Kafka Topics
Topic is a channel for producers to publish messages from which consumers receive messages.
Each topic will have a user-defined name and can be treated as a queue of messages (per data stream). New messages pushed by one or more producers, will always be added to the end of the queue. Because every message pushed to the topic will be assigned an offset (for example: the first message has an offset of 1, the second message is 2 …), consumers can use this offset to control too. Message reader. But note that because Kafka will automatically delete messages that are too old (push messages are more than two weeks old or deleted because the memory allowed to hold the messages is full), it will cause an error if accessed. on deleted messages.
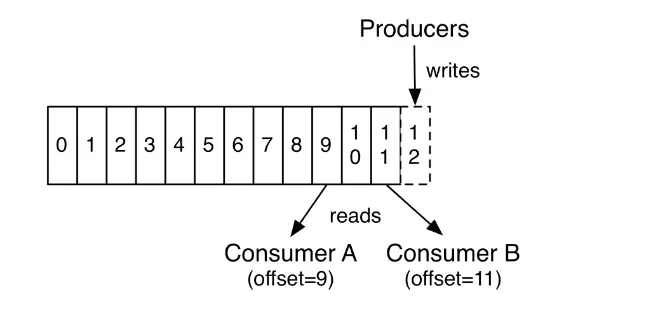
The above describes a topic with only one partition. In fact, a topic has many partitions, when a message is pushed to the topic, it will be assigned a random number by default. Which messages are pushed into a thread depends on the hash value of the string, this ensures the same number of messages on each partition. Because at one time, a partition can only be read by a single consumer, increasing the number of partitions increases the amount of data being read by paralleling the reading. In addition, offset is the unique identifier for each message in the partition, not the entire topic, so for consumers to read the message correctly, we need to provide the address of the form message (topic, partition, offset).
The following image depicts a topic with multiple partitions.
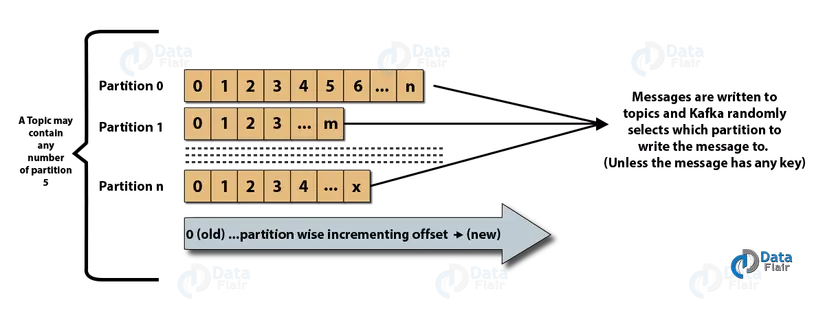
Kafka partition
Topics in kafka can be very large, so don’t store all the data of a topic on a node, the data needs to be partitioned into multiple partitions to help preserve data as well as process data. easier. Partitions allow us to perform subcribe in parallel to a specific topic by dividing data in a specific topic among different brokers ( kafka nodes ), each partition can be placed on a separate machine – for Allows multiple consumers to read data from a topic that takes place in parallel.

For each partition, depending on the user configuration, there will be a certain number of replica partions to ensure data will not be lost when a node in the cluster fails, but the number of copies cannot exceed number of brokers in the cluster, and those copies will be saved to other brokers. The broker contains the original copy of the partition called the “leader” broker. These copies work to prevent the system from losing data if some broker fails, provided that the number of broker failures is not greater than or equal to the number of copies of each partition. For example, a partition with two copies stored on three brokers will not lose data if one broker fails. It is also important to note that because these copy versions do not receive data directly from the producer or are read by consumers, they only synchronize with paritition so it does not increase the possibility of parallelism. reading and writing.
To increase the availability of a partition, each partition has its own replicas value. Below is an example with 3 nodes / broker.
Now, a topic will be divided into 3 partitions and each broker will have a copy of the partition. Among these partition copies, one will be elected as the leader, while the other copies will only synchronize data with the partition leader.
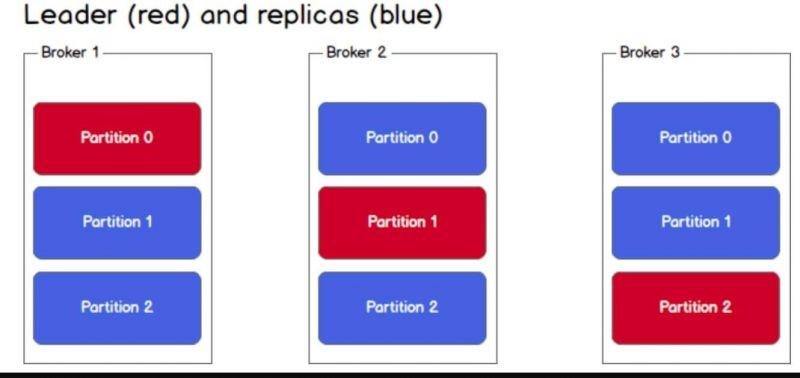
All write and read actions to a topic will have to go through the corresponding partition leader and the leader will coordinate to update new data to other replica parition. If the leader is broken, one of the replica partitions will take on the role of a new leader.
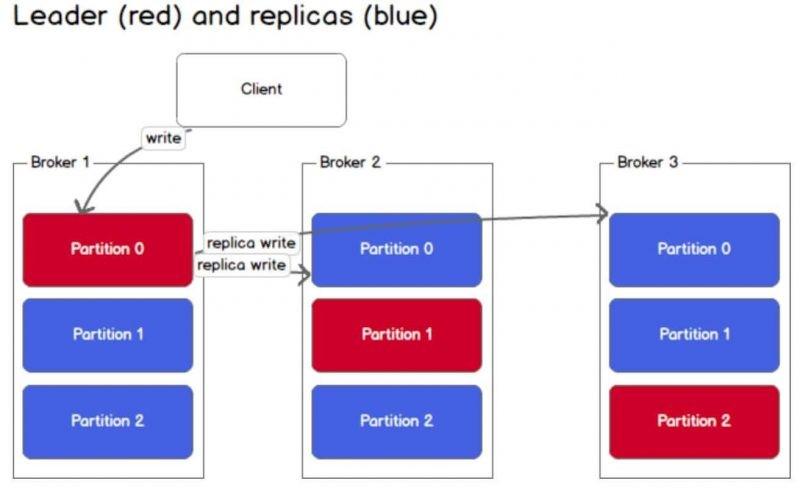
For a producer / consumer to write / read messages from a partition, they definitely need to know the leader. Kafka stores such information as metadata in Zookeeper.
Reference source
- https://www.tutorialspoint.com/apache_kafka/apache_kafka_cluster_architecture.htm
- https://blog.vu-review.com/kafka-la-gi.html
- https://data-flair.training/blogs/kafka-architecture/
- https://www.cloudkarafka.com/blog/2016-11-30-part1-kafka-for-beginners-what-is-apache-kafka.html
- https://www.facebook.com/notes/community-big-data-viet-nam/continuous-kafka-thong-qua-confluent-platform/884414712076055/