Log data structure in Kafka
The key to scalability and performance of kafka is log. Loging here is not the term used in application logs, but the structure of log data. Log is a consistent ordered data structure that only supports append type. It is not possible to edit or delete records from it. It is read from left to right and guaranteed with the order of items.
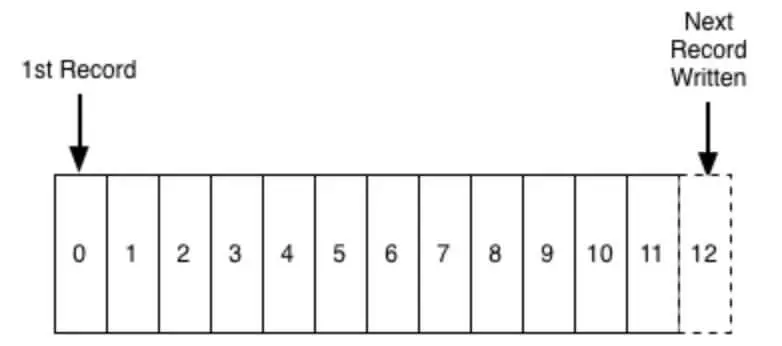
A producer will write the message to the log and one or more other consumers will read the message from the log at the time of their choice.
Each entry in the log is identified by a number called offset, or, to put it more plainly, offset is like a serial number in an array.
Because the string / offset can only be maintained on a specific node / broker and cannot be maintained for the entire cluster, Kafka only guarantees the order of data for each partition.
Persistence data in Kafka
Kafka stores all messages on disk (not on RAM) and is organized in a log structure that allows kafka to make the most of its ability to read and write to disk sequentially.
It’s a fairly common way to store data on disk and still be able to maximize performance, for a few key reasons below:
- Kafka has a protocol that groups messages together. This allows network requests to group messages together, reducing the cost of using network resources, the server, gathering messages into a lump, and consumers fetching one block of messages at a time – thus reducing Download disk for operating system.
- Kafka depends a lot on pagecache of the operating system for storing data, using RAM on the computer effectively.
- Kafka stores messages in binary format throughout the process (producer> broker> consumer), making it possible to take advantage of zero-copy capability. This means that when the operating system copies the data from pagecache directly to the socket, completely ignoring the middleware application is kafka.
- Read / write linear data on disk fast. The problem with slow disks nowadays is often due to repeated searches on the disk. Kafka reads and writes on linear disks, so it can take full advantage of disk performance.
Consumer and Consumer Group
Consumer reads messages from any partition, allowing for the expansion of the number of messages used in the same way that producers deliver messages.
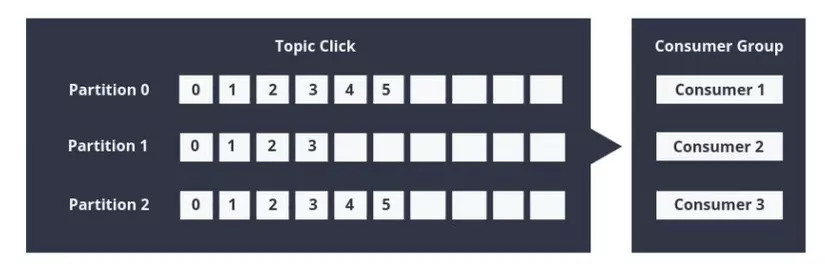
Consumer is also organized into consumer groups for a specific topic by adding the Group.id attribute to each consumer. Giving the same group id to different consumers means they will join the same group. Each consumer within the group reads the message from one partition, to avoid having two consumers read the same message twice and the entire group processes all messages from the whole topic.
- If the number of consumers> number of partitions, then some consumers will be idle because they have no partitions to handle.
- If the partition number is> the number of consumers, then the consumer will receive messages from multiple partitions.
- If number of consumers = number of partitions, each consumer will read the message in order from 1 partition.
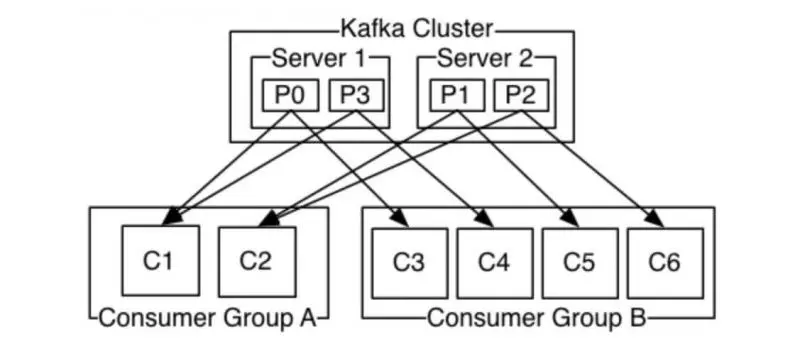
Server 1 holds partitions 0 and 3 and server 2 holds partitions 1 and 2. We have 2 consumer groups, A and B. Group A has 2 consumers and group B has 4 consumers. Consumer group A has 2 consumers, so each consumer will read the message from 2 partitions. In consumer group B, the number of consumers is equal to the number of partitions, so each consumer will read the message from one partition.
Every time a consumer is added or removed from a group, the consumption is rebalanced among the consumers in the group. All consumers stop on every rebalance, so frequent client restarts or timeouts will reduce throughput.
Kafka follows the rules provided by brokers and consumers. That is, Kafka does not keep track of the records read by consumers and therefore knows nothing about consumer behavior. The retention of messages for a pre-configured period and it is up to the consumer, to adjust the time accordingly. The consumer himself will probe to see if Kafka has any new messages and let Kafka know which records they want to read. This allows them to increase / decrease the offset that the consumer wants, so it can reread messages that have already been read and re-process events in case of a failure.
For example, if Kafka is configured to keep messages existing for a day and the consumer is down for longer than 1 day, then the consumer will lose the message. However, if the consumer is only down for about 1 hour, then it is possible to start reading the message from the latest offset.
Apache Kafka Workflow | Kafka Pub-Sub Messaging
Pub-Sub Messaging
- Kafka Producer sends a message to the topic.
- Kafka Broker stores all messages in partions that are configured with that particular topic, ensuring that messages are evenly distributed among the partions. For example, Kafka will store one message in the first partion and the second in the second partion if the producer sends two messages and has two parts.
- Kafka Consumer subscribes a specific topic.
- After the consumer subscribes to a topic, Kafka provides the topic’s current offset to the consumer and stores it in the Zookeeper.
- In addition, consumers will constantly send requests to Kafka (such as 100 Ms) to pull back new messages.
- Kafka will forward the message to consumers as soon as it is received from Producer.
- Consumer will receive the message and process it.
- The broker Kafka receives confirmation of the message being processed.
- Kafka updates the current offset value as soon as the confirmation is received. Even while the server is outrages, consumers can read the next message correctly, because ZooKeeper manages the offset.
- This process repeats until the consumer stops subscribing
Kafka Queue Messaging / Consumer Group
A Kafka consumer group with the same group id can register a topic, instead of just one consumer. However, with the same group id all consumers registering the topic are considered to be a single group and sharing messages. The workflow for this system is as follows:
- Kafka Producer sends a message to the topic
- As with pub-sub messaging, Kafka also stores all messages in partions configured for that particular topic.
- A single consumer subscribes to a specific topic.
- Like pub-sub messaging, Kafka interacts with consumers until the new consumer subscribes to the same topic.
- When the new consumer arrives, the sharing mode starts in the activities and the data sharing between the two Kafka consumers. Furthermore, until the number of Kafka consumers equals the number of partions configured for that particular topic, the sharing will repeat.
- Once the number of Kafka consumers exceeds the number of partions, the new Kafka consumer will not receive any more messages. It stays in place until any one of the current consumers unsubscribes. This arises because in Kafka there is a condition that every Kafka consumer will have at least one partion and if no partion is empty, the new consumer will have to wait.
Reference source
- https://www.tutorialspoint.com/apache_kafka/apache_kafka_cluster_architecture.htm
- https://blog.vu-review.com/kafka-la-gi.html
- https://data-flair.training/blogs/kafka-architecture/
- https://www.cloudkarafka.com/blog/2016-11-30-part1-kafka-for-beginners-what-is-apache-kafka.html
- https://www.facebook.com/notes/community-big-data-viet-nam/continuous-kafka-thong-qua-confluent-platform/884414712076055/