Text processing
The first concepts in natural language processing:
- What is text? : text is a string of many things:
- 1 set of characters (characters – the lowest level of the text)
- 1 set of words (words – a series of characters with some meaning)
- 1 set of phrases (phrases – a sequence of words)
- 1 set of sentences
- 1 set of paragrahs (paragraphs)
- What are words? : is a meaningful sequence of characters
- separate words:
- Separate words in English: separated based on punctuation, the space to the left of each word
- Working words in other languages: harder because words aren’t necessarily separated by spaces
- separate words:
The method of text processing
What is a token splitting ?:
Separating tokens from an input text is called tokenization . It works by splitting input text into a separate set of tokens. Also known as meaningful chunks. Can understand a chunk can be a word, a phrase, a sentenses or even a paragraphs. Each chunk is called a token .
Methods of implementing tokenization:
whitespaceTokenizer:
Separate tokens based on spaces or whatever characters are not displayed. Can be used in python with the NLTK library: whitespaceTokenizer
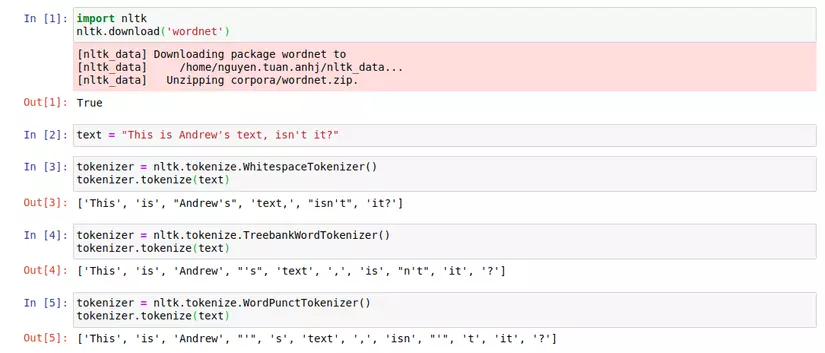
For example: Input text: *This is Andrew's text, isn't it?*
We can separate this sentence based on whitespace. But there will be problems here. The tokens that will be separated are *This* , *is* , *Andrew's* , *text* , *isn't* , *it?* . *it?* has a final question mark. Does it really mean to be a separate token if it doesn’t have a question mark at the end? Ie *it?* And *it* are 2 different tokens but have the same meaning or not !. It is understandable that we wish to combine these two cases into one because they carry the same meaning and the question mark is like a comma, it is like a token in a simple text.
WordPunctTokenizer :
This method is to separate tokens based on punctuation. A tokenizer is available in the NLTK library. The downside of this method is that it will separate non-meaningful tokens. For example, still with the above, it is parsed This , is , Andrew , ' , s , text , , , isn , ' , t , it , ? . The tokens t , s , isn do not make sense for later analysis, and they only make sense when combined with previous punctuation or words.
TreebankWordTokenizer
To solve the problem of the second method, we will separate the token based on a set of rules. It uses grammar rules in English to implement tokenizer. And it really makes sense for tokens semantically. Also with the above example we will split the tokens: *This* , *is* , Andrew , 's , text , , , is , n't , it , ? . The token 's and n't have a certain meaning.
You can refer to the code below:
To standardize tokens (token normalization)
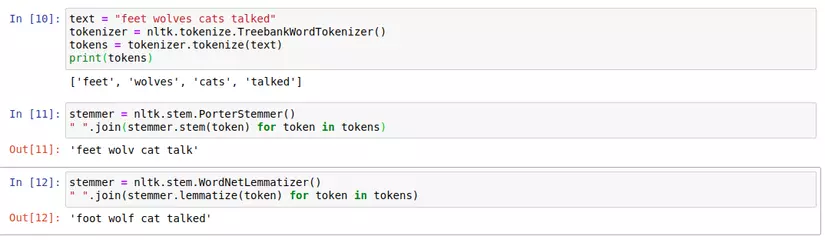
The next thing to do is to standardize the same token to its native format. For example, wolf and wolves are words with the same meaning. What we need to do is bring these two words back to their original format, wolf . Similarly, in English there are many such cases, the case of adding s to the word, the case of adding ed or the case of words being completely changed from the original word format. For cases that have an ending in words, we really don’t need to care about them, at least in task: text classification.
There are two methods to standardize tokens: stemming and lemmazation .
- Stemming : replaces the suffixes to get to the original format of the word, that is, the so-called stem . It comes from the idea of cutting off or replacing the suffix of words. The disadvantage of this method is that when the tokens are completely transformed from the original format, this rule will no longer be true. For example :
- Lemmazation : when it comes to this method, people often think of using the analysis of vocabularies (vocabulary) and morphological ( morphological ).
An example of a stemmer is Porter’s stemmer. This is the oldest stemmer in English. It has rules about the suffix of words and based on that we can standardize the token:

However, in special cases, tokens will not be able to apply this rule, for example:

You can find this stemmer in the nltk library.
An example of lemmtization: I use the WordNet lemmatizer, it uses the WordNet database to look up the lemma, or the original format of the word. You can also find it in the NLTK library. For example, also in the case of stemming you can see that the token normalization result is more correct:

However, this way also cannot cover all cases, for example, nouns, having s and es will be completely different meanings and for verbs is another story. So, in fact, depending on the application you should use stemmer or lemmatizer appropriately.
You can refer to the following code for two token normalization methods:
P / S : in addition, we have a few tricks in tokenization. For example :
- Case 1: uppercase characters: For example, Us and us or US and us. Both have the same Us and us pronunciation, but it’s safer to put it back on us. For US and us is another story, one is the country, one is the pronoun. We need to distinguish them in some way. A simple idea is that, for example, to sort the emotions of a review, for example, often the case will fall into users writing while Cap Locks are still on. That is, it is capitalized letters, Us and us are pronouns, not country. Another way is in English, we will usually have three cases:
- Sentence capitalization will often fall prey to that token being capitalized only
- Capitalization in titles also falls into case 1: because in TA the characters in the title must be capitalized
- Capitalize in the middle of a word, usually this will be the name of the entity or place name.
- TH2: Abbreviations: this is often a difficult case in standardization.
In the following article, I will talk about Feature extraction from text. The content is taken from the Natural Language Processing course provided by National Research University Higher School of Economics . You can refer to the course here . Thank you for reading this article. See you in the following article!