After the HIVE series, I will bring the Apache Presto series, this guy can use HIVE as a connector in his architecture, let’s learn about it, let’s start!
Apache Presto is an open source distributed SQL tool. Presto originated from Facebook for the need to analyze data and was then open sourced. Now, Teradata joins the Presto community and provides support.
Apache Presto is very useful for executing queries even petabytes of data. The extensible architecture and the host plugin interface is very easy to interact with other file systems. Most of today’s best industrial companies are adopting Presto because of its low interaction speed and latency performance.
Let’s explore Presto’s architecture, configuration, and hosting plugins. And let’s discuss basic and advanced queries, ending with real-time examples. This guide should give you enough knowledge to get to know Apache Presto. Before continuing to follow this series of tutorials, you should have a good understanding of Core Java, DBMS, and any Linux operating system.
Data analysis is the process of analyzing raw data to gather relevant information in order to make better decisions. It is mainly used in many organizations to make business decisions. Big data analysis involves a large amount of data, and the process is quite complex, so companies use different strategies.
For example, Facebook is one of the leading data providers and has the largest data warehouse in the world. Facebook’s warehouse data is stored in Hadoop for large-scale computing. Then, when the data of the stock rose to petabytes, they decided to develop a new system with low latency. In 2012, members of the Facebook team designed “Presto” for interactive query analysis that will work quickly even with petabytes of data.
Definition: What is Apache Presto?
Apache Presto is a distributed parallel query execution engine, optimized for low latency and interactive query analysis. Presto runs queries easily and scales in no time from gigabytes to petabytes.
A single Presto query can process data from multiple sources like HDFS, MySQL, Cassandra, Hive, and many others. Presto is built in Java and easily integrates with other data infrastructure components. Presto is strong and top companies like Airbnb, DropBox, Groupon, and Netflix are adopting it.
Feature
Presto contains the following features:
- The architecture is simple and scalable.
- Pluggable Connector – Presto supports a pluggable connector to provide metadata and data for queries.
- Pipeline execution – Avoid unnecessary I / O latency costs.
- User Defined Functions – Analysts can create custom user defined functions for easy portability.
- Handles the vectorized column.
Benefit
Here is a list of the benefits that Apache Presto offers:
- Dedicated SQL operations
- Easy to install and debug
- Abstract simple archive
- Quickly scale petabyte data with low latency
Application
Presto supports most of today’s best industrial applications. Let’s take a look at some notable applications.
- Facebook – Facebook built Presto for the needs of data analysis. Presto easily expands the massive speed of data.
- Teradata – Teradata provides end-to-end solutions in Big Data analysis and data archiving. Teradata’s contribution to Presto makes it easier for many companies to fulfill all analytical needs.
- Airbnb – Presto is an integral part of the Airbnb data infrastructure. Hundreds of employees are performing queries every day with this technology.
Why Presto?
Presto supports standard ANSI SQL for easy data analysts and developers. Although it is built in Java, it avoids the typical Java code problems associated with memory allocation and garbage collection. Presto has a Hadoop-friendly connector architecture. It allows for easy plugging in file systems.
Presto runs on many Hadoop distributions. In addition, Presto is accessible from the Hadoop platform to query Cassandra, relational databases or other data warehouses. This cross-platform analytics capability allows Presto users to extract maximum business value from gigabytes to petabytes of data.
The architecture of Presto
Presto’s architecture is almost similar to the classic DBMS MPP (batch parallel processing) architecture. The following diagram illustrates the architecture of Presto.
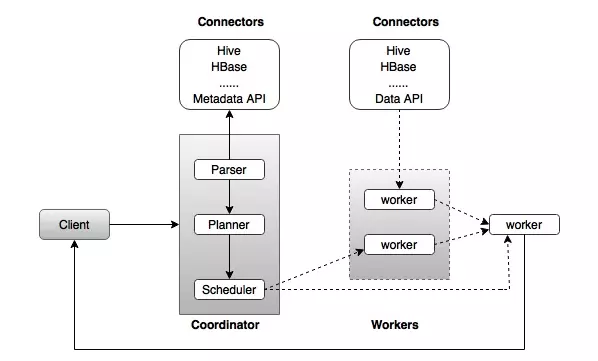
The above diagram includes different components. The following table describes each of the components in detail.
| No | Composition and Description |
|---|---|
| first | Client : Client (Presto CLI) sends SQL statements to Coordinator to receive results. |
| 2 | Coordinator : Coordinator is a main daemon. The coordinator initially parses the SQL queries and then parses and plans the query’s execution. Pipeline execution scheduler, assigning work to nearest node, and monitoring progress. |
| 3 | Connector : The host plugin is called a connector. Hive, HBase, MySQL, Cassandra and more act as a connector; if not, you can also implement a custom one. Connector provides metadata and data for queries. The coordinator uses the connector to get the metadata to build a query plan. |
| 4 | Worker : Coordinator assigns tasks to the worker nodes. Worker gets actual data from connector. Finally, the worker node delivers the result to the client. |
Workflow
Presto is a distributed system that runs on a cluster of buttons. Presto’s distributed query engine is optimized for interactive analysis and supports standard ANSI SQL, including complex queries, aggregation, binding, and window functions. Presto architecture is simple and extensible. The Presto (CLI) client sends SQL statements to the main daemon coordinator.
Scheduler connection via pipeline execution. Scheduler assigns jobs to nodes closest to data and monitors progress. The coordinator assigns the tasks to multiple worker nodes, and eventually the worker node sends the results back to the client. The client retrieves data from the output process. Scalability is design important. Suitable connectors such as Hive, HBase, MySQL, etc., provide metadata and data for queries. Presto is designed with a “simple storage abstraction” that makes it easy to provide the ability to query SQL against these different types of data sources.
Execution model
Presto supports custom query and execution tools with operators designed to support SQL semantics. In addition to the improved scheduling, all processing is in memory and networked between different phases. This avoids unnecessary I / O latency costs.
That’s all about the introduction of general Apache Presto, next I will write about how to install, configure and use Apache Presto, everyone watching ^^
Source: https://www.tutorialspoint.com/