to higher accuracy. For example, on the MNLI task, the accuracy of BERT_base improved by 1% when trained with 1 million steps (128,000 words) compared to 500,000 steps.
- BERT’s two-way approach (MLM) converges more slowly than a left-to-right approach (because only 15% of words are predicted in each batch), but two-way training is still superior to word training. left to right.
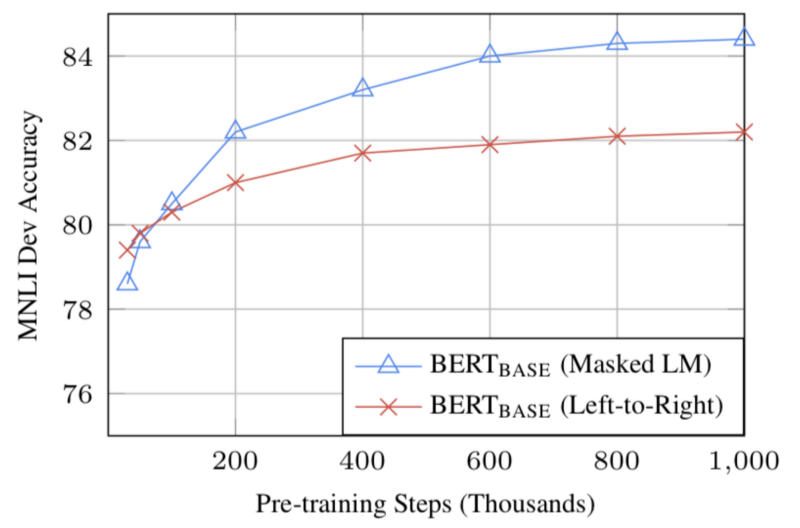
Source: BERT [Devlin et al., 2018], **
Calculation considerations (training and application)

Conclude
BERT is definitely a breakthrough in using Machine Learning to handle natural language. The fact that it is accessible and allows for quick tweaking will likely allow a variety of practical applications in the future. In this summary, we tried to describe the main ideas of the article while not immersed in excessive technical details. For those who want to understand more deeply, we recommend reading the entire article and the supporting articles referenced in it. Another useful reference is the BERT source code and model, which includes 103 languages and is widely released by the research team as open source.
Appendix A – Word Masking
Training in BERT language model is done by predicting 15% token in input, randomly selected. These tokens are pre-processed as follows – 80% are replaced by the [[MASK]] token, 10% with a random word and 10% of the original word. Intuition makes the authors choose this approach as follows (Thanks to Jacob Devlin from Google for insight):
- If we use [MASK] 100% of the time, the model will necessarily generate good token representations for words that are not covered. Non-masked tokens are still used for context, but the model has been optimized to predict masked words.
- If we use [MASK] 90% of the time and random words 10% of the time, this will teach the model that observe words are never right.
- If we use [MASK] 90% of the time and stay the same for 10% of the time, the model can be non-contextual.
No excision is made on the ratio of this method, and it may have worked better with different rates. In addition, the model performance was not tested with concealment of 100% token selection
References
- https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
- https://arxiv.org/abs/1810.04805
- https://en.wikipedia.org/wiki/Make_softmax
Source : viblo.asia